{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "lLMDGooqcWGg"
},
"source": [
"# Problem Set 0: Introduction to Python, Matrices and NumPy\n",
"\n",
"**Release Date:** 15 August 2023\n",
"\n",
"**Due Date:** 23:59, 26 August 2023"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gFWBI2aWcsOM"
},
"source": [
"# Overview\n",
"\n",
"Python is the most common language used for modern AI applications. Modern machine learning also often involves linear algebra. We will not be teaching either Python or linear algebra explictly in CS2109S. Instead, we have designed this problem set to help you to become familiar with Python and review (or learn) some fundamental matrix operations. We will also learn how to use some useful functions in NumPy, a Python package that allows us to easily manipulate multidimensional arrays (like vectors and matrices).\n",
"\n",
"This problem set will not be fully comprehensive. There will likely still be more things that you will need to learn on your own. However, this is a feature and not a bug. The high-level goal of CS2109S is to learn how to learn new things on your own! However, this problem set will hopefully be a helpful primer for your learning journey.\n",
"\n",
"Welcome to CS2109S!\n",
"\n",
"Required Files:\n",
"\n",
"* OxCGRT_2020.csv\n",
"* prepare_data.py\n",
"\n",
"Optional File:\n",
"* ps0.py\n",
"\n",
"**Honour Code**: Note that plagiarism will not be condoned! You may discuss with your classmates and check the internet for references, but you MUST NOT submit code/report that is copied directly from other sources!\n",
"\n",
"**IMPORTANT**: While it is possible to write and run Python code directly in Jupyter notebook, we recommend that you do this Problem set with an iDE using the `.py` file provided. An IDE will make debugging significantly easier. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3zYCsHsde_Dc"
},
"source": [
"# Part 1: Basic Python and Matrix Operations\n",
"We will begin this part of the homework by taking a look at Python’s basic features and syntax. Then, we shall put what we have learnt into practice by implementing several common matrix operations. You will never be required to implement matrix operations for real work. We are making you do this to give you some practice with Python. However, a good understanding of matrices and how their operations actually work will likely be useful in understanding the material to be covered in the later part of this module!\n",
"\n",
"**Note**: feel free to skip to Matrix Operations in Python if you already have a good grasp of Python."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "LNTITqxCfS8c"
},
"source": [
"## 1.0 Introduction to Python\n",
"In this section, we will look at the basics of Python. If you are keen on finding out more about it, do take a look at https://docs.python.org/3.9/tutorial/index.html."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "v1sxzgdefXjs"
},
"source": [
"### 1.0.1 Basic Data Types"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vD3FHQsMggMG"
},
"source": [
"*Number*\n",
"\n",
"Floats and integers in Python behave similarly to those in other programming languages."
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"id": "7stw_ROEdd1K"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2110\n",
"2108\n",
"4218\n",
"1054.5\n",
"1054\n",
"1\n"
]
}
],
"source": [
"x = 2109 # Declares and assigns a value to the variable x\n",
"print(x + 1) # Addition ; prints 2110\n",
"print(x - 1) # Subtraction ; prints 2108\n",
"print(x * 2) # Multiplication ; prints 4218\n",
"print(x / 2) # Floating point division ; prints 1054.5\n",
"print(x // 2) # Integer division ; prints 1054\n",
"print(x % 2) # Modulo division ; prints 1"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "T9k52oX1f6MN"
},
"source": [
"*Boolean*\n",
"\n",
"The Boolean operators are as follows:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"id": "aYakFamqfltm"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"False\n",
"True\n",
"False\n"
]
}
],
"source": [
"a = True # Assigns true to variable a\n",
"b = False # Assigns false to variable b\n",
"print(a and b) # Logical and; prints False\n",
"print(a or b) # Logical or; prints True\n",
"print(not a) # Logical negation ; prints False"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "chDjvRWvgDjk"
},
"source": [
"*Strings*\n",
"\n",
"Similar to numbers, strings in Python behave similarly to those in other programming languages. Note that in Python, single and double quotations can be used to indicate that a sequence of characters is a string. The following are both valid strings:"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"id": "wCyeFOzBgDDy"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello\n",
"world\n"
]
}
],
"source": [
"s1 = 'hello'\n",
"s2 = \"world\"\n",
"print(s1)\n",
"print(s2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NMC1anYogXfk"
},
"source": [
"For more information on the types of operations we can perform on strings in Python, please refer to https://docs.python.org/3.9/library/stdtypes.html#string-methods."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DodDX1vagkhu"
},
"source": [
"### 1.0.2 A Few Other Data Types\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6h4Cx3e0gt0X"
},
"source": [
"*Lists*\n",
"\n",
"One of the data structures which we will use is lists. Note that they behave more like dynamic arrays than linked lists in other programming languages. The following shows examples of common operations on lists in Python.\n"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"id": "XYgsMsS7gUhL"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3\n",
"3\n",
"4 foo\n",
"[None, None, None]\n"
]
}
],
"source": [
"arr = [1, 2, 3] # Creates a list\n",
"print(arr[2]) # Accesses the element at index 2 (0- indexed); prints 3\n",
"print(arr[-1]) # Accesses the element at the last index ; prints 3\n",
"arr[1] = 'foo' # Re - assigns the value at index 1 to 'foo'\n",
"arr.append(4) # Adds a new element 4 to the end of the list\n",
"x = arr.pop() # Removes and returns the last element\n",
"y = arr.pop(1) # Removes and returns the element at index 1\n",
"print(x, y) # Prints '4 foo'\n",
"arr = [ None ] * 3 # Creates the list [None, None, None]\n",
"print(arr)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qtU7hCzlhnqq"
},
"source": [
"Note that it is possible to access and assign a sublist in python by slicing. For example,"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"id": "QO2f7b54hETZ"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2, 3]\n",
"[3, 4, 5]\n",
"[1, 2, 3]\n",
"[1, 2, 5]\n"
]
}
],
"source": [
"arr = [1, 2, 3, 4, 5] # Creates a list\n",
"print(arr[1:3]) # Prints [2, 3]\n",
"print(arr[2:]) # Prints [3, 4, 5]\n",
"print(arr[:3]) # Prints [1, 2, 3]\n",
"arr[2:] = [5] \n",
"print(arr) # Prints [1, 2, 5]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Yf4NB01OhpJa"
},
"source": [
"To find out more about lists in Python, refer to https://docs.python.org/3.9/tutorial/datastructures.html#more-on-lists.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "L4c--tvKhpOP"
},
"source": [
"*Tuples*\n",
"\n",
"As you work with Python, you may encounter tuples. A tuple behaves like a list in some ways. However, unlike a list, it is immutable. You will unlikely be using tuples when you write code, but tuples are sometimes returned by some python functions. You can think of them as lists and use them like lists. Just don’t try to modify them."
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"id": "NzoAX57miDR_"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1 ... cool\n"
]
}
],
"source": [
"t = (1 , 'cool') # Declares a tuple containing two elements\n",
"print (t[0], t[1], sep=\" ... \") # Prints \"1 ... cool \""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "LrwA3lL1i9Dt"
},
"source": [
"### 1.0.3 Loops"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4shMhxbBjDU9"
},
"source": [
"*While Loops*"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"id": "epwhKYnWi5ua"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"01234"
]
}
],
"source": [
"i = 0\n",
"while (i < 5):\n",
" print(i, end=\"\")\n",
" i += 1"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oqGq0fY5jYRx"
},
"source": [
"Take note of the lack of braces used as compared to other programming languages. Instead, indentations are used to indicate the scope of a block of code.\n",
"\n",
"*Side note*: print in python automatically adds a space between arguments, and a newline character at the end. Adding the keywords sep = \"...\" replaces the space with 3 periods, and end = \"\" replaces the newline character with an empty string."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9SDs0Jjrjl2r"
},
"source": [
"*For Loops*"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"id": "RmjdPs0FjQ9p"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"01234"
]
}
],
"source": [
"for i in range(5):\n",
" print(i, end=\"\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "-trDyt8TjpN8"
},
"source": [
"Instead of the conventential (initialisation; test; update) used in other programming languages, python uses a library function `range` to iterate through elements. By default, using range with one parameter will iterate through values starting from 0 up to and not including the value in the parameter. For more freedom, the range function can be called with extra parameters as well:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"id": "yTJmES_ujlYk"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"234"
]
}
],
"source": [
"for i in range (2, 5):\n",
" print(i, end=\"\")"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"id": "Jdow039Cj1wB"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3579"
]
}
],
"source": [
"for i in range(3, 10, 2):\n",
" print(i, end=\"\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "limrwJVoj7Sf"
},
"source": [
"For more information about `range`, you may want to refer to: https://docs.python.org/3/library/stdtypes.html#range"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1t4qAfZxkR0L"
},
"source": [
"### 1.0.4 Functions"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "g6ZZIThGkTwr"
},
"source": [
"A function in Python with control flow looks something like this"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"id": "hNnmQNnUj5HO"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Zero here!\n",
"One here!\n",
"2\n",
"hello\n",
"3\n",
"hello\n"
]
}
],
"source": [
"def foo(x):\n",
" for i in range(4):\n",
" if i == 0:\n",
" print('Zero here!')\n",
" elif i == 1:\n",
" print('One here!')\n",
" else:\n",
" print(i)\n",
" print(x)\n",
"foo('hello')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "95ATQp3BknlI"
},
"source": [
"Recall that indentation in Python is important as it is used to indicate the scope of a block of code. Incorrect level of indentation can cause syntax errors and unintended behaviours, even errors. For instance, if we are to indent the last print statement in the previous code snippet, we will get a different result. The next code snippet illustrates this. Make sure you understand why this is so."
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"id": "YYze3lmKkjHQ"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Zero here!\n",
"hello\n",
"One here!\n",
"hello\n",
"2\n",
"hello\n",
"3\n",
"hello\n"
]
}
],
"source": [
"def foo(x):\n",
" for i in range(4):\n",
" if i == 0:\n",
" print('Zero here!')\n",
" elif i == 1:\n",
" print('One here!')\n",
" else:\n",
" print(i)\n",
" print(x) # Additional level of indentation\n",
"foo('hello')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r-2meP8gk0vo"
},
"source": [
"For more information about functions, you may want to refer to https://docs.python.org/3.9/tutorial/controlflow.html#defining-functions.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0Y8RMpHbk2m-"
},
"source": [
"### 1.0.5 Aliasing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "OxLQG0SSk7Ea"
},
"source": [
"When two variables refer to the same object in Python, aliasing occurs. We can check whether to variables are aliases of each other by using `is`.\n",
"\n",
"Note that if two variables a and b are aliases of each other, i.e. a `is` b returns `True`, a == b will return `True`. However, if a == b returns `True`, it does not mean that the variables are aliases of each other. For example,"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"id": "ogMC9R_Fkx3Q"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n",
"False\n",
"True\n",
"True\n"
]
}
],
"source": [
"a = [1, 2, 3]\n",
"b = [1, 2, 3]\n",
"\n",
"print(a == b) # True\n",
"print(a is b) # False\n",
"\n",
"c = a # Now , c points to the same object as a\n",
"print(a == c) # True\n",
"print(a is c) # True"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "GQ7OvFRWlc7_"
},
"source": [
"Think about what this means. When aliasing occurs, unintended side effects may surface. Consider the previous example. Suppose we want to modify c. We might do something like"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {
"id": "bfF3lsNqlcUI"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['hello', 2, 3]\n"
]
}
],
"source": [
"c[0] = 'hello'\n",
"print(a) # Prints ['hello', 2, 3]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Dl2X6vhql4-S"
},
"source": [
"To avoid aliasing then, we can use copy that is provided by Python. Returning to the previous example, if we want c to contain elements that are identical to a, except for the zeroth one, we can do"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"id": "OTjT9qfMllTg"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1, 2, 3]\n",
"['hello', 2, 3]\n"
]
}
],
"source": [
"a = [1, 2, 3]\n",
"c = a.copy()\n",
"c[0] = 'hello'\n",
"print(a) # Prints [1, 2, 3]\n",
"print(c) # Prints ['hello', 2, 3]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0XOXfFxbmNWi"
},
"source": [
"Note however that `copy` returns what is called a *shallow* copy, i.e. that the copy only done at the first level. To do a deep copy, we should recursively copy the nested lists. We can conveniently do this using use [copy.deepcopy]( https://docs.python.org/3.9/library/copy.html). In the case of a list of lists, simply doing copy may not work. Consider the following example to understand the difference between shallow copy and deep copy:\n"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"id": "M6S6hMvAmHO4"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Shallow copy\n",
"[[5, 2], [3, 4]]\n",
"[[5, 2], [3, 4]]\n",
"Deep copy\n",
"[[1, 2], [3, 4]]\n",
"[[5, 2], [3, 4]]\n"
]
}
],
"source": [
"import copy\n",
"\n",
"print('Shallow copy')\n",
"a = [[1, 2], [3, 4]]\n",
"b = a.copy() # Performs a shallow copy of variable a\n",
"b[0][0] = 5 # Modifies both a and b\n",
"print(a) # Prints [[5, 2], [3, 4]]\n",
"print(b) # Prints [[5, 2], [3, 4]]\n",
"\n",
"print('Deep copy')\n",
"x = [[1, 2], [3, 4]]\n",
"y = copy.deepcopy(x) # Performs a deep copy of variable x\n",
"y[0][0] = 5 # Modifies y only\n",
"print(x) # Prints [[1, 2], [3, 4]]\n",
"print(y) # Prints [[5, 2], [3, 4]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DQKm3UeGnVry"
},
"source": [
"### 1.0.6 Swapping Variables"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "VYs8aZyQnX6v"
},
"source": [
"Instead of swapping two elements with a temporary variable, as we do in other programming languages, it is possible to do something like this in Python."
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"id": "0tyZ-eG8nNtR"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2\n",
"1\n"
]
}
],
"source": [
"a = 1\n",
"b = 2\n",
"a, b = b, a\n",
"print(a) # Prints 2\n",
"print(b) # Prints 1"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Qb0XbrcHng_f"
},
"source": [
"### 1.0.7 Lambda Functions\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2z1eTBrtnith"
},
"source": [
"Lambda functions are anonymous functions. Here is an example of a lambda function in python:"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"id": "JxxJHznJncDj"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2109\n",
"2109\n"
]
}
],
"source": [
"def increment_by_one(x):\n",
" return x + 1\n",
"print(increment_by_one(2108)) # Prints 2109\n",
"print((lambda x : x + 1)(2108)) # Prints 2109"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "yIDa-K3JnzHv"
},
"source": [
"### 1.0.8 Map\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YokpZBBLn1LG"
},
"source": [
"Transforming a list of elements by applying a function on each element is a common operation. For example, we may want to increment each element in an array by 1. Perhaps, the first thing that comes to mind is to use a for-loop. However, in Python, we can use `map` instead. The following code snippet illustrates this.\n",
"\n",
"**Note**: As `map` is an iterator, we need to call `list` if we want the result to be returned as a list."
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"id": "LZIIf_OFnvDL"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n"
]
}
],
"source": [
"a = [1, 2, 3, 4]\n",
"b = []\n",
"for i in range(len(a)):\n",
" b.append(a[i] + 1)\n",
"\n",
"c = list(map(lambda x : x + 1, a)) # Equivalent to for loop above\n",
"print(b == c) # Prints True"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Sy5Wp04EoWoO"
},
"source": [
"In fact, we can pass in more than one list—or more generally, iterable—into `map`. The number of arguments that the function, which is passed into `map`, just has to match the number of lists—or more generally, iterables—passed into `map`. For instance,"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"id": "CAGwgRjioR9c"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['helloworld', 'byecat']\n"
]
}
],
"source": [
"a = [\"hello\", \"bye\"]\n",
"b = [\"world\", \"cat\"]\n",
"\n",
"c = list(map(lambda x, y: x + y, a, b))\n",
"print(c) # Prints ['helloworld', 'byecat']"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UxjKFV9yozO7"
},
"source": [
"### 1.0.9 Filter\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tfiGPKpwo1VG"
},
"source": [
"Another useful function is `filter`. Like what its name suggests, we can use it to filter a list—or more generally, an iterable—of elements. An example of how it works is as shown."
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"id": "Os-QeB-Fosks"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n"
]
}
],
"source": [
"a = [1, 2, 3, 4]\n",
"filtered_1 = []\n",
"for i in range(4):\n",
" if a[i] % 2 == 0:\n",
" filtered_1.append(a[i])\n",
"\n",
"filtered_2 = list(filter(lambda x : x % 2 == 0, a)) # Equivalent as for loop above\n",
"print(filtered_1 == filtered_2) # Prints True"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.0.10 Dictionary"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"One of the data structures which are commonly used is hash tables or hash maps. It is a data structure that implements associative arrays, i.e., a mapping from a certain key to a value.\n",
"\n",
"In Python, this data structure is called _dictionary_. Examples of how it works are given below."
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{}\n",
"{'foo': 'bar', 'one': 1}\n",
"bar\n",
"{'foo': 'cs2109s', 'two': 2}\n",
"True\n",
"False\n",
"{'foo': 'cs2109s', 'two': 2, 1: 'one', 2: 'two'}\n"
]
}
],
"source": [
"# Initialize an empty dictionary\n",
"a = {}\n",
"# or\n",
"a = dict()\n",
"\n",
"print(a) # Prints {}\n",
"\n",
"# We can also initialize a dictionary with some items\n",
"a = {'foo': 'bar', 'one': 1}\n",
"\n",
"print(a) # Prints a as initialized\n",
"\n",
"print(a['foo']) # Prints \"bar\"\n",
"\n",
"a['two'] = 2 # Adds a new key \"two\" with value 2\n",
"a['foo'] = 'cs2109s' # Updates the value of key \"foo\" with \"cs2109s\"\n",
"del a['one'] # Deletes the key \"one\"\n",
"\n",
"print(a) # Prints the updated a\n",
"\n",
"print('two' in a) # True\n",
"print('three' in a) # False\n",
"\n",
"b = {1: 'one', 2: 'two'} # Creates a new dictionary\n",
"\n",
"c = {**a, **b} # Merges dictionaries a and b\n",
"print(c)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Hashable Objects\n",
"\n",
"Not all objects can be used as a key. Only objects whose hash values can be computed are useable for keys. We call these objects hashable objects. Some commonly used keys are strings, numbers, and tuples of strings and numbers. In contrast, a list is not hashable and therefore can not be used as keys. In general, immutable objects are usually hashable and mutable objects are usually unhashable."
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'test': 1}\n",
"{'test': 1, 0: 1}\n",
"{'test': 1, 0: 1, ('test', 0): 1}\n",
"unhashable type: 'list'\n"
]
}
],
"source": [
"try:\n",
" a = {}\n",
" a['test'] = 1 # String: OK\n",
" print(a)\n",
" \n",
" a[0] = 1 # Number: OK\n",
" print(a)\n",
" \n",
" a[('test', 0)] = 1 # Tuple of string and number: OK\n",
" print(a)\n",
" \n",
" a[['test', 0]] = 1 # List: FAIL\n",
" print(a)\n",
"except Exception as e:\n",
" print(e)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.0.11 Set"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A set is a collection of unique data. That is, elements of a set cannot be duplicate. Similar to a dictionary keys, the elements of a set must be hashable."
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"set()\n",
"{0, 1, 2}\n",
"{0, 1, 2, 3}\n",
"{1, 2, 3}\n",
"True\n",
"False\n",
"{3, 4, 5}\n",
"{3}\n",
"{3}\n",
"{1, 2, 3, 4, 5}\n",
"{1, 2, 3, 4, 5}\n",
"{1, 2, 4, 5}\n",
"{1, 2, 4, 5}\n",
"{1, 2}\n",
"{4, 5}\n",
"True\n",
"False\n"
]
}
],
"source": [
"# Initialize an empty set\n",
"a = set()\n",
"\n",
"print(a) # Prints set()\n",
"\n",
"# Initialize a set with some elements\n",
"a = set([0, 1, 2])\n",
"\n",
"print(a) # Prints {0, 1, 2}\n",
"\n",
"a.add(3) # Adds 3\n",
"\n",
"print(a) # Prints {0, 1, 2, 3}\n",
"\n",
"a.remove(0) # Remove 0\n",
"\n",
"print(a) # Prints {1, 2, 3}\n",
"\n",
"print(1 in a) # True\n",
"print(4 in a) # False\n",
"\n",
"a2 = set([3, 4, 5])\n",
"\n",
"print(a2)\n",
"\n",
"print(a.intersection(a2)) # Intersection of two sets\n",
"print(a & a2) # Intersection of two sets\n",
"print(a.union(a2)) # Union of two sets\n",
"print(a | a2) # Union of two sets\n",
"print(a.symmetric_difference(a2)) # Symmetric difference of two sets\n",
"print(a ^ a2) # Symmetric difference of two sets\n",
"print(a - a2) # Difference of two sets\n",
"print(a2 - a) # Difference of two sets\n",
"\n",
"print(a == set([3, 2, 1])) # True\n",
"print(a == set([3, 2, 1, 0])) # False"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nLSj1KTtpYAr"
},
"source": [
"## 1.1 Matrix Operators in Python"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "US7_thWVpfcN"
},
"source": [
"Now, let us do some programming in Python!\n",
"\n",
"**IMPORTANT**: For the tasks in part 1 of this problem, you need to ensure that none of the matrix operations which you implement modify the input matrix (or matrices). In addition, you are not allowed to import any packages that have not already been imported (because the whole point is for you to learn Python by implementing matrix operations)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SkU-Uy7Tpfkh"
},
"source": [
"### Matrix\n",
"\n",
"Recall that each matrix has a dimension $n \\times m$, where $n$ is the number of rows and $m$ is the number of columns in the matrix. For instance, the following matrix $X$ has a dimension of 2 × 3.\n",
" \n",
"$$\n",
"X = \n",
"\\begin{bmatrix}\n",
"5 & 7 & 9 \\\\\n",
"1 & 4 & 3\n",
"\\end{bmatrix}\n",
"$$\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_ed3mXFkqEVh"
},
"source": [
"In addition, we can refer to each entry in the matrix by indexing it using the row and column where it is located. For example, the entry with value ’3’ in $X$ is the (1, 2) entry while the entry with value ’7’ is the (0, 1) entry. More generally, the entry in the $i$-th row and $j$-th column in a matrix $A$ is the ($i$, $j$) entry, and its value is denoted by $A_{i,j}$.\n",
"\n",
"**Note**: to be consistent with indexing in Python, we will be using zero-based index.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_eOX5GtkqnBV"
},
"source": [
"Now, this begs the question of how a matrix in Python should be represented. For\n",
"simplicity, we shall do it with a list of lists. We can define matrix *X* in two ways:"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"id": "3XoRJChhpJMa"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Method 1\n",
"[[5, 7, 9], [1, 4, 3]]\n",
"Method 2\n",
"[[5, 7, 9], [1, 4, 3]]\n"
]
}
],
"source": [
"print('Method 1')\n",
"X = [None] * 2\n",
"X[0] = [5, 7, 9]\n",
"X[1] = [1, 4, 3]\n",
"print(X)\n",
"\n",
"print('Method 2')\n",
"X = [[5, 7, 9],\n",
" [1, 4, 3]]\n",
"print(X)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9l1gJmz6q8EA"
},
"source": [
"In the following tasks, you **may assume** that the input matrices are\n",
"* list of lists\n",
"* the number of elements in each of the ’inner’ lists can be assumed to be the same (because the number of columns in a matrix is the same for each row)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8ODILekjrCeH"
},
"source": [
"### Task 1.1 Scalar Multiplication"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WJFIy6IBrG5C"
},
"source": [
"Our first task is to implement `mult_scalar`. This function takes in two arguments, a matrix $A$ and a scalar $c$, and returns a new matrix $A$ obtained by multiplying each element by $c$.\n",
"\n",
"Scalar multiplication of an $n \\times m$ matrix $A$ by $c$ is done by multiplying $c$ to each *Ai,j*, i.e.\n",
"\n",
"\\begin{equation}\n",
" cA =\n",
" \\begin{bmatrix}\n",
" cA_{0, 0} & cA_{0, 1} & ... & cA_{0, m-1}\\\\\n",
" cA_{1, 0} & cA_{1, 1} & ... & cA_{1, m-1}\\\\\n",
" \\vdots & \\vdots & \\ddots & \\vdots\\\\\n",
" cA_{n-1, 0} & cA_{n-1, 1} & ... & cA_{n-1, m-1}\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"For example if $c = 2$, then\n",
"\\begin{equation*}\n",
" 2X = \n",
" \\begin{bmatrix}\n",
" 10 & 14 & 18\\\\\n",
" 2 & 8 & 6\n",
" \\end{bmatrix}\n",
"\\end{equation*}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*IMPORTANT NOTE:* While you can write and run your code directly in this Jupyter notebook, it is difficult to debug your code directly here. We would recommend that you code using an IDE with the `.py` file provided. **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"id": "Aa_BHke5q5sR"
},
"outputs": [],
"source": [
"def mult_scalar(A, c):\n",
" \"\"\"\n",
" Returns a new matrix created by multiplying elements of matrix A by a scalar c.\n",
" Note\n",
" ----\n",
" Do not use numpy for this question.\n",
" \"\"\"\n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" return [[i * c for i in row] for row in A]"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[10, 14, 18], [2, 8, 6]]\n"
]
}
],
"source": [
"# Test cases for Task 1.1\n",
"A = [[5, 7, 9], [1, 4, 3]]\n",
"A_copy = copy.deepcopy(A)\n",
"\n",
"actual = mult_scalar(A_copy, 2)\n",
"expected = [[10, 14, 18], [2, 8, 6]]\n",
"assert(A == A_copy) # check for aliasing\n",
"print(actual)\n",
"assert(actual == expected)\n",
"\n",
"\n",
"A2 = [[6, 5, 5], [8, 6, 0], [1, 5, 8]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"\n",
"actual2 = mult_scalar(A2_copy, 5)\n",
"expected2 = [[30, 25, 25], [40, 30, 0], [5, 25, 40]]\n",
"assert(A2 == A2_copy) # check for aliasing\n",
"assert(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FL7S2pHhrfWK"
},
"source": [
"### Task 1.2 Matrix Addition\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ncvdVPbvrike"
},
"source": [
"Our next task is to implement `add_matrices`. This function takes in two arguments, a matrix $A$ and a matrix $B$, and returns a new matrix that is the result of adding $B$ to $A$.\n",
"\n",
"For this operation to be valid, $A$ and $B$ must have the same dimensions. If this is the case, then\n",
"\\begin{equation}\n",
" A + B = \n",
" \\begin{bmatrix}\n",
" A_{0, 0} + B_{0, 0} & A_{0, 1} + B_{0, 1} & ... & A_{0, m-1} + B_{0, m-1}\\\\\n",
" A_{1, 0} + B_{1, 0} & A_{1, 1} + B_{1, 1} & ... & A_{1, m-1} + B_{1, m-1}\\\\\n",
" \\vdots & \\vdots & \\ddots & \\vdots\\\\\n",
" A_{n-1, 0} + B_{n-1, 0} & A_{n-1, 1} + B_{n-1, 1} & ... & A_{n-1, m-1} + B_{n-1, m-1}\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"To exemplify this, consider $X$ and $Y$ below.\n",
"\n",
"\\begin{equation}\n",
" X = \n",
" \\begin{bmatrix}\n",
" 5 & 7 & 9\\\\\n",
" 1 & 4 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"\\begin{equation}\n",
" Y = \n",
" \\begin{bmatrix}\n",
" 2 & 3 & 4\\\\\n",
" 5 & 6 & 7\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Then, we have\n",
"\\begin{equation*}\n",
" Y + X = \n",
" \\begin{bmatrix}\n",
" 2 + 5 & 3 + 7 & 4 + 9 \\\\\n",
" 5 + 1 & 6 + 4 & 7 + 3\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Observe that because addition of scalar values is commutative (i.e. x + y = y + x), we always have $A + B = B + A$. However, note that, as we shall see later, not all matrix operations are commutative.\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {
"id": "gVdOsgvhrWcT"
},
"outputs": [],
"source": [
"def add_matrices(A, B):\n",
" \"\"\"\n",
" Returns a new matrix that is the result of adding matrix B to matrix A.\n",
" Note\n",
" ----\n",
" Do not use numpy for this question.\n",
" \"\"\"\n",
" if len(A) != len(B) or len(A[0]) != len(B[0]):\n",
" raise Exception('A and B cannot be added as they have incompatible dimensions!')\n",
" result = [[0] * len(A[0]) for _ in A]\n",
" for i in range(len(A)):\n",
" for j in range(len(A[0])):\n",
" result[i][j] = A[i][j] + B[i][j]\n",
" return result\n",
" "
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[7, 10, 13], [6, 10, 10]]\n"
]
}
],
"source": [
"# Test case for Task 1.2\n",
"A = [[5, 7, 9], [1, 4, 3]]\n",
"B = [[2, 3, 4], [5, 6, 7]]\n",
"A_copy = copy.deepcopy(A)\n",
"B_copy = copy.deepcopy(B)\n",
"\n",
"actual = add_matrices(A_copy, B_copy)\n",
"print(actual)\n",
"expected = [[7, 10, 13], [6, 10, 10]]\n",
"assert(A == A_copy) # check for aliasing\n",
"assert(B == B_copy) # check for aliasing\n",
"assert(actual == expected)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sYRR2xWkr0pF"
},
"source": [
"### Task 1.3 Transpose a Matrix"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vzpIHNX7r7Dh"
},
"source": [
"Our third task is to implement `transpose_matrix`. This function takes in one argument, a matrix $A$, and returns a new matrix that is the transpose of $A$. \n",
"\n",
"Less formally, the transpose of a matrix $A$ can be found by changing the rows in the matrix to columns, and this transpose is denoted by $A^T$. For example, \n",
"for matrix X\n",
"\n",
"\\begin{equation}\n",
" X = \n",
" \\begin{bmatrix}\n",
" 5 & 7 & 9\\\\\n",
" 1 & 4 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"\n",
"then the transpose of matrix $X$ is given by\n",
"\n",
"\\begin{equation*}\n",
" X^T = \n",
" \\begin{bmatrix}\n",
" 5 & 1\\\\\n",
" 7 & 4\\\\\n",
" 9 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"More formally, suppose $\\mathbf{r_i}$ represents the i-th row in an $n \\times m$ matrix $A$, i.e.\n",
"\\begin{equation}\n",
" A = \n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0}\\\\\n",
" \\mathbf{r_1}\\\\\n",
" \\vdots\\\\\n",
" \\mathbf{r_{n-2}}\\\\\n",
" \\mathbf{r_{n-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Then, $A^T$ is given by\n",
"\\begin{equation}\n",
" A^T = \n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0} & \\mathbf{r_1} & ... & \\mathbf{r_{n-2}} & \\mathbf{r_{n-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Note that this means that $A^T$ has dimension $m \\times n$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our third task is to implement `transpose_matrix`. This function takes in one argument, a matrix $A$, and transposes $A$. \n",
"\n",
"Less formally, the transpose of a matrix $A$ can be found by changing the rows in the matrix to columns, and this transpose is denoted by $A^T$. For example, \n",
"for matrix X\n",
"\n",
"\\begin{equation}\n",
" X = \n",
" \\begin{bmatrix}\n",
" 5 & 7 & 9\\\\\n",
" 1 & 4 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"\n",
"then the transpose of matrix $X$ is given by\n",
"\n",
"\\begin{equation*}\n",
" X^T = \n",
" \\begin{bmatrix}\n",
" 5 & 1\\\\\n",
" 7 & 4\\\\\n",
" 9 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"More formally, suppose $\\mathbf{r_i}$ represents the i-th row in an $n \\times m$ matrix $A$, i.e.\n",
"\\begin{equation}\n",
" A = \n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0}\\\\\n",
" \\mathbf{r_1}\\\\\n",
" \\vdots\\\\\n",
" \\mathbf{r_{n-2}}\\\\\n",
" \\mathbf{r_{n-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Then, $A^T$ is given by\n",
"\\begin{equation}\n",
" A^T = \n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0} & \\mathbf{r_1} & ... & \\mathbf{r_{n-2}} & \\mathbf{r_{n-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Note that this means that $A^T$ has dimension $m \\times n$.\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {
"id": "K1OahnevrtIV"
},
"outputs": [],
"source": [
"def transpose_matrix(A):\n",
" \"\"\"\n",
" Returns a new matrix that is the transpose of matrix A.\n",
" Note\n",
" ----\n",
" Do not use numpy for this question.\n",
" \"\"\"\n",
" # return list([list(a) for a in zip(*A)])\n",
" rows = len(A)\n",
" cols = len(A[0])\n",
" result = [[0] * rows for _ in range(cols)]\n",
" for i in range(cols):\n",
" for j in range(rows):\n",
" result[i][j] = A[j][i]\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[5, 1], [7, 4], [9, 3]]\n"
]
}
],
"source": [
"# Test case for Task 1.3\n",
"A = [[5, 7, 9], [1, 4, 3]]\n",
"A_copy = copy.deepcopy(A)\n",
"\n",
"actual = transpose_matrix(A_copy)\n",
"print(actual)\n",
"expected = [[5, 1], [7, 4], [9, 3]]\n",
"assert(A == A_copy)\n",
"assert(actual == expected)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "umaW01qxz3RF"
},
"source": [
"### Vector\n",
"\n",
"A vector is an $n \\times 1$ matrix. One mathematical operation that is defined for vectors of the same dimension is the \\emph{dot product}. Suppose we have\n",
"$\\mathbf{p} = \n",
" \\begin{bmatrix}\n",
" 3 & 2 & 3\\\\\n",
" \\end{bmatrix}^{T}\n",
"$ and\n",
"$\\mathbf{q} = \n",
" \\begin{bmatrix}\n",
" 4 & 5 & 6\\\\\n",
" \\end{bmatrix}^{T}\n",
"$. Then, the dot product of $\\mathbf{p}$ and $\\mathbf{q}$ is denoted by $\\mathbf{p} \\cdot \\mathbf{q}$, and is given by\n",
"\n",
"\\begin{equation*}\n",
"\\mathbf{p} \\cdot \\mathbf{q} = 3 \\times 4 + 2 \\times 5 + 3 \\times 6 = 40\n",
"\\end{equation*}\n",
"\n",
"More generally, for two vectors $\\mathbf{u}$ and $\\mathbf{v}$, where both have a dimension of $n \\times 1$,\n",
"\\begin{equation}\n",
" \\mathbf{u} \\cdot \\mathbf{v} = \\sum_{i = 0}^{n - 1} u_{i, 1} v_{i, 1}\n",
"\\end{equation}\n",
"\n",
"Observe that this operation gives us a scalar value, i.e. $\\mathbf{u} \\cdot \\mathbf{v} \\in \\mathbb{R}$, not a matrix. \n",
"\n",
"We shall see how dot product relates to \\emph{matrix multiplication}, which we are going to implement in the next task."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "y9xDe72euNh3"
},
"source": [
"### Task 1.4 Multiply Two Matrices"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JqWvt6u6uTuq"
},
"source": [
"Our fourth task is to implement `mult_matrix`. This function takes in two arguments, a matrix $A$ and a matrix $B$, and returns a new matrix that is the result of multiplying them.\n",
"\n",
"For this operation to be valid, the number of columns $m$ in $A$ must be equal to the number of rows $n'$ in $B$, i.e. $m = n'$. If this is the case, then the value of each entry $(i, j)$ in $A \\times B$, or $AB$, is given by the dot product of the transpose of the $i$-th row in $A$ and the $j$-th column in $B$.\n",
"\n",
"For example, to compute $XY^T$, where $X$ and $Y$ are as defined in Task 1.2, respectively,\n",
"\n",
"\n",
"\n",
"More formally, suppose that $A$ has dimension $n \\times m$ and $B$ has dimension $n' \\times m'$, where $m = n'$. Moreover, the $i$-th row in $A$ is denoted by $\\mathbf{r_i}$ and the $j$-th column in $B$ is denoted by $\\mathbf{c_j}$ such that\n",
"\n",
"\\begin{equation*}\n",
" B = \n",
" \\begin{bmatrix}\n",
" \\mathbf{c_0} & \\mathbf{c_1} & ... & \\mathbf{c_{m'-2}} & \\mathbf{c_{m'-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Then,\n",
"\\begin{equation}\n",
" AB =\n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0}^T \\cdot \\mathbf{c_0} & \\mathbf{r_0}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_0}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\mathbf{r_1}^T \\cdot \\mathbf{c_0} & \\mathbf{r_1}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_1}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\vdots & \\vdots & \\ddots & \\vdots\\\\\n",
" \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_0} & \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Food for thought: what is the dimension of $AB$? As a follow-up question, what does this tell us about the commutativity (or the lack of it) of matrix multiplication?\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {
"id": "3wUd3W6SrxiB"
},
"outputs": [],
"source": [
"def dot_prod(A, B):\n",
" if len(A) != len(B):\n",
" raise Exception('A and B cannot be multiplied as they have incompatible dimensions!')\n",
" return sum([A[i] * B[i] for i in range(len(A))])\n",
"\n",
"def mult_matrices(A, B):\n",
" \"\"\"\n",
" Multiplies matrix A by matrix B, giving AB.\n",
" Note\n",
" ----\n",
" Do not use numpy for this question.\n",
" \"\"\"\n",
" if len(A[0]) != len(B):\n",
" raise Exception('Incompatible dimensions for matrix multiplication of A and B')\n",
" res_rows = len(A)\n",
" res_cols = len(B[0])\n",
" result = [[0] * res_cols for _ in range(res_rows)]\n",
" trans_B = transpose_matrix(B)\n",
" for i in range(res_rows):\n",
" for j in range(res_cols):\n",
" result[i][j] = dot_prod(A[i], trans_B[j])\n",
" return result\n"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [],
"source": [
"# Test Cases for Task 1.4\n",
"A = [[5, 7, 9], [1, 4, 3]]\n",
"B = [[2, 5], [3, 6], [4, 7]]\n",
"A_copy = copy.deepcopy(A)\n",
"B_copy = copy.deepcopy(B)\n",
"\n",
"actual = mult_matrices(A, B)\n",
"expected = [[67, 130], [26, 50]]\n",
"assert(A == A_copy and B == B_copy)\n",
"assert(actual == expected)\n",
"\n",
"A2 = [[-13, -10], [-24, 14]]\n",
"B2 = [[1, 0], [0, 1]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"B2_copy = copy.deepcopy(B2)\n",
"\n",
"actual2 = mult_matrices(A2, B2)\n",
"expected2 = [[-13, -10], [-24, 14]]\n",
"assert(A2 == A2_copy and B2 == B2_copy)\n",
"assert(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uMfIOl_TvSuT"
},
"source": [
"### Task 1.5 Inverse of a Matrix"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0xaIDHhz1-x9"
},
"source": [
"This is the last task for this part of the homework. In this task, we are supposed to implement `invert_matrix`. This function takes in one argument, a matrix $A$, and tries to find the inverse of $A$. Yes, we said 'tries'.\n",
"\n",
"For the inverse of an $n \\times m$ matrix $A$ to exist, $A$ has to be a **square matrix**, i.e. $n = m$. Moreover, $A$ has to satisfy some [properties](https://en.wikipedia.org/wiki/Invertible_matrix) if you are interested in the technicalities of it. However, these are not required to complete this task. Therefore, it is not always possible to find the inverse of a matrix.\n",
"\n",
"Suppose the inverse of $A$ exists, then it is denoted by $A^{-1}$ and is such that\n",
"\\begin{equation}\n",
" AA^{-1} = I = A^{-1}A\n",
"\\end{equation}\n",
"where $I$ is the identity matrix. In other words, the dimension of $I$ depends on the context, e.g. if an invertible matrix $Q$ has a dimension of $2 \\times 2$, then $\n",
"QQ^{-1} = I =\n",
"\\begin{bmatrix}\n",
"1 & 0\\\\\n",
"0 & 1\n",
"\\end{bmatrix}\n",
"$ \n",
"with dimension $n \\times n$, diagonal entries that are all 1s, and off-diagonal entries that are all 0s, i.e.\n",
"\\begin{equation}\n",
" I_{i, j} =\n",
" \\begin{cases}\n",
" 1 & \\text{if $i = j$}\\\\\n",
" 0 & \\text{otherwise}\n",
" \\end{cases} \n",
"\\end{equation}\n",
"\n",
"For example, if we have\n",
"\\begin{equation*}\n",
" P = \n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & -4 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"then\n",
"\\begin{equation*}\n",
" P^{-1} = \n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & 4 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"We can check that this is true by computing $PP^{-1}$ and $P^{-1}P$. If the results evaluate to \n",
"$\n",
"\\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & 0 & 1\n",
"\\end{bmatrix}\n",
"$, then $P^{-1}$ is correctly computed.\n",
"\n",
"Quick question: what is the inverse of $P^{-1}$? In fact, more generally, given any *invertible matrix* $X$, i.e. $X^{-1}$ exists, what is the inverse of $X^{-1}$?\n",
"\n",
"The description of **our algorithm for finding the inverse of a matrix is as follows**.\n",
"\n",
"Given any matrix $A$, in order to attempt finding $A^{-1}$, we need to check whether $A$ is a square matrix. If it isn't, we should return False to indicate that it is not possible; otherwise, we will construct an adjacency matrix as shown below.\n",
"\n",
"\\begin{equation}\n",
" \\begin{bmatrix}\n",
" A & I\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Note that here, the adjacency matrix is of dimension $n \\times 2n$. Since both $A$ and $I$ have a dimension of $n \\times n$, placing their entries side-by-side will give $2n$ columns.\n",
"\n",
"For instance, suppose we have\n",
"\n",
"\\begin{equation*}\n",
" Z =\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2\\\\\n",
" 0 & 0 & 1\\\\\n",
" 1 & 5 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Then, the adjacency matrix is given by\n",
"\\begin{equation*}\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 1 & 5 & 3 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Next, for each $i$ th row in the augmented matrix, do the following\n",
"\n",
"1. Find a row $k$, where $i \\leq k \\leq (n - 1)$, that has a non-zero-valued entry in its $i$ th column, and swap it with the $i$ th row. If no such row exists, return False. The matrix is not invertible.\n",
"2. Multiply the new $i$ th row by a scalar such that the value in the $i$ th column becomes 1.\n",
"3. Add multiples of the new $i$ th row to all other rows such that the value in their $i$ th column becomes 0.\n",
"\n",
"Finally, get the last $n$ columns that is found in the resulting adjacency matrix. These columns form $A^{-1}$, i.e. if $\\mathbf{c_i}$ denotes the $i$ th column in the adjacency matrix, then\n",
"\\begin{equation}\n",
" A^{-1} =\n",
" \\begin{bmatrix}\n",
" \\mathbf{c_n} & \\mathbf{c_{n + 1}} & ... & \\mathbf{c_{2n - 1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Let us run through this algorithm to find $Z^{-1}$.\n",
"1. We have the adjacency matrix \n",
"$\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 1 & 5 & 3 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
"$\n",
" We shall swap the 2nd row with the 0th row, giving\n",
" $\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" \\end{bmatrix}\n",
" $\n",
"2. Since the value of $(0, 0)$ entry is 1, we don't need to multiply the 0th row by any scalar. Moreover, we do not need to add multiples of this row to the other rows because the value of the entry in the 0th column of the other rows are all 0s.\n",
"3. Moving on to $i = 1$, we see that we need to swap the last row with the $1$st row, giving \n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"4. Since the value of the $(1, 1)$ entry is 3, we need to divide the 1st row by $3$, giving\n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 1 & \\frac{2}{3} & \\frac{1}{3} & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"5. Given that the value of the $(0, 1)$ entry is 5, not 0, we need to add $-5 \\times \\mathbf{a_1}$, where $\\mathbf{a_1}$ represents the 1st row in the current adjacency matrix, to the 0th row. This leaves us with\n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 0 & -\\frac{1}{3} & -\\frac{5}{3} & 0 & 1\\\\\n",
" 0 & 1 & \\frac{2}{3} & \\frac{1}{3} & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"6. Now, $i = 2$. Observe that there are no other rows that can be swapped with the last row, since in this case substituting $i = 2$, we have $2 \\leq k \\leq 2 \\implies k = 2$. Moreover, we don't need to multiply the 2nd row by a scalar since the value in its last column is 1.\n",
"7. To get 0s in the last column of the other rows, we need to add $\\frac{1}{3} \\times \\mathbf{a_2}$ and $-\\frac{2}{3} \\times \\mathbf{a_2}$, where $\\mathbf{a_2}$ represents the last row in the adjacency matrix shown in step 6, to the 0th and 1st row, respectively. The result is \n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0 & -\\frac{5}{3} & \\frac{1}{3} & 1\\\\\n",
" 0 & 1 & 0 & \\frac{1}{3} & -\\frac{2}{3} & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"8. Finally, we can get $Z^{-1}$ by taking the last 3 columns.\n",
"\\begin{equation}\n",
" Z^{-1} = \n",
" \\begin{bmatrix}\n",
" -\\frac{5}{3} & \\frac{1}{3} & 1\\\\\n",
" \\frac{1}{3} & -\\frac{2}{3} & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Implement the function `invert_matrix` that takes in a matrix $A$ and returns the inverse matrix. If $A$ is not invertible, `invert_matrix` should return `False`.\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {
"id": "m1XBH6qwrytj"
},
"outputs": [],
"source": [
"def invert_matrix(A):\n",
" \"\"\"\n",
" Returns the inverse of matrix A, if it exists; otherwise, returns False\n",
" \"\"\"\n",
" if len(A[0]) != len(A):\n",
" return False\n",
" A_len = len(A)\n",
" result = copy.deepcopy(A)\n",
" # Step 0\n",
" for i in range(A_len):\n",
" result[i].extend([0] * A_len)\n",
" result[i][i + A_len] = 1\n",
" result = [[float(i) for i in row] for row in result]\n",
" # Step 1\n",
" for i in range(A_len):\n",
" # Step 1\n",
" for k in range(i, A_len):\n",
" if result[k][i] != 0:\n",
" break\n",
" if result[k][i] == 0:\n",
" return False\n",
" result[i], result[k] = result[k], result[i]\n",
" # Step 2\n",
" scalar = 1 / result[i][i]\n",
" result[i] = [scalar * x for x in result[i]]\n",
" # Step 3: Add multiples of the new ith row to all other rows such that the value in their ith column becomes 0\n",
" for k in range(A_len):\n",
" if k == i:\n",
" continue\n",
" scalar = -result[k][i]\n",
" result[k] = [result[k][j] + scalar * result[i][j] for j in range(2 * A_len)]\n",
" \n",
" for i in range(A_len):\n",
" result[i] = result[i][A_len:]\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": 39,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 1.5\n",
"A = [[1, 0 ,0], [0, 1, 0], [0, -4, 1]]\n",
"A_copy = copy.deepcopy(A)\n",
"\n",
"actual = invert_matrix(A)\n",
"expected = [[1, 0 ,0], [0, 1, 0], [0, 4, 1]]\n",
"assert(A == A_copy)\n",
"for i in range(len(A)):\n",
" for j in range(len(A[0])):\n",
" assert(round(actual[i][j], 11) == round(expected[i][j], 11))\n",
" \n",
" \n",
"A2 = [[0, 3, 2], [0, 0, 1], [1, 5, 3]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"\n",
"actual2 = invert_matrix(A2)\n",
"expected2 = [[-5/3, 1/3 ,1], [1/3, -2/3, 0], [0, 1, 0]]\n",
"assert(A2 == A2_copy)\n",
"for i in range(len(A2)):\n",
" for j in range(len(A2[0])):\n",
" assert(round(actual2[i][j], 11) == round(expected2[i][j], 11))\n",
" \n",
" \n",
"A3 = [[1, 0, 0], [0, 1, 0], [0, 0, 0]] # non-invertible matrix\n",
"actual3 = invert_matrix(A3)\n",
"expected3 = False\n",
"assert actual3 == expected3"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "J4pQSFqk5pi6"
},
"source": [
"# Part 2: Introduction to NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "v7NPTROk6Dp9"
},
"source": [
"Now that we have a better grasp of Python, let us take a look at NumPy, a commonly used package for multidimensional array manipulation! This will come in handy when we work with certain machine learning models later in the semester. Besides, in machine learning problems, large amount of data is usually present, necessitating approaches that make manipulating them easy and fast; and one such approach is to represent our data as multidimensional arrays before manipulating them.\n",
"\n",
"The tasks in this section are designed to give us the opportunity to apply what we are about to learn about NumPy to analyse [COVID-19 data](https://github.com/OxCGRT/covid-policy-tracker)."
]
},
{
"cell_type": "code",
"execution_count": 40,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Invert array without NumPy takes 0.24375009536743164s\n",
"Invert array with NumPy takes 0.0015101432800292969s\n"
]
}
],
"source": [
"import random\n",
"import time\n",
"\n",
"import numpy as np\n",
"\n",
"random.seed(2109)\n",
"A = [[random.random() for j in range(100)] for i in range(100)] # 100 x 100\n",
"start = time.time()\n",
"_ = invert_matrix(A)\n",
"end = time.time()\n",
"print(f'Invert array without NumPy takes {end - start}s')\n",
"\n",
"A_numpy = np.array(A)\n",
"start = time.time()\n",
"_ = np.linalg.inv(A)\n",
"end = time.time()\n",
"print(f'Invert array with NumPy takes {end - start}s')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note that **each task is independent**. In other words, even if you are stuck at a particular question, it is still possible to get full marks for the later questions.\n",
"\n",
"**IMPORTANT**: It is critical that we realise that the underlying implementation of the operations available in NumPy are often optimised for performance. As a result, using these operations, as opposed to iterative approaches, to manipulate elements in the array will often lead to more performant code. This, coupled with the fact that we want to practise using NumPy in this part of the homework, means that **your implementation in the following tasks should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops**. Instead, please work with the operations available in NumPy. \n",
"\n",
"You are allowed to use any [mathematical functions](https://numpy.org/doc/stable/reference/routines.math.html), but this **does not mean that you are allowed to use any NumPy functions** (there are NumPy functions that aren't mathematical functions). For example,[ np.vectorize ](https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html) is not allowed since it is iterative. Please refer to the forum post \"List of allowed numpy functions for assignments\" under \"Homework\" for a (non-exhaustive) list of functions that are considered non-iterative for PS0 and for the CS2109S course. If you are in doubt about an unlisted function, please ask in the forum. **Solutions that violate this will be heavily penalised**."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "z0uLebHS7W6u"
},
"source": [
"## NumPy Basics"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "yVL9SBwa7Y00"
},
"source": [
"### Import NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "R9eik6gP7c9r"
},
"source": [
"In order to use NumPy, we need to import it. This can be done by"
]
},
{
"cell_type": "code",
"execution_count": 41,
"metadata": {
"id": "GGPjViIWry89"
},
"outputs": [],
"source": [
"import numpy\n",
"a = numpy.arange(5) # Returns a NumPy array [0, 1, 2, 3, 4]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dA4YI8LT7kCB"
},
"source": [
"However, it is customary to use the shorthand np instead. Therefore, we will do"
]
},
{
"cell_type": "code",
"execution_count": 42,
"metadata": {
"id": "V5P8ESNy7lye"
},
"outputs": [],
"source": [
"import numpy as np\n",
"a = np.arange(5) # Note that here we use `np` instead of `numpy`"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UQaoJky47t6s"
},
"source": [
"### NumPy Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "W3NDseCE7-WB"
},
"source": [
"NumPy arrays are objects in NumPy that represent multidimensional arrays. Such\n",
"arrays have the data type `numpy.ndarray`, or `np.ndarray` for short. Unlike Python lists, NumPy arrays cannot store data that are of different types.\n",
"\n",
"To create a NumPy array from a Python list, we can do"
]
},
{
"cell_type": "code",
"execution_count": 44,
"metadata": {
"id": "1unOnNqB72_3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(3,)\n",
"1 2 3\n",
"[9 2 3]\n",
"(2, 3)\n",
"1 5 3\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([1, 2, 3]) # Create 1D array vector\n",
"print(a.shape) # Prints(3, )\n",
"print(a[0], a[1], a[2]) # Prints 1, 2, 3\n",
"a[0] = 9 # Change the zeroth element to 9\n",
"print(a) # Prints[9 2 3]\n",
"\n",
"b = np.array([[1, 2, 3], [4, 5, 6]]) # Creates 2D array (matrix)\n",
"print(b.shape) # Prints(2, 3)\n",
"print(b[0, 0], b[1, 1], b[0, 2]) # Prints 1, 5, 3\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tW_eQ0CN8uvW"
},
"source": [
"Alternatively, we can also create pre-filled arrays with a specified shape with certain NumPy functions. Several examples of these are shown below."
]
},
{
"cell_type": "code",
"execution_count": 45,
"metadata": {
"id": "ZlO57Ak38pX3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Object a\n",
"[[0. 0. 0.]\n",
" [0. 0. 0.]\n",
" [0. 0. 0.]]\n",
"Object b\n",
"[1. 1.]\n",
"Object c\n",
"[[1. 1. 1.]\n",
" [1. 1. 1.]\n",
" [1. 1. 1.]]\n",
"Object d\n",
"[[False False False]\n",
" [False False False]]\n",
"Object e\n",
"[0 1 2 3 4]\n"
]
}
],
"source": [
"a = np.zeros((3, 3)) # Create 3x3 matrix with all zeros\n",
"b = np.ones(2) # Create vector of size 2 with all ones\n",
"c = np.ones((3, 3)) # Create 3x3 matrix with all ones\n",
"d = np.full((2, 3), False) # Create a constant array\n",
"e = np.arange(5) # Creates a 1D array with values [0, 5)\n",
"\n",
"print('Object a')\n",
"print(a)\n",
"print('Object b')\n",
"print(b)\n",
"print('Object c')\n",
"print(c)\n",
"print('Object d')\n",
"print(d)\n",
"print('Object e')\n",
"print(e)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oc4X5elN9oNp"
},
"source": [
"Note that we can use functions like `np.zeros` and `np.ones` to pre-allocate arrays. We can then assign values to the entries using indexing.\n",
"More information about array creation in NumPy can be found [here](https://numpy.org/doc/stable/user/basics.creation.html#arrays-creation)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "TQ-gm6-I9yxd"
},
"source": [
"### Basic Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MKuUe8Dj96Mn"
},
"source": [
"Accessing the value of an element in a NumPy array is similar to that of lists in Python. However, observe that in the following, instead of doing something like a[i][j], we have `a[i, j]`."
]
},
{
"cell_type": "code",
"execution_count": 46,
"metadata": {
"id": "aVtAsMWM-Bsi"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\n",
"6\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"print(a[0, 0]) # Prints 1\n",
"print(a[1, 2]) # Prints 6"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Eghq5yqQ-IEN"
},
"source": [
"Slicing works very similarly too! For example,"
]
},
{
"cell_type": "code",
"execution_count": 47,
"metadata": {
"id": "WH1UVm53-JRA"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2 3]\n",
"[[2 3]\n",
" [5 6]]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3, 4], [4, 5, 6, 7]])\n",
"print(a[0, 1:3]) # Prints [2, 3]\n",
"print(a[:, 1:3]) # Prints [[2 3]\n",
" # [5 6]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YEC-5kzB96Qe"
},
"source": [
"However, do be careful of aliasing. The following illustrates an example of a side-effect that is caused by aliasing."
]
},
{
"cell_type": "code",
"execution_count": 48,
"metadata": {
"id": "b4aPSc9V9FqU"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"5\n"
]
}
],
"source": [
"b = a # Aliasing\n",
"b[0, 0] = 5\n",
"print(a[0, 0]) # Prints \"5\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "B7icHqWF-Sy3"
},
"source": [
"### Element-Wise Math Operation"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NISyJMKR-XWO"
},
"source": [
"NumPy provides several *element-wise math operations*. For example,"
]
},
{
"cell_type": "code",
"execution_count": 49,
"metadata": {
"id": "vNx9Wz_c-ROf"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 6 8]\n",
" [10 12]]\n",
"[[ 5 12]\n",
" [21 32]]\n"
]
}
],
"source": [
"x = np.array([[1,2],[3,4]])\n",
"y = np.array([[5,6],[7,8]])\n",
"\n",
"print(x + y) # Prints [[ 6 8]\n",
" # [10 12]]\n",
"\n",
"print(x * y) # Prints [[ 5 12]\n",
" # [21 32]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "81ptLkxU-a-w"
},
"source": [
"Similarly, operations for subtraction and division are also provided, and are given by `-` and `/`, respectively.\n",
"\n",
"**Note**: `*` is an element-wise multiplication of two matrices, not a matrix multiplication of\n",
"two matrices, as covered in task 1.4."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### General Math Operation"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"NumPy provides many *math operations*. We give some examples below. For a full list of what Numpy can do, please have a look at the following links:\n",
"\n",
"* [Math](https://numpy.org/doc/stable/reference/routines.math.html)\n",
"* [Statistics](https://numpy.org/doc/stable/reference/routines.statistics.html)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sum\n",
"\n",
"`numpy.sum` computes the sum of array elements over a given axis.\n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 50,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.0\n",
"2.0\n",
"6\n",
"[0 6]\n",
"[1 5]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"print(np.sum([])) # 0.0\n",
"print(np.sum([0.5, 1.5])) # 2.0\n",
"print(np.sum([[0, 1], [0, 5]])) # 6\n",
"print(np.sum([[0, 1], [0, 5]], axis=0)) # array([0, 6])\n",
"print(np.sum([[0, 1], [0, 5]], axis=1)) # array([1, 5])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Mean\n",
"\n",
"`numpy.mean` computes the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. \n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 51,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2.5\n",
"[2. 3.]\n",
"[1.5 3.5]\n"
]
}
],
"source": [
"a = np.array([[1, 2], [3, 4]])\n",
"print(np.mean(a)) # 2.5\n",
"print(np.mean(a, axis=0)) # array([2., 3.])\n",
"print(np.mean(a, axis=1)) # array([1.5, 3.5])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Floor & Ceil\n",
"\n",
"`numpy.floor` returns the floor of the input, element-wise. The floor of the scalar $x$ is the largest integer $i$, such that $i \\le x$. It is often denoted as $\\lfloor x \\rfloor$.\n",
"\n",
"`numpy.ceil` returns the ceiling of the input, element-wise. The ceil of the scalar x is the smallest integer i, such that i >= x. It is often denoted as $\\lceil x \\rceil$.\n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 54,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[-2. -2. -1. 0. 1. 1. 2.]\n",
"[-1. -1. -0. 1. 2. 2. 2.]\n"
]
}
],
"source": [
"a = np.array([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0])\n",
"print(np.floor(a)) # array([-2., -2., -1., 0., 1., 1., 2.])\n",
"print(np.ceil(a)) # array([-1., -1., -0., 1., 2., 2., 2.])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F-qWcOyh-q-w"
},
"source": [
"## COVID-19 Data as NumPy Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nu8iuUGZ-trh"
},
"source": [
"Now that we understand the representation of NumPy arrays, we will try to learn how to use NumPy by working on some practical problems. In particular, we shall take a look at the COVID-19 data which will be used in the following tasks. These data are [time series data](https://en.wikipedia.org/wiki/Time_series) obtained from 1 January 2020 to 31 December 2020. \n",
"\n",
"For the convenience of notation, we shall refer to 1 January 2020 as the $1$st day and 31 December 2019 as the $0$th day. Observe that this means that the following data **do not** contain measurements on the 0th day, i.e. 31 December 2019.} In addition, in the following tasks, assume that $i, j \\geq 0$, whenever they are used as indexes.\n",
"\n",
"First, let us describe the data set that we will be working with. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uLwkuhfF3PiC"
},
"source": [
"### **`cases_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HUbvGwPK3UPD"
},
"source": [
"It is a 2D `np.ndarray` with each row representing the data of a country while the columns of each row represent the time series data of the cumulative number of confirmed cases in that country, i.e. the $i$-th row of `cases_cumulative` contains the data of the $i$-th country, and the $(i, j)$ entry of `cases_cumulative` is the *cumulative number* of confirmed cases on the $(j + 1)$th day in the $i$th country.\n",
"\n",
"For example, suppose"
]
},
{
"cell_type": "code",
"execution_count": 53,
"metadata": {
"id": "3gbHqkGa-fkB"
},
"outputs": [],
"source": [
"cases_cumulative = np.array([[0, 1, 2, 3], [0, 20, 21, 35]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kGeE-oed3ofk"
},
"source": [
"This means that the 0th country has recorded 0, 1, 2 and 3 cases on the 1st, 2nd, 3rd and 4th day, respectively. Similarly, the 1st country has recorded 0, 20, 21 and 35 cases on the 1st, 2nd, 3rd and 4th day.\n",
"\n",
"**Important**:\n",
"\n",
"Observe that ${(i, j)}$ entry corresponds to the data for the ${i}$-th country but ${(j + 1)}$-th day. For day 0, assume that the number of cases recorded is 0 for all countries.\n",
"\n",
"Here, *cumulative number* means that the recorded data is the total number of cases detected since day 0, not only the new cases that have been detected on a particular day. Hence, generally, `cases_cumulative[i, j]` $\\leq$ `cases_cumulative[i, j + 1]`.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "K-bF65CK3tBV"
},
"source": [
"### **`cases_top_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oV4X8qcY4N8u"
},
"source": [
"This variable is similar to `cases_cumulative`. However, it only contains data for the three countries that recorded the most number of confirmed COVID-19 cases in 2020. These data might come in handy during debugging and testing.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XPBq32dV4SpE"
},
"source": [
"### **`deaths_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hATkVnyx4ViC"
},
"source": [
"`deaths_cumulative` is similar to `cases_cumulative`, but instead of recording the cumulative number of confirmed cases, it records the cumulative number of deaths caused by COVID-19.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hdnlmCc04kzp"
},
"source": [
"### **`healthcare_spending`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SjvPjJ9i4k28"
},
"source": [
"This is a 2D `np.ndarray` with each row representing the data of a country while the columns of each row represent the time series data of the emergency healthcare spending made by that country, i.e. the $i$-th row of `healthcare_spending` contains the data of the $i$-th country, and the $(i, j)$ entry of `healthcare_spending` is the amount which the $i$-th country spent on healthcare on the $(j + 1)$-th day. Assume that the healthcare spending on the 0-th day is \\$0 for all countries.\n",
"\n",
"For example, suppose"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "L5Dg8kPE3rid"
},
"outputs": [],
"source": [
"healthcare_spending = np.array([[0, 100, 0, 200], [0, 0, 0, 1000]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "AIKQ6qCb46hu"
},
"source": [
"Then, the 0th country only made an emergency expenditure on healthcare on the 2nd and 4th days that amounted to \\$100 and \\$200, respectively; similarly, the 1st country only made an emergency expenditure on the 4th day which amounted to \\$1000.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "mtbqt7uC5Bv3"
},
"source": [
"### **`mask_prices`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ce-xxi_t5Dlo"
},
"source": [
"`mask_prices` is a 1D `np.ndarray` such that the $j$-th entry represents the global average cost of 100 masks on the $(j + 1)$-th day.\n",
"\n",
"For example, if"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4x0dxMTJ4-X8"
},
"outputs": [],
"source": [
"mask_prices = np.array([4, 5, 20, 18])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WCnTULNz5R8y"
},
"source": [
"then the global average cost of 100 masks on the 1st, 2nd, 3rd and 4th day is \\$4, \\$5, \\$20 and \\$18, respectively.\n",
"\n",
"**Note**: The prices are not real but the overall fluctuations are chosen to simulate those observed in 2020."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n70RPHKx5fne"
},
"source": [
"### **`stringency_values`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_4yj4Ts55hsE"
},
"source": [
"This variable is a 3D `np.ndarray` with each row representing the data of a country, and the columns of each row representing the time series data of the stringency values as a vector. To be specific, on each day, there are four different stringency indicators: 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls'. \n",
"\n",
"For instance, suppose"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "JY_K3jkh5Yo_"
},
"outputs": [],
"source": [
"stringency_values = np.array([[[0, 0, 0, 0], [1, 0, 0, 0]],\\\n",
" [[0, 0, 0, 0], [0, 1, 2, 0]]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8Beq-_7r5hxI"
},
"source": [
"This means that for the 0th country, on the 1st day, the stringency values for 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls' were all 0. On the 2nd day, all the stringency values remained the same, except for 'school closing', which rose to 1.\n",
"\n",
"As for the 1st country, on the 1st day, the stringency values were the same as the 0th country's. However, on the 2nd day, the stringency values for 'workplace closing' and 'stay at home requirements' rose to 1 and 2, respectively.\n",
"\n",
"In this context, the higher the stringency value, the more restrictive the policy is."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Get the data from CSV"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As shown in the last few lines of `ps0.py`, we can get the data for these variables by doing the following"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from prepare_data import * # loads the `get_...` helper funtions\n",
"\n",
"df = get_data()\n",
"cases_cumulative = get_n_cases_cumulative(df)\n",
"deaths_cumulative = get_n_deaths_cumulative(df)\n",
"healthcare_spending = get_healthcare_spending(df)\n",
"mask_prices = get_mask_prices(healthcare_spending.shape[1])\n",
"stringency_values = get_stringency_values(df)\n",
"cases_top_cumulative = get_n_cases_top_cumulative(df)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iUOLLiiK52kC"
},
"source": [
"In the upcoming tasks, we will be manipulating these data, and finding answers to certain questions that we might have about issues that are related to COVID-19.\n",
"\n",
"**IMPORTANT**: You are allowed to use any of the [mathematical functions](https://numpy.org/doc/stable/reference/routines.math.html) from NumPy in all of the following tasks.\n",
"For your convenience, you may use some of the non-mathematical functions provided by NumPy, but not all of them. For example, [`np.vectorize`](https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html) isn't allowed since it is iterative. If in doubt, do ask in the forum :) With this said, do note that it is absolutely possible to complete these tasks without the non-mathematical functions that are not introduced in this document.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XtMITSIQ6wXR"
},
"source": [
"## Task 2.1: Computing Death Rates"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9BTFV_PG6yvu"
},
"source": [
"Our first task in this part of the homework is to implement `compute_death_rate_first_n_days`, which takes in three arguments, `n`, `cases_cumulative` and `deaths_cumulative`, and **computes the average number of deaths recorded for every confirmed case that has been recorded from the first day to the nth day (inclusive)**. This should be done for each country.\n",
"\n",
"The return value should be a `np.ndarray` such that the entry in the $i$-th row corresponds to the death rate in the $i$-th country as represented in `cases_cumulative` and `deaths_cumulative`.\n",
"\n",
"For instance, if the returned value is `np.array([0.5, 0.2])`, it means that in the 0th country, for every 2 individuals who contracted the virus, one of them will, on average, die. In contrast, in the 1st country, for every 5 individuals who contracted the virus, only one of them will, on average, die.\n",
"\n",
"**Note**:\n",
"You may assume that the $i$-th row in `cases_cumulative` represents the same country as the $i$-th row in `deaths_cumulative`. Moreover, if there are no confirmed cases for a particular country, its average death rate should be zero. If the data includes less than `n` days of data, then you just return the result for all the days given in the data provided. \n",
"\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to deal with `nan` values using `np.nan_to_num`, which has the following signature: `numpy.nan_to_num(x, copy=True, nan=0.0, posinf=None, neginf=None)`. You should also check out the detailed description [here](https://numpy.org/doc/stable/reference/generated/numpy.nan_to_num.html) because there are many functions of the same nature. Essentially, we can use `np.nan_to_num` to convert all the `nan` values in an `np.ndarray` to a specified value. Some examples of how `np.nan_to_num` can be used is shown below:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(np.nan_to_num(np.inf)) #1.7976931348623157e+308\n",
"print(np.nan_to_num(-np.inf)) #-1.7976931348623157e+308\n",
"print(np.nan_to_num(np.nan)) #0.0\n",
"x = np.array([np.inf, -np.inf, np.nan, -128, 128])\n",
"np.nan_to_num(x)\n",
"np.nan_to_num(x, nan=-9999, posinf=33333333, neginf=33333333) # Specify nan to be -9999, and both posinf and neginf to be 33333333\n",
"np.nan_to_num(y, nan=111111, posinf=222222) # Specify nan to be 111111, and both posinf and neginf to be 222222"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SOF2JEoW5xJE"
},
"outputs": [],
"source": [
"def compute_death_rate_first_n_days(n, cases_cumulative, deaths_cumulative):\n",
" '''\n",
" Computes the average number of deaths recorded for every confirmed case\n",
" that is recorded from the first day to the nth day (inclusive).\n",
" Parameters\n",
" ----------\n",
" n: int\n",
" How many days of data to return in the final array.\n",
" cases_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed cases in that country, i.e. the ith row of `cases_cumulative`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `cases_cumulative` is the cumulative number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" deaths_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed deaths (as a result of COVID-19) in that country, i.e. the ith\n",
" row of `n_deaths_cumulative` contains the data of the ith country, and\n",
" the (i, j) entry of `n_deaths_cumulative` is the cumulative number of\n",
" confirmed deaths on the (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Average number of deaths recorded for every confirmed case from the first day\n",
" to the nth day (inclusive) for each country as a 1D `ndarray` such that the\n",
" entry in the ith row corresponds to the death rate in the ith country as\n",
" represented in `cases_cumulative` and `deaths_cumulative`.\n",
" Note\n",
" ----\n",
" `cases_cumulative` and `deaths_cumulative` are such that the ith row in the \n",
" former and that in the latter contain data of the same country. In addition,\n",
" if there are no confirmed cases for a particular country, the expected death\n",
" rate for that country should be zero. (Hint: to deal with NaN look at\n",
" `np.nan_to_num`)\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test cases for Task 2.1\n",
"n_cases_cumulative = cases_cumulative[:3, :] #Using data from CSV. Make sure to run relevant cell above\n",
"n_deaths_cumulative = deaths_cumulative[:3, :]\n",
"expected = np.array([0.0337837838, 0.0562347188, 0.1410564226])\n",
"np.testing.assert_allclose(compute_death_rate_first_n_days(100, n_cases_cumulative, n_deaths_cumulative), expected)\n",
"\n",
"sample_cumulative = np.array([[1,2,3,4,8,8,10,10,10,10], [1,2,3,4,8,8,10,10,10,10]])\n",
"sample_death = np.array([[0,0,0,1,2,2,2,2,5,5], [0,0,0,1,2,2,2,2,5,5]])\n",
"\n",
"expected2 = np.array([0.5, 0.5])\n",
"assert(np.all(compute_death_rate_first_n_days(10, sample_cumulative, sample_death) == expected2))\n",
"\n",
"sample_cumulative2 = np.array([[1,2,3,4,8,8,10,10,10,10]])\n",
"sample_death2 = np.array([[0,0,0,1,2,2,2,2,5,5]])\n",
"\n",
"expected3 = np.array([0.5])\n",
"assert(compute_death_rate_first_n_days(10, sample_cumulative2, sample_death2) == expected3)\n",
"expected4 = np.array([0.25])\n",
"assert(compute_death_rate_first_n_days(5, sample_cumulative2, sample_death2) == expected4)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uCQ7_juB7ks0"
},
"source": [
"## Task 2.2: Computing Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E7W2-0HI72VS"
},
"source": [
"Our second task requires us to implement `compute_increase_in_cases` which accepts one argument `cases_cumulative` and **computes the daily increase in confirmed cases for each country, starting from the first day**.\n",
"\n",
"This function should return the daily increase in cases for each country as a 2D `np.ndarray` such that the $(i, j)$ entry corresponds to the increase in confirmed cases in the $i$-th country on the $(j + 1)$-th day, where $j$ is non-negative.\n",
"\n",
"Recall that as we have previously mentioned, the number of cases on the 0th day can be assumed to be 0 for all countries.\n",
"\n",
"To be specific, suppose `cases_cumulative` only contains data for 4 days such that it is equal to `np.array([[1, 2, 3, 4], [1, 3, 6, 10]])`. Then, the return value of this function should be `np.array([[1, 1, 1, 1], [1, 2, 3, 4]])`. This means that from days 1 to 4, in country 0, there was one new recorded case on each day. In contrast, in country 1, there were 2, 3 and 4 new cases on days 2, 3 and 4, respectively.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to compute differences between adjacent elements in an array using `np.diff`, which has the following signature: `numpy.diff(a, n=1, axis=-1, prepend=, append=)`. `np.diff` calculates the n-th discrete difference along the given axis. The first difference is given by `out[i] = a[i+1] - a[i]` along the given axis; higher differences are calculated by using diff recursively. The following are some examples of how `np.diff` can be used:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"x = np.array([1, 2, 4, 7, 0])\n",
"np.diff(x) # array([1, 2, 3, -7])\n",
"np.diff(x, n=2) # array([1, 1, -10])\n",
"\n",
"x = np.array([[1, 3, 6, 10], [0, 5, 6, 8]])\n",
"np.diff(x) # array([[2, 3, 4], [5, 1, 2]])\n",
"np.diff(x, axis=0) # array([[-1, 2, 0, -2]])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Le8aWyr17etU"
},
"outputs": [],
"source": [
"def compute_increase_in_cases(n, cases_cumulative):\n",
" '''\n",
" Computes the daily increase in confirmed cases for each country for the first n days, starting\n",
" from the first day.\n",
" Parameters\n",
" ---------- \n",
" n: int\n",
" How many days of data to return in the final array. If the input data has fewer\n",
" than n days of data then we just return whatever we have for each country up to n. \n",
" cases_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed cases in that country, i.e. the ith row of `cases_cumulative`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `cases_cumulative` is the cumulative number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Daily increase in cases for each country as a 2D `ndarray` such that the (i, j)\n",
" entry corresponds to the increase in confirmed cases in the ith country on\n",
" the (j + 1)th day, where j is non-negative.\n",
" Note\n",
" ----\n",
" The number of cases on the zeroth day is assumed to be 0, and we want to\n",
" compute the daily increase in cases starting from the first day.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.2\n",
"cases_cumulative = np.zeros((100, 20))\n",
"cases_cumulative[:, :] = np.arange(1, 21)\n",
"actual = compute_increase_in_cases(100, cases_cumulative)\n",
"assert(np.all(actual == np.ones((100, 20))))\n",
"\n",
"sample_cumulative = np.array([[1,2,3,4,8,8,10,10,10,10],[1,1,3,5,8,10,15,20,25,30]])\n",
"expected = np.array([[1, 1, 1, 1, 4.], [1, 0, 2, 2, 3]])\n",
"assert(np.all(compute_increase_in_cases(5,sample_cumulative) == expected))\n",
"\n",
"expected2 = np.array([[1, 1, 1, 1, 4, 0, 2, 0, 0, 0],[1, 0, 2, 2, 3, 2, 5, 5, 5, 5]])\n",
"assert(np.all(compute_increase_in_cases(10,sample_cumulative) == expected2))\n",
"assert(np.all(compute_increase_in_cases(20,sample_cumulative) == expected2))\n",
"\n",
"sample_cumulative2 = np.array([[51764, 51848, 52007, 52147, 52330, 52330],\\\n",
" [55755, 56254, 56572, 57146, 57727, 58316],\\\n",
" [97857, 98249, 98631, 98988, 99311, 99610]])\n",
"expected3 = np.array([\\\n",
" [51764, 84, 159, 140, 183, 0],\\\n",
" [55755, 499, 318, 574, 581, 589],\\\n",
" [97857, 392, 382, 357, 323, 299]])\n",
"assert(np.all(compute_increase_in_cases(6,sample_cumulative2) == expected3))\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "yx-hn5dC8RA6"
},
"source": [
"## Axes"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ggXC9VM-8YFf"
},
"source": [
"When using certain NumPy functions, we might encounter the axis argument. [`np.sum`](https://numpy.org/doc/stable/reference/generated/numpy.sum.html) is an example.\n",
"\n",
"For a 3D (or 2D, if we ignore the blue slice at the back which contains the values 2, 4, 6 and 8), the axes are defined as shown in figure below.\n",
"\n",
"\n",
"\n",
"*Note*: NumPy arrays can have an arbitrary positive integer number of axes. If we have an N-D array with N > 3, we just need to (mentally) project it onto a smaller dimensional space so that we can have a handle of what each axis means.}\n",
"\n",
"Therefore, returning to `np.sum`, we see that"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "GtCGMCpp8QQT"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])\n",
"print(np.sum(a, axis=0)) # Prints [[ 6, 8],\n",
" # [10, 12]]\n",
"print(np.sum(a, axis=1)) # Prints [[ 4, 6],\n",
" # [12, 14]]\n",
"print(np.sum(a, axis=2)) # Prints [[ 3, 7],\n",
" # [11, 15]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "aF5DV48W9AKp"
},
"source": [
"## Task 2.3: Finding Maximum Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nKwWcvbp9CiU"
},
"source": [
"Our third task is to implement `find_max_increase_in_cases` which takes in one argument `n_cases_increase` and **finds the maximum daily increase in confirmed cases for each country**.\n",
"\n",
"In this case, `n_cases_increase` is the output obtained from calling `compute_increase_in_cases(n_cases_cumulative)`.\n",
"\n",
"The return value should be a 1D `np.ndarray` that represents the maximum daily increase in cases for each country. In particular, the $i$-th entry of this array should correspond to the increase in confirmed cases in the $i$-th country as represented in `n_cases_increase`.\n",
"\n",
"Returning to our previous example in task 2.2, suppose the daily increase in cases is given by `np.array([[1, 1, 1, 1], [1, 2, 3, 4]])`. Clearly, the maximum daily increase in cases is 1 and 4 for country 0 and 1, respectively. Therefore, we should expect the output of this function to be `np.array([1, 4])`.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to use `np.max`, or the equivalent `np.amax`, to find the max value in a column of a matrix. The following is a sample execution of how these functions work:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.arange(4).reshape((2,2)) # array([[0, 1], [2, 3]])\n",
"np.amax(a) # 3 -> Maximum of the flattened array\n",
"np.amax(a, axis=0) # array([2, 3]) -> Maxima along the first axis (first column) \n",
"np.amax(a, axis=1) # array([1, 3]) -> Maxima along the second axis (second column)\n",
"np.amax(a, where=[False, True], initial=-1, axis=0) # array([-1, 3])\n",
"b = np.arange(5, dtype=float) # array([0., 1., 2., 3., 4.])\n",
"b[2] = np.NaN # array([ 0., 1., nan, 3., 4.])\n",
"np.amax(b) # nan"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TnYgBS0m9B63"
},
"outputs": [],
"source": [
"def find_max_increase_in_cases(n_cases_increase):\n",
" '''\n",
" Finds the maximum daily increase in confirmed cases for each country.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the daily increase in the number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Maximum daily increase in cases for each country as a 1D `ndarray` such that the\n",
" ith entry corresponds to the increase in confirmed cases in the ith country as\n",
" represented in `n_cases_increase`.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.3\n",
"n_cases_increase = np.ones((100, 20))\n",
"actual = find_max_increase_in_cases(n_cases_increase)\n",
"expected = np.ones(100)\n",
"assert(np.all(actual == expected))\n",
"\n",
"sample_increase = np.array([[1,2,3,4,8,8,10,10,10,10],[1,1,3,5,8,10,15,20,25,30]])\n",
"expected2 = np.array([10, 30]) # max of [1,2,3,4,8,8,10,10,10,10] => 10, max of [1,1,3,5,8,10,15,20,25,30] => 30\n",
"assert(np.all(find_max_increase_in_cases(sample_increase) == expected2))\n",
"\n",
"sample_increase2 = np.array([\\\n",
" [51764, 84, 159, 140, 183, 0],\\\n",
" [55755, 499, 318, 574, 581, 589],\\\n",
" [97857, 392, 382, 357, 323, 299]])\n",
"expected3 = np.array([51764, 55755, 97857])\n",
"assert(np.all(find_max_increase_in_cases(sample_increase2) == expected3))\n",
"\n",
"n_cases_increase2 = compute_increase_in_cases(cases_top_cumulative.shape[1], cases_top_cumulative)\n",
"expected4 = np.array([ 68699., 97894., 258110.])\n",
"assert(np.all(find_max_increase_in_cases(n_cases_increase2) == expected4))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "e10BJ74p9eS-"
},
"source": [
"## Broadcasting"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PPuJv8kC9hJb"
},
"source": [
"*Broadcasting* makes it possible for us to apply arithmetic operations to arrays with different shapes. This is especially helpful when we have a smaller array and larger array such that we want to copy the smaller array multiple times such that its shape (i.e. the number of elements in each axis) is the same as the larger array's, before performing arithmetic operations on both arrays. Specifically, with broadcasting, we do not need to explicitly make copies of the smaller array for the arithmetic operation to work. \n",
"\n",
"For example,\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5danymoS9cqj"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"b = np.array([[0, 1, 2]])\n",
"c = np.array([[0, 1, 2], [0, 1, 2]])\n",
"d = np.full((2, 3), 5)\n",
"\n",
"print(a + b) # Prints [[1 3 5]\n",
" # [4 6 8]]\n",
" # Equivalent to a + c\n",
"print(a + 5) # Prints [[ 6, 7, 8],\n",
" # [ 9, 10, 11]]\n",
" # Equivalent to a + d"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3wZr_D4z9s3C"
},
"source": [
"The details of broadcasting can be found [here](https://numpy.org/doc/stable/user/basics.broadcasting.html).\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "EeYafm-090kt"
},
"source": [
"At times, we might need to add dimensions to one of the arrays so that broadcasting gives us our desired result. To do so, we can use `None`. \n",
"\n",
"For example, suppose we want to create a $3 \\times 2$ matrix, represented by `c`, from `a = np.array([4, 5, 6])` and `b = np.array([1, 2])` such that `c[i, j] = a[i] + b[j]`. Then, we can do the following"
]
},
{
"cell_type": "code",
"execution_count": 55,
"metadata": {
"id": "nbe68bm--FuQ"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[4 5 6]\n",
"[1 2]\n",
"[[4]\n",
" [5]\n",
" [6]]\n",
"[[1 2]]\n",
"[[5 6]\n",
" [6 7]\n",
" [7 8]]\n"
]
}
],
"source": [
"a = np.array([4, 5, 6])\n",
"print(a) # Prints [4, 5, 6]\n",
"b = np.array([1, 2])\n",
"print(b) # Prints [1, 2]\n",
"c = a[:, None] \n",
"print(c) # Prints [[4]\n",
" # [5]\n",
" # [6]]\n",
"d = b[None, :]\n",
"print(d) # Prints [[1 2]]\n",
"e = c + d\n",
"print(e) # Prints [[5 6]\n",
" # [6 7]\n",
" # [7 8]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qhIjMRK1-JM-"
},
"source": [
"Alternatively, we can use `reshape` to get the same results.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fulFjQf8-Icw"
},
"outputs": [],
"source": [
"c = a.reshape((3, 1)) + b\n",
"print(c) # Prints [[5 6]\n",
" # [6 7]\n",
" # [7 8]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ts_b7Hrk-QZ3"
},
"source": [
"## Task 2.4: Computing Number of Purchaseable Masks"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6DhPv99S-Tin"
},
"source": [
"Our fourth task is to implement `compute_n_masks_purchaseable`. This function takes two arguments, namely `healthcare_spending` and `mask_prices`, and it should **compute the total number of masks that each country can purchase if she spends all her emergency healthcare spending on masks**.\n",
"\n",
"Assume that all countries bought the masks at the global average costs, and to reduce administrative hassle, they only buy masks on day $(j + 1)$ with their emergency funds on day $(j + 1)$, i.e. the masks that are bought on a particular day are not purchased with funding from the previous days.\n",
"\n",
"The return value should be the total number of masks, which each country can purchase, represented as a 1D `np.ndarray` such that the $i$-th entry corresponds to the total number of masks purchaseable by the $i$-th country as represented in `healthcare_spending`.\n",
"\n",
"For example, if we have `healthcare_spending = np.array([[0, 100, 0], [100, 0, 200]])` and `mask_prices = np.array([4, 3, 20])`. Then, we expect the return value to be `np.array([3300. 3500.])`. This is because country 0 can only buy $33 \\times 100 = 3300$ masks on day 2 with \\$100 since the masks are priced at \\$3 and are sold in batches of 100. Similarly, we find that country 1 can only buy $(25 + 10) \\times 100 = 3500$ masks. \n",
"\n",
"In this task, you may use the `np.sum` and the `np.floor` functions.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "lscWd3LX-SR7"
},
"outputs": [],
"source": [
"def compute_n_masks_purchaseable(healthcare_spending, mask_prices):\n",
" '''\n",
" Computes the total number of masks that each country can purchase if she\n",
" spends all her emergency healthcare spending on masks.\n",
" Parameters\n",
" ----------\n",
" healthcare_spending: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the emergency healthcare\n",
" spending made by that country, i.e. the ith row of `healthcare_spending`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `healthcare_spending` is the amount which the ith country spent on healthcare\n",
" on (j + 1)th day.\n",
" mask_prices: np.ndarray\n",
" 1D `ndarray` such that the jth entry represents the cost of 100 masks on the\n",
" (j + 1)th day.\n",
" \n",
" Returns\n",
" -------\n",
" Total number of masks which each country can purchase as a 1D `ndarray` such\n",
" that the ith entry corresponds to the total number of masks purchaseable by the\n",
" ith country as represented in `healthcare_spending`.\n",
" Note\n",
" ----\n",
" The masks can only be bought in batches of 100s.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.4\n",
"prices_constant = np.ones(5)\n",
"healthcare_spending_constant = np.ones((7, 5))\n",
"actual = compute_n_masks_purchaseable(healthcare_spending_constant, prices_constant)\n",
"expected = np.ones(7) * 500\n",
"assert(np.all(actual == expected))\n",
"\n",
"healthcare_spending1 = healthcare_spending[:3, :] #Using data from CSV\n",
"expected2 = [3068779300, 378333500, 6208321700]\n",
"assert(np.all(compute_n_masks_purchaseable(healthcare_spending1, mask_prices)==expected2))\n",
"\n",
"healthcare_spending2 = np.array([[0, 100, 0], [100, 0, 200]])\n",
"mask_prices2 = np.array([4, 3, 20])\n",
"expected3 = np.array([3300, 3500])\n",
"assert(np.all(compute_n_masks_purchaseable(healthcare_spending2, mask_prices2)==expected3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "h-S8a06N_GP6"
},
"source": [
"## Matrix Multiplication"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_lN2l9BV_INc"
},
"source": [
"To perform matrix multiplication on two NumPy arrays, we use the syntax `@`. In particular, if we want to multiply array `A` and `B`, we will do `A @ B`. For example,\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.array([[1,1],[1,2]]) # array([[1, 1], [1, 2]])\n",
"b = np.array([[1],[1]]) # array([[1], [1]])\n",
"c = a @ b\n",
"print(c) # Prints [[2]\n",
" # [3]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The specifics of this operations is as follow:\n",
"\n",
"- if A and B are both 2D, they are multiplied like conventional matrices.\n",
"- if one of them is N-D, with N > 2, that matrix is treated as a stack of matrices. Broadcasting will be done where necessary.\n",
"\n",
"More details can be found [here](https://numpy.org/doc/stable/user/basics.broadcasting.html)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZMRfyy8s_gCg"
},
"source": [
"## Task 2.5: Computing Stringency Index"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DdY664xo_hhn"
},
"source": [
"Our fifth last task for this homework is to implement `compute_stringency_index`. This function takes `stringency_values` as argument, and **computes the daily stringency index for each country**.\n",
"\n",
"This function returns the daily stringency index for each country as a 2D `np.ndarray` such that the $(i, j)$ entry corresponds to the stringency index in the $i$-th country on the $(j + 1)$-th day. In this case, the higher the stringency index, the more restrictive the measures are.\n",
"\n",
"Recall that on each day, each country has four stringency values for ’school closing’, ’workplace closing’, ’stay at home requirements’ and ’international travel controls’. In this case, we shall assume that 'stay at home requirements' is the most restrictive regulation among the other regulations; 'international travel controls' is more restrictive than 'school closing' and 'workplace closing'; and 'school closing' and 'workplace closing' are equally restrictive. Thus, to compute the stringency index, we shall weigh each stringency value by 1, 1, 3 and 2 for 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls', respectively. Then, **the stringency index for the $i$th country on the $(j + 1)$th day is given by**:\n",
"\n",
"`stringency_values[i, j, 0] + stringency_values[i, j, 1] + 3 * stringency_values[i, j, 2] + 2 * stringency_values[i, j, 3]`\n",
"\n",
"**Note**: Use the matrix multiplication operator (`@` operator) to compute the stringency index. Please do not use iterative approaches like for-loops."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TnEqpaNo-z2v"
},
"outputs": [],
"source": [
"def compute_stringency_index(stringency_values):\n",
" '''\n",
" Computes the daily stringency index for each country.\n",
" Parameters\n",
" ----------\n",
" stringency_values: np.ndarray\n",
" 3D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the stringency values as a\n",
" vector. To be specific, on each day, there are four different stringency\n",
" values for 'school closing', 'workplace closing', 'stay at home requirements'\n",
" and 'international travel controls', respectively. For instance, the (i, j, 0)\n",
" entry represents the `school closing` stringency value for the ith country\n",
" on the (j + 1)th day.\n",
" \n",
" Returns\n",
" -------\n",
" Daily stringency index for each country as a 2D `ndarray` such that the (i, j)\n",
" entry corresponds to the stringency index in the ith country on the (j + 1)th\n",
" day.\n",
" In this case, we shall assume that 'stay at home requirements' is the most\n",
" restrictive regulation among the other regulations, 'international travel\n",
" controls' is more restrictive than 'school closing' and 'workplace closing',\n",
" and 'school closing' and 'workplace closing' are equally restrictive. Thus,\n",
" to compute the stringency index, we shall weigh each stringency value by 1,\n",
" 1, 3 and 2 for 'school closing', 'workplace closing', 'stay at home\n",
" requirements' and 'international travel controls', respectively. Then, the \n",
" index for the ith country on the (j + 1)th day is given by\n",
" `stringency_values[i, j, 0] + stringency_values[i, j, 1] +\n",
" 3 * stringency_values[i, j, 2] + 2 * stringency_values[i, j, 3]`.\n",
" Note\n",
" ----\n",
" Use matrix operations and broadcasting to complete this question. Please do\n",
" not use iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.5\n",
"stringency_values = np.ones((10, 20, 4))\n",
"stringency_values[:, 10:, :] *= 2\n",
"actual = compute_stringency_index(stringency_values)\n",
"expected = np.ones((10, 20)) * (1 + 1 + 3 + 2)\n",
"expected[:, 10:] *= 2\n",
"assert(np.all(actual == expected))\n",
"\n",
"stringency_values2 = np.array([[[0, 0, 0, 0], [1, 0, 0, 0]], [[0, 0, 0, 0], [0, 1, 2, 0]]])\n",
"actual2 = compute_stringency_index(stringency_values2)\n",
"expected2 = np.array([[0, 1], [0, 7]])\n",
"assert(np.all(actual2 == expected2))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nqtOvepLARkQ"
},
"source": [
"## More Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F5OtHQYwAU_q"
},
"source": [
"In fact, indexing in NumPy can be more sophisticated than what we have seen previously! \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZMxvRCGCAZe9"
},
"source": [
"### Integer Array Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "17ngFFwGAddt"
},
"source": [
"We can use a Python list or a NumPy array to index a NumPy array. For example,"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "te4V8yif_6JG"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"print(a[:, [0, 2]]) # Prints [[1 3]\n",
" # [4 6]]\n",
"print(a[[1, 0], [1, 2]]) # Prints [5 3]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7J5iATyJAffY"
},
"source": [
"Note that `a[[1, 0], [1, 2]]` essentially returns `a[1, 1]` and `a[0, 2]`."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PO3JUERDAp-V"
},
"source": [
"### Boolean Array Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "wofAGm5VAq84"
},
"source": [
"An array of Boolean can be used to determine which elements of a given array should be left out. For instance,"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "RPG5cp5EAlpr"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([4, 3, 1, 5, 10])\n",
"desired_indices = a > 3\n",
"print(a[desired_indices]) # Selects values in `a` that are\n",
" # greater than 3; prints [ 4 5 10]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Introduction to Matplotlib\n",
"\n",
"Matplotlib is a powerful and widely-used Python library for creating visualisations. We can use it to generate a wide variety of plots, charts, and graphs. We will make use of this library often in future problem sets.\n",
"\n",
"Below is an example of how to use Matplotlib to plot two different functions in the same graph"
]
},
{
"cell_type": "code",
"execution_count": 57,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAIhCAYAAABg21M1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8qNh9FAAAACXBIWXMAAA9hAAAPYQGoP6dpAAB0RUlEQVR4nO3dd1jV5f/H8ecBFUEBt7hXau6dWpYjNTW3mblt2NLKzOpbNmxpy9QsR1bOHGVppuVO09RS0zQry9wiaQ5wgsD5/XH/DgecgMB9xutxXZ/r3JzFm/Xhde5zD4fT6XQiIiIiIuIFAmwXICIiIiKSWgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvIbCq4iIiIh4DYVXEREREfEaCq8ikiGmTJmCw+FIOrJly0bx4sW59957OXToUNL9Vq1ahcPhYNWqVWn+HOvWrWPYsGGcPHnyktvGjRvHlClTLrl+7969OByOy96WmZo0aZLi+3GlY9iwYVlaV79+/a5Yy8KFC7O0losNHz6c+fPnX3L99fzOiIjvyWa7ABHxLZMnT+bGG2/k3Llz/PDDD4wYMYLVq1ezfft2cuXKdV3PvW7dOl555RX69etHnjx5Utw2btw4ChQoQL9+/VJcX6RIEdavX0+5cuWu63On1bhx44iJiUn6eNGiRbz++utJ3x+X4sWLZ2ldAMHBwaxcufKS65PXZcPw4cO566676NixY4rra9euzfr166lcubKdwkTEoyi8ikiGqlq1KnXr1gWgadOmJCQk8NprrzF//nx69uyZ5fUEBQXRoEGDLP+8FwetP//8E0j5/bElICDAyvckvcLCwryqXhHJXBo2ICKZyhU69u3bd9X7LViwgIYNGxISEkJoaCgtWrRg/fr1SbcPGzaMp59+GoAyZcokvdW9atUqSpcuzY4dO1i9enXS9aVLlwYuP2xg2LBhOBwOduzYQffu3QkPD6dw4cLcd999REdHp6jr5MmT3H///eTLl4/cuXNz5513snv37ut+y//DDz8kICCAI0eOJF03cuRIHA4HAwYMSLouMTGRvHnz8tRTTyVdd/z4cR599FGKFStGjhw5KFu2LEOHDiU2Njbd9bhc6S36y30f+/XrR+7cudm1axdt2rQhd+7clChRgqeeeuqSWmJjY3n11VepVKkSOXPmJH/+/DRt2pR169YB4HA4OHPmDFOnTk36GTZp0uSqNV3rdwbS9rP+4osvqF+/PuHh4YSEhFC2bFnuu+++9H8zRSRTKLyKSKbatWsXAAULFrzifWbOnEmHDh0ICwtj1qxZfPLJJ5w4cYImTZqwdu1aAB544AEee+wxAL766ivWr1/P+vXrqV27NvPmzaNs2bLUqlUr6fp58+Zds7YuXbpQoUIFvvzyS/73v/8xc+ZMnnzyyaTbExMTadeuHTNnzuTZZ59l3rx51K9fn1atWl3PtwSA5s2b43Q6WbFiRdJ1y5cvJzg4mGXLliVdt2nTJk6ePEnz5s0BOH/+PE2bNmXatGkMHjyYRYsW0atXL95++206d+6c6s8fHx+f4khISEjX13HhwgXat2/P7bffztdff819993HqFGjeOutt1J8rtatW/Paa6/Rtm1b5s2bx5QpU7j55pvZv38/AOvXryc4OJg2bdok/QzHjRt3xc+bmt+Z5K71s16/fj3dunWjbNmyzJ49m0WLFvHSSy8RHx+fru+LiGQip4hIBpg8ebITcG7YsMF54cIF56lTp5wLFy50FixY0BkaGuqMiopyOp1O5/fff+8EnN9//73T6XQ6ExISnEWLFnVWq1bNmZCQkPR8p06dchYqVMh58803J133zjvvOAHnnj17Lvn8VapUcTZu3PiS6/fs2eMEnJMnT0667uWXX3YCzrfffjvFfR999FFnzpw5nYmJiU6n0+lctGiRE3COHz8+xf1GjBjhBJwvv/xymr8/GzduTLquePHizvvuu8/pdDqdsbGxzly5cjmfffZZJ+Dct2+f0+l0Ot944w1n9uzZnadPn3Y6nU7nhAkTnIDz888/T/H8b731lhNwLl269Kp19O3b1wlcctxyyy1Op/PSn4/L5b6Prue6uJY2bdo4K1asmPTxtGnTnIBz0qRJV60tV65czr59+15y/fX8zqT2Z/3uu+86AefJkyevWqOI2KeeVxHJUA0aNCB79uyEhobStm1bIiIi+O677yhcuPBl779z504iIyPp3bs3AQHuU1Lu3Lnp0qULGzZs4OzZs5lSa/v27VN8XL16dc6fP5/0Vv7q1asBuPvuu1Pcr3v37hny+W+//XaWL18OmMloZ8+eZfDgwRQoUCCp93X58uU0bNgwabLbypUryZUrF3fddVeK53JNVEvek3slwcHBbNy4McXxySefpOtrcDgctGvXLsV11atXTzFM5LvvviNnzpwZ9hZ8en5nrvWzrlevHmB+1p9//nmKFTJExLMovIpIhpo2bRobN25ky5YtREZGsm3bNm655ZYr3v/YsWOAWRXgYkWLFiUxMZETJ05kSq358+dP8XFQUBAA586dS6otW7Zs5MuXL8X9rhTE06p58+bs37+fv//+m+XLl1OrVi0KFSpEs2bNWL58OefOnWPdunVJQwZcNUVEROBwOFI8V6FChciWLVvS9/NqAgICqFu3boqjYsWK6foaQkJCyJkzZ4rrgoKCOH/+fNLHR48epWjRoimC5vVIz+/MtX7Wt912G/Pnzyc+Pp4+ffpQvHhxqlatyqxZszKkZhHJOAqvIpKhKlWqRN26dalZs+Zlw8XFXKHi8OHDl9wWGRlJQEAAefPmzfA6UyN//vzEx8dz/PjxFNdHRUVlyPPffvvtgOldXbZsGS1atEi6fsWKFfzwww/ExsamCK/58+fn33//xel0pniuI0eOEB8fT4ECBa6rJlcQvXjC1X///Zfu5yxYsCCRkZEkJiZeV20umfU706FDB1asWEF0dDSrVq2iePHi9OjR45JJYCJil8KriFhVsWJFihUrxsyZM1MEsjNnzvDll18mzSaHS3vLkgsKCrrs9dejcePGAMyZMyfF9bNnz86Q5y9SpAiVK1fmyy+/ZPPmzUnhtUWLFhw9epT33nuPsLCwpLe0wQTb06dPX7KY/7Rp05Juvx6uVRq2bduW4voFCxak+zlbt27N+fPnr7lRRGp/hmn5nUmPoKAgGjdunDTpbMuWLel+LhHJeFrnVUSsCggI4O2336Znz560bduWhx56iNjYWN555x1OnjzJm2++mXTfatWqATBmzBj69u1L9uzZqVixIqGhoVSrVo3Zs2czZ84cypYtS86cOZPun16tWrXilltu4amnniImJoY6deqwfv36pKCYEW+D33777YwdO5bg4OCk4RVlypShTJkyLF26lPbt25Mtm/tU3adPHz788EP69u3L3r17qVatGmvXrmX48OG0adMmRS9tekRERNC8eXNGjBhB3rx5KVWqFCtWrOCrr75K93N2796dyZMn8/DDD7Nz506aNm1KYmIiP/30E5UqVeKee+4BzM931apVfPPNNxQpUoTQ0NDLDmdIy+9Mar300kscPHiQ22+/neLFi3Py5EnGjBlD9uzZk17EiIhnUM+riFjXo0cP5s+fz7Fjx+jWrRv33nsvYWFhfP/99zRq1Cjpfk2aNOG5557jm2++oVGjRtSrV4/NmzcD8Morr9C4cWP69+/PTTfddMkkovQICAjgm2++4Z577uHNN9+kQ4cOrFmzhhkzZgBcsstXerjCZqNGjVKMHXVdf3EYzZkzJ99//z09e/bknXfeoXXr1kyZMoUhQ4ZcV8BMbvr06dx+++08++yzdO3alUOHDl3X2M9s2bLx7bff8txzzzFv3jw6dOhAnz59WLt2LaVKlUq635gxYyhfvjz33HMP9erV46GHHrric6b2dya16tevT1RUFM8++ywtW7bkwQcfTNqJrEqVKun6ukUkczicFw+cEhGRq5o5cyY9e/bkxx9/5Oabb7ZdjoiIX1F4FRG5ilmzZnHo0CGqVatGQEAAGzZs4J133qFWrVpJS2mJiEjW0ZhXEZGrCA0NZfbs2bz++uucOXOGIkWK0K9fP15//XXbpYmI+CX1vIqIiIiI19CELRERERHxGgqvIiIiIuI1FF5FRERExGv4/IStxMREIiMjCQ0NvWQvcBERERGxz+l0curUKYoWLXrNDWB8PrxGRkZSokQJ22WIiIiIyDUcOHCA4sWLX/U+Ph9eQ0NDAfPNCAsLs1yNiIiIiFwsJiaGEiVKJOW2q/H58OoaKhAWFqbwKiIiIuLBUjPEUxO2RERERMRrKLyKiIiIiNdQeBURERERr+HzY15FxL84nU7i4+NJSEiwXYpcp8DAQLJly6ZlDkUkBYVXEfEZcXFxHD58mLNnz9ouRTJISEgIRYoUIUeOHLZLEREPofAqIj4hMTGRPXv2EBgYSNGiRcmRI4d67LyY0+kkLi6Oo0ePsmfPHsqXL3/NhctFxD8ovIqIT4iLiyMxMZESJUoQEhJiuxzJAMHBwWTPnp19+/YRFxdHzpw5bZckIh5AL2NFxKeod8636OcpIhfTWUFEREREvIbCq4iIiIh4DYVXERG5qnnz5pEtWzYqVKjAkSNHbJcjIn5O4VVERK7o+++/p0ePHrz88ssUKlSIVq1aERMTk+I+e/fu5f7776dMmTIEBwdTrlw5Xn75ZeLi4ixVLSK+TOFVREQua/PmzXTq1In33nuPF198kSVLlpAvXz7at2/P+fPnk+73559/kpiYyMSJE9mxYwejRo1iwoQJPP/88xarFxFfpfAqIj7L6YQzZ+wcTmfqapw2bRr58+cnNjY2xfVdunShT58+mfBdgVWrVpEjRw7WrFmTdN3IkSMpUKAAhw8fBmDnzp20bduW999/n0ceeQSAXLlysWjRIsLCwujWrRvx8fEAtGrVismTJ9OyZUvKli1L+/btGTJkCF999VWm1C8i/s1qeB0xYgT16tUjNDSUQoUK0bFjR3bu3JniPv369cPhcKQ4GjRoYKliEfEmZ89C7tx2jtRu8tW1a1cSEhJYsGBB0nX//fcfCxcu5N57773i46pUqULu3LmveFSpUuWKj23SpAmDBg2id+/eREdH8+uvvzJ06FAmTZpEkSJFAKhYsSKHDx++JEAHBQWxYMECvv76a7Jlu/JS4dHR0eTLly913wQRkTSwuknB6tWrGTBgAPXq1SM+Pp6hQ4fSsmVLfv/9d3LlypV0P9erehdtEygiviI4OJgePXowefJkunbtCsBnn31G8eLFadKkyRUf9+2333LhwoUr3p49e/arft7XX3+d5cuX8+CDD7Jjxw569+5Np06d0vU1XOyff/5h7NixjBw5MkOeT0QkOavhdfHixSk+njx5MoUKFWLz5s3cdtttSdcHBQURERGR1eWlyz//wLx5MHgwaG1tEbtCQuD0aXufO7X69+9PvXr1OHToEMWKFWPy5MlJ7zpdSalSpa6rvhw5cjBjxgyqV69OqVKlGD169HU9n0tkZCStWrWia9euPPDAAxnynCKStZxOGDMGWrWCG2+0Xc2lPGp72OjoaIBL3mpatWoVhQoVIk+ePDRu3Jg33niDQoUKXfY5YmNjU4wdu3hWbGaKjYXatSEmBho0gEaNsuxTi8hlOByQ7E0cj1WrVi1q1KjBtGnTuOOOO9i+fTvffPPNVR9TpUoV9u3bd8XbS5UqxY4dO676HOvWrQPg+PHjHD9+PMU7XukRGRlJ06ZNadiwIR999NF1PZeI2LNtGzz5JPzvf3D0KISG2q4oJY8Jr06nk8GDB9OoUSOqVq2adH3r1q3p2rUrpUqVYs+ePbz44os0a9aMzZs3ExQUdMnzjBgxgldeeSUrS08SFASdOsHUqfDZZwqvIpJ6DzzwAKNGjeLQoUM0b96cEiVKXPX+1zts4J9//uHJJ59k0qRJfP755/Tp04cVK1akezvWQ4cO0bRpU+rUqcPkyZO1rauIF5s501y2bet5wRXA4XSmdk5s5howYACLFi1i7dq1FC9e/Ir3O3z4MKVKlWL27Nl07tz5ktsv1/NaokQJoqOjCQsLy5Tak1u2DFq2hHz54PBh0PBckaxx/vx59uzZQ5kyZciZM6ftctIsJiaGIkWKEB8fz7Rp0+jWrVumfa6EhARuvfVWihQpwpdffklUVBTVqlXjmWee4emnn07z80VGRtK4cWNKlizJtGnTCAwMTLrteod8efvPVcTbJCZCmTKwfz/MnQtdumTN542JiSE8PDxVec0jel4fe+wxFixYwA8//HDV4ApQpEgRSpUqxd9//33Z24OCgi7bI5tVmjWDwoXh339h6VLzqkVE5FrCwsLo0qULixYtomPHjpn6ud544w327t2bNDQhIiKCjz/+mLvvvpsWLVpQs2bNND3f0qVL2bVrF7t27brkHO4h/SMikkrr1pngGhYGbdrYrubyrL6v43Q6GThwIF999RUrV66kTJky13zMsWPHOHDgQNJyLp4mMBDuuce0P/vMbi0i4l0OHz5Mz549M/0F+EsvvURkZCT58+dPuq5Dhw7ExsamObiCWdLQ6XRe9hAR7+IaMtC5MwQH263lSqyG1wEDBjBjxgxmzpxJaGgoUVFRREVFce7cOQBOnz7NkCFDWL9+PXv37mXVqlW0a9eOAgUKZNiSLpmhZ09z+fXXcOqU3VpExPMdP36c2bNns3LlSgYMGGC7HBHxUxcuwOefm3b37nZruRqrwwbGjx8PcMlahq5lYgIDA9m+fTvTpk3j5MmTFClShKZNmzJnzhxCPXEE8f+rWxfKl4e//zYBtlcv2xWJiCerXbs2J06c4K233qJixYq2yxERP7V8ORw7BoUKmWGQnspqeL3WW0rBwcEsWbIki6rJOA4H9OgBr7xihg4ovIrI1ezdu9d2CSIiSUMGunWDq2ygZ53WMskkrqEDy5bBkSN2axERERG5mrNnzSZL4NlDBkDhNdOULw/16kFCgnv8iIiIiIgn+vprOHPGLJPVoIHtaq5O4TUTuXpfteqAiIiIeDJXVunZ0wx/9GQKr5moWzcICIANG+Cff2xXIyIiInKpo0dh8WLTdnW8eTKF10wUEQG3327as2bZrUVERETkcubMMcMc69aFG2+0Xc21KbxmsuRDB7Ret4iIiHia5EMGvIHCaybr1Aly5oQ//4QtW2xXIyJybaVLl2b06NFpftyLL77Igw8+mOr7f/DBB7Rv3z7Nn0dEMs6uXWZ4Y0CAe4dQT6fwmsnCwqBdO9N2rZ8mIuLJNm7cmKYQCvDvv/8yZswYnn/++VQ/pn///mzcuJG1a9emtUQRySCubNKihRnu6A0UXrOAqxt+1iwzpkRExJMVLFiQkJCQND3mk08+oWHDhpQuXTrVjwkKCqJHjx6MHTs2jRWKSEZwOmHGDNP2liEDoPCaJVq3hrx5ITISVq+2XY2IH3E6zcKFNo5UDnKfNm0a+fPnJzY2NsX1Xbp0oU+fPpnxXQFg2LBhlCxZkqCgIIoWLcrjjz+edNvFwwYcDgcff/wxnTp1IiQkhPLly7NgwYIUzzd79uwUQwCOHj1KREQEw4cPT7rup59+IkeOHCxdujTpuvbt2zN//nzOnTuXCV+liFzNxo1mK/uQEDPM0VsovGaBHDngrrtMW0MHRLLQ2bOQO7ed4+zZVJXYtWtXEhISUoTB//77j4ULF3Lvvfde8XFVqlQhd+7cVzyqVKlyxcfOnTuXUaNGMXHiRP7++2/mz59PtWrVrlrnK6+8wt133822bdto06YNPXv25Pjx4wCcOHGC3377jbp16ybdv2DBgnz66acMGzaMTZs2cfr0aXr16sWjjz5Ky5Ytk+5Xt25dLly4wM8//3zN75WIZCzXRK0OHcxpy1t48M61vqVnT5g0CebOhQ8+MJO4RESCg4Pp0aMHkydPpmvXrgB89tlnFC9enCZNmlzxcd9++y0XLly44u3Zs2e/4m379+8nIiKC5s2bkz17dkqWLMlNN9101Tr79etH9//fM3L48OGMHTuWn3/+mVatWrFv3z6cTidFixZN8Zg2bdrQv39/evbsSb169ciZMydvvvlmivvkypWLPHnysHfvXho3bnzVGkQk48THw+zZpt2rl91a0krhNYvceiuUKAEHDsC330LnzrYrEvEDISFw+rS9z51K/fv3p169ehw6dIhixYoxefJk+vXrh+Mq29yUKlUq3aV17dqV0aNHU7ZsWVq1akWbNm1o164d2bJd+V9C9erVk9q5cuUiNDSUI0eOACS95Z/zMq/K3333XapWrcrnn3/Opk2bLnuf4OBgzqayp1pEMsby5XDkCBQsaCZreRMNG8giAQHw/50WGjogklUcDsiVy86Rhv0Va9WqRY0aNZg2bRq//PIL27dvp1+/fld9zPUMGyhRogQ7d+7kww8/JDg4mEcffZTbbrstTT25DoeDxMREAAoUKACY4QMX2717N5GRkSQmJrJv377LPvfx48cpWLDgVb9eEclYrola3brBVd6o8Ujqec1CPXrA22/DwoUQHQ3h4bYrEhFP8cADDzBq1CgOHTpE8+bNKVGixFXvfz3DBsD0drZv35727dszYMAAbrzxRrZv307t2rXTXHu5cuUICwvj999/p0KFCknXx8XF0bNnT7p168aNN97I/fffz/bt2ylcuHDSff755x/Onz9PrVq10vx5RSR9Tp+GefNM29uGDIDCa5aqXh2qVIEdO+DLL+G++2xXJCKeomfPngwZMoRJkyYxbdq0a97/eoYNTJkyhYSEBOrXr09ISAjTp08nODg43c8ZEBBA8+bNWbt2LR07dky6fujQoURHR/P++++TO3duvvvuO+6//34WLlyYdJ81a9ZQtmxZypUrl+6vR0TS5uuvzZzSG26Aawx390gaNpCFHI6U28WKiLiEhYXRpUsXcufOnSIAZoY8efIwadIkbrnlFqpXr86KFSv45ptvyJ8/f7qf88EHH2T27NlJQwlWrVrF6NGjmT59OmFhYQQEBDB9+nTWrl3L+PHjkx43a9Ys+vfvf91fk4ikXvK1XdMwwsljOJzOVC5G6KViYmIIDw8nOjqasLAw2+Wwbx+ULm1+WfbtM5O4ROT6nT9/nj179lCmTJnLTgryBi1atKBSpUq8//77tktJM6fTSYMGDRg0aFDSqgTX8ttvv3H77bfz119/EX6FcVS+8HMV8ST//gtFi0JiIvz1F5Qvb7siIy15TT2vWaxUKWjSxKxfrt5XEQEzYWn27NmsXLmSAQMG2C4nXRwOBx999BHx8fGpfkxkZCTTpk27YnAVkYw3Z44JrvXre05wTSuNebWgd29YtQqmT4dnn/XOLnsRyTi1a9fmxIkTvPXWW1SsWNF2OelWo0YNatSoker7J9+sQESyhjduB3sxhVcL7roLBgyA33+HX36BOnVsVyQiNu3du9d2CSLiB/76y2wJGxholsjyVho2YEFYGLjmY6RiUrGIiIjIdXMNV2zZEgoVslvL9VB4taRPH3M5axZcZalGEUkjH5+D6nf08xTJGE6ne8iAN67tmpzCqyUtWkDhwnD0KCxZYrsaEe/nWpRf24z6FtfP81qbLojI1f30E+zebTYA7NDBdjXXR2NeLcmWzey4NWqUmbjVtq3tikS8W2BgIHny5OHIkSMAhISE4NBsSK/ldDo5e/YsR44cIU+ePAQGBtouScSrTZ9uLjt1MgHWm2mdV4u2bIHatSEoCKKiIE8e2xWJeDen00lUVBQnT560XYpkkDx58hAREaEXIiLXITYWihSBEydg6VLz7q+nSUteU8+rRTVrQtWq8NtvMHcuPPCA7YpEvJvD4aBIkSIUKlSICxpM7vWyZ8+uHleRDLBokQmuxYpBs2a2q7l+Cq8WORxmzddnnzWrDii8imSMwMBAhR4Rkf83daq57NXLLJPl7TRhyzLXvsJr1sCePbarEREREV9y9Ch8+61pu1Y68nYKr5YVKwa3327ariUsRERERDLCrFkQHw9160LlyraryRgKrx7A9Upo2jSzDpuIiIhIRnBthtS3r906MpLCqwfo1AlCQmDXLrMOm4iIiMj12rEDNm+G7NnhnntsV5NxFF49QO7c0KWLaWu7WBEREckIrkxx551QoIDdWjKSwquH6N3bXM6ZY9ZjExEREUmvhAT3XBpfmajlovDqIZo1g6JF4fhx96xAERERkfRYvhwiIyFfPtPz6ksUXj1EYKBZNgvcW7iJiIiIpIdryED37pAjh91aMprCqwdxdesvXAjHjtmtRURERLxTTAzMm2favrTKgIvCqwepWtVsGXvhAnz+ue1qRERExBvNnQvnzsGNN5r1XX2NwquHSb7mq4iIiEhaubaD7dvX7OLpaxRePUz37hAQABs2wF9/2a5GREREvMmePfDDDya09uplu5rMofDqYSIioFUr03a9chIRERFJDdek79tvh+LF7daSWRRePVC/fuZy6lSzTpuIiIjItTid7mGHvra2a3IKrx6ofXvImxcOHYIVK2xXIyIiIt5g3Tr45x+zc2fnzraryTwKrx4oKAh69DDtyZPt1iIiIiLewdXretddkCuX3Voyk8Krh7r3XnM5bx6cOGG3FhEREfFs586ZLebBt4cMgMKrx6pd26z7Ghvr/mUUERERuZwFCyA6GkqWhMaNbVeTuRRePZTD4e591dABERERuRrXkIHevc2Sm77Mx78879arF2TLBj//DL//brsaERER8USHD8OSJabt60MGQOHVoxUqBG3amPaUKVZLEREREQ81bZpZWvPmm6FCBdvVZD6FVw/nGjowfTrEx9utRURERDyL0+keXnjffXZrySoKrx6uTRsoUACiotxvCYiIiIgArF8PO3dCSAjcfbftarKGwquHy5HDvTexJm6JiIhIcp9+ai67doXQULu1ZBWFVy/gGjqwYAEcO2a3FhEREfEMZ864l9P0lyEDoPDqFapXh1q14MIFmDnTdjUiIiLiCebOhdOn4YYb4NZbbVeTdRRevYSr91WrDoiIiAi4hwz062fWh/cXCq9eont3yJ4dfvkFtm2zXY2IiIjYtGsX/PCDCa19+9quJmspvHqJAgWgfXvT1sQtERER/+Z6J7ZlSyhe3GopWU7h1Yu4hg7MmAFxcXZrERERETsSEmDqVNP2p4laLgqvXuSOOyAiAv77D7791nY1IiIiYsPy5XDwIOTLBx062K4m6ym8epFs2aB3b9PWxC0RERH/5Jqo1aMHBAXZrcUGhVcv06+fuVy0CI4csVqKiIiIZLHjx2H+fNP2xyEDoPDqdSpXhptugvh4M/ZVRERE/MfMmWbeS40aZg14f6Tw6oVcE7c+/RScTru1iIiISNZxDRnw115XUHj1SvfcA8HBsGMH/PST7WpEREQkK2zdClu2QI4c0LOn7WrsUXj1QnnyQNeupv3JJ1ZLERERkSziWue9fXvIn99uLTYpvHqpBx4wl7NmwalTdmsRERGRzBUb657r4s9DBkDh1Ws1agQVKsCZM/D557arERERkcz0zTdmpYFixcyuWv5M4dVLORxw//2m/fHHdmsRERGRzOWaqNWnDwQG2q3FNoVXL9anj9m4YMMG+O0329WIiIhIZjh0CJYsMW3XikP+TOHVi0VEQLt2pq2JWyIiIr5p6lRITDRDBsuXt12NfVbD64gRI6hXrx6hoaEUKlSIjh07snPnzhT3cTqdDBs2jKJFixIcHEyTJk3YsWOHpYo9j2vi1rRpZjC3iIiI+I7ERPfwQNdwQX9nNbyuXr2aAQMGsGHDBpYtW0Z8fDwtW7bkzJkzSfd5++23ee+99/jggw/YuHEjERERtGjRglOaYg/AHXeYwdvHj8PXX9uuRkRERDLSypWwZw+EhbmXyfR3VsPr4sWL6devH1WqVKFGjRpMnjyZ/fv3s3nzZsD0uo4ePZqhQ4fSuXNnqlatytSpUzl79iwzZ8687HPGxsYSExOT4vBlgYHuJTM0cUtERMS3uP639+wJuXLZrcVTeNSY1+joaADy5csHwJ49e4iKiqJlsjUhgoKCaNy4MevWrbvsc4wYMYLw8PCko0SJEplfuGWuwdvLlplXZyIiIuL9/vsP5s0z7f797dbiSTwmvDqdTgYPHkyjRo2oWrUqAFFRUQAULlw4xX0LFy6cdNvFnnvuOaKjo5OOAwcOZG7hHqBMGWje3LRdu2+IiIiId5s+HeLioHZtqFXLdjWew2PC68CBA9m2bRuzZs265DaHw5HiY6fTecl1LkFBQYSFhaU4/IFr4tann0JCgt1aRERE5Po4nTBpkmmr1zUljwivjz32GAsWLOD777+nePHiSddHREQAXNLLeuTIkUt6Y/1dx46QL1/KteBERETEO61bB3/8ASEh0KOH7Wo8i9Xw6nQ6GThwIF999RUrV66kTJkyKW4vU6YMERERLFu2LOm6uLg4Vq9ezc0335zV5Xq0oCCzaQFozVcRERFv55qodffdZqUBcbMaXgcMGMCMGTOYOXMmoaGhREVFERUVxblz5wAzXGDQoEEMHz6cefPm8dtvv9GvXz9CQkLooZchl3Ct/7ZgAfz7r91aREREJH2io2HOHNPWkIFLWQ2v48ePJzo6miZNmlCkSJGkY47rJwY888wzDBo0iEcffZS6dety6NAhli5dSmhoqMXKPVPVqtCgAcTHm00LRERExPvMnAnnzkHlytCwoe1qPI/D6XQ6bReRmWJiYggPDyc6OtovJm99/LF5lVahAvz5J1xhXpuIiIh4qDp14JdfYNQoGDTIdjVZIy15zSMmbEnG6dbNLGL811+wdq3takRERCQtfvnFHDlyQK9etqvxTAqvPiY0FO65x7S145aIiIh3cS2P1bkzFChgtxZPpfDqg1xrvn7xBZw8abUUERERSaUzZ8x4V9BEratRePVB9etDlSpmsPeMGbarERERkdT44guIiYFy5aBJE9vVeC6FVx/kcMBDD5n2xIlmlw4RERHxbK4hA/ffDwFKaFekb42P6t0bgoPht99g/Xrb1YiIiMjV/P672VUrMBD69bNdjWdTePVRefKYlQfA9L6KiIiI53L1urZtC0WK2K3F0ym8+jDX0IHPP4cTJ+zWIiIiIpd37hxMnWrarv/dcmUKrz6sfn2oXh3On9eOWyIiIp7qiy9MJ1Pp0tCype1qPJ/Cqw/TxC0RERHP5xre17+/GfMqV6fw6uN69oSQEPjjD+24JSIi4mm2bTMTtbJlg/vus12Nd1B49XHh4e4dtzRxS0RExLO4/jd37AgREVZL8RoKr37ANXRg7lw4dsxuLSIiImKcPg3Tp5v2ww/brcWbKLz6gXr1oGZNiI11z2YUERERu2bPhlOnoHx5aNrUdjXeQ+HVDySfuPXRR5q4JSIi4glcQwYefFA7aqWFvlV+okcPyJULdu6E1attVyMiIuLfNm0yR44c2lErrRRe/URYmAmwoIlbIiIitrn+F991FxQoYLcWb6Pw6kdcQwe+/BKOHrVbi4iIiL+KjoZZs0xbE7XSTuHVj9SpY44LF2DKFNvViIiI+KfPPoMzZ6BSJWjUyHY13kfh1c8kn7iVmGi3FhEREX/jdMKECab98MNmUrWkjcKrn+neHUJDYdcuWLnSdjUiIiL+ZcMG2L4dgoOhd2/b1XgnhVc/kzu3+49l/Hi7tYiIiPgbV69rt26QN6/dWryVwqsfeuQRc/n113DwoN1aRERE/MXx4/D556atiVrpp/Dqh6pWhdtug4QEmDTJdjUiIiL+Ydo0OH8eatSAm26yXY33Unj1UwMGmMuPPjKrD4iIiEjmSUyEceNMWxO1ro/Cq5/q2BEiIiAqCubPt12NiIiIb1uxAv7+20ya7tXLdjXeTeHVT+XIAf37m7brlaCIiIhkjg8/NJd9+5rJ05J+Cq9+7MEHITAQVq2C33+3XY2IiIhv2r8fvvnGtB991G4tvkDh1Y8VLw7t25u2ls0SERHJHBMnmjGvzZqZXbXk+ii8+jnXK8CpU+H0abu1iIiI+JrYWPfKPq7J0nJ9FF79XLNmUKECnDoFM2bYrkZERMS3zJ0LR49CsWLudzvl+ii8+rmAAPemBePGmT2XRUREJGO4JkU/9BBky2a3Fl+h8Cr07Wv2WN6+HX780XY1IiIivmHrVli3zoRW1wo/cv0UXoW8eaFHD9PWslkiIiIZw7U8VpcuZm11yRgKrwK4J27NnQv//mu3FhEREW938iR89plpa6JWxlJ4FQBq14b69c1WsZ98YrsaERER7zZlCpw7B9WqQaNGtqvxLQqvksTV+zphAiQk2K1FRETEWyUmuofhPfooOBx26/E1Cq+S5O67IX9+OHAAFi60XY2IiIh3Wr4c/v4bwsKgVy/b1fgehVdJkjMnPPCAaY8da7cWERERb+Xqde3bF3LntluLL1J4lRQeecSs/bpiBezYYbsaERER77J/P3zzjWm7huNJxlJ4lRRKlYIOHUz7gw/s1iIiIuJtJkwwY16bNYMbb7RdjW9SeJVLPP64uZw2zSz1ISIiItd27hx89JFpa3mszKPwKpdo3BiqVoWzZ+HTT21XIyIi4h1mz4Zjx8y7mO3b267Gdym8yiUcDnfv64cfatksERGRa3E64f33TXvAALMlrGQOhVe5rJ49zbaxu3fDd9/ZrkZERMSzrV0LW7dCcDDcf7/tanybwqtcVkiI+4/P9UpSRERELs/1v7J3b8iXz24tvk7hVa5owACzbNayZfDnn7arERER8Uz798O8eab92GN2a/EHCq9yRaVLQ7t2pq1ls0RERC5v/HgzP6RZMzPhWTKXwqtclesV5JQpEB1ttRQRERGPk3x5LPW6Zg2FV7mqZs2gcmU4c8YEWBEREXGbOROOHzfLY7nerZTMpfAqV+VwuF9JfvCB2TVEREREUi6PNXAgBAbarcdfKLzKNfXqBeHhsGsXLF5suxoRERHP8MMPsG1byhV6JPMpvMo15c7t/qMcO9ZuLSIiIp4i+fJYefParcWfKLxKqgwYYIYQLF4Mf/1luxoRERG79u2D+fNNWxO1spbCq6RK2bLQtq1pa9MCERHxd+PGmXkgt98OVarYrsa/KLxKqg0aZC4nT4YTJ6yWIiIiYs3ZszBpkmk//rjdWvyRwqukWtOmUL16yj9aERERf/PZZ6YTp0wZuPNO29X4H4VXSTWHw937OnYsXLhgtRwREZEs53TCmDGmPWCAlseyQeFV0qR7dyhUCA4ehK++sl2NiIhI1lq2DHbsMCvxPPCA7Wr8k8KrpEnOnPDoo6Y9apTdWkRERLLae++Zy/vvN2ugS9ZTeJU0e+QRyJEDfvoJ1q+3XY2IiEjW2LEDliwxw+g0UcsehVdJs0KFoGdP01bvq4iI+IvRo81lp05mCUmxQ+FV0uXJJ83ll1+ahZpFRER82dGjMH26aQ8ebLcWf6fwKulSrZpZmDkxET74wHY1IiIimWv8eIiNhXr14OabbVfj3xReJd1cva+TJsHp03ZrERERySznz8OHH5r24MFmzKvYo/Aq6da6NVSoANHRZtctERERXzRrFhw5AsWLQ5cutqsRhVdJt4AAeOIJ0x4zBhIS7NYjIiKS0ZxO9+Tkxx+H7Nnt1iMKr3Kd+vaFvHnhn39g4ULb1YiIiGSsFStg+3bIlQv697ddjYDCq1ynXLngwQdN27WEiIiIiK9w9bredx/kyWO1FPl/VsPrDz/8QLt27ShatCgOh4P58+enuL1fv344HI4UR4MGDewUK1c0cKDZ23nVKtiyxXY1IiIiGeOPP+Dbb80ELdcwObHPang9c+YMNWrU4IOrrLXUqlUrDh8+nHR8++23WVihpEbx4tC1q2mPHGm3FhERkYwyZoy57NABypWzW4u4ZbP5yVu3bk3r1q2vep+goCAiIiKyqCJJryFDYPZsc4wYASVK2K5IREQk/f77D6ZONW3X0pDiGTx+zOuqVasoVKgQFSpUoH///hw5cuSq94+NjSUmJibFIZmvTh1o2tSsOOB6pSoiIuKtJkww67vWqQO33mq7GknOo8Nr69at+eyzz1i5ciUjR45k48aNNGvWjNjY2Cs+ZsSIEYSHhycdJdQFmGWGDDGXH31k1n4VERHxRufPu3ePfPJJbUrgaRxOp9NpuwgAh8PBvHnz6Nix4xXvc/jwYUqVKsXs2bPp3LnzZe8TGxubItzGxMRQokQJoqOjCQsLy+iyJRmnE6pWhd9/h7ffhqeftl2RiIhI2k2aZFbSKVHCLAWptV0zX0xMDOHh4anKax7d83qxIkWKUKpUKf7+++8r3icoKIiwsLAUh2QNh8Pd+zpmDMTF2a1HREQkrRIT3ZOPn3xSwdUTeVV4PXbsGAcOHKBIkSK2S5Er6NEDihSBQ4fM5C0RERFv8s03sHMnhIfDAw/YrkYux2p4PX36NFu3bmXr1q0A7Nmzh61bt7J//35Onz7NkCFDWL9+PXv37mXVqlW0a9eOAgUK0KlTJ5tly1UEBZnt8wDefdcMJRAREfEW77xjLh95BEJD7dYil2d1zOuqVato2rTpJdf37duX8ePH07FjR7Zs2cLJkycpUqQITZs25bXXXkvTJKy0jKGQjHHypBkndPo0LF4Md9xhuyIREZFrW7cObrkFcuSAvXvNO4mSNdKS16yu89qkSROulp2XLFmShdVIRsmTx7zVMnq0eQWr8CoiIt7A1evaq5eCqyfzqjGv4j0GDTJbxq5YoS1jRUTE8/31F3z9tWm7Jh+LZ1J4lUxRqhTcfbdpv/uu3VpERESuZeRIM0+jXTuoVMl2NXI1Cq+SaVyvXOfMgf377dYiIiJyJf/+694KVmuUez6FV8k0tWtDs2Zmy9jRo21XIyIicnljx0JsLNSvD40a2a5GrkXhVTKV6xXspElmFQIRERFPcvo0jBtn2s88o61gvYHCq2SqO+4wW8aePg0TJtiuRkREJKVPP4UTJ+CGG6BDB9vVSGoovEqmcjjcva+jR8O5c1bLERERSRIfD++9Z9pPPWVWyRHPp/Aqma57dyhZMuWAeBEREdu++AL27YOCBaFvX9vVSGopvEqmy57dvfLAO++YV7oiIiI2OZ3uTQkGDoTgYLv1SOopvEqWuP9+KFAAdu82r3RFRERsWrLEbKKTKxcMGGC7GkkLhVfJEiEh8MQTpv3mm+YVr4iIiC0jRpjLBx+E/Pnt1iJpo/AqWWbAAMidG7Ztg8WLbVcjIiL+6scf4YcfzLC2wYNtVyNppfAqWSZvXnjoIdN2veIVERHJaq7/QX36QPHidmuRtFN4lSw1eDDkyAFr1phXviIiIllp2zZYtAgCAuDZZ21XI+mh8CpZqmhR80oXzNhXERGRrOT633PXXVC+vN1aJH0UXiXLPf202bxg4ULYvt12NSIi4i/++QfmzDHt//3Pbi2SfgqvkuUqVDCveAHefttuLSIi4j/eeQcSE6FVK6hVy3Y1kl4Kr2KF6xXvrFmwZ4/dWkRExPdFRsLkyab9/PN2a5Hro/AqVtSuDS1bQkICjBxpuxoREfF1o0ZBXBzccgvceqvtauR6KLyKNa7e108+gSNH7NYiIiK+68QJmDDBtJ97zm4tcv0UXsWaJk3gppvg/HkYPdp2NSIi4qs++ABOn4bq1aFNG9vVyPVSeBVrHA73uKMPPjCvjEVERDLSmTMwZoxpP/ec+d8j3k3hVaxq1w6qVYNTp+D9921XIyIivubjj+HYMShXzr3SjXg3hVexKiAAXnjBtEePhpgYq+WIiIgPiY2Fd9817WeegWzZ7NYjGSNDwuvJkycz4mnET3XpAjfeCCdPwrhxtqsRERFfMWUKHDwIxYpB3762q5GMkubw+tZbbzHHtT0FcPfdd5M/f36KFSvGr7/+mqHFiX8IDHSPfR050oxPEhERuR4XLsCIEab9zDMQFGS3Hsk4aQ6vEydOpESJEgAsW7aMZcuW8d1339G6dWuefvrpDC9Q/EP37lC2LPz3H0ycaLsaERHxdtOnw759ULgw9O9vuxrJSGkOr4cPH04KrwsXLuTuu++mZcuWPPPMM2zcuDHDCxT/kC2be+29d94xy2eJiIikR3w8vPGGaT/9NAQH261HMlaaw2vevHk5cOAAAIsXL6Z58+YAOJ1OEhISMrY68St9+kDJkhAVZTYuEBERSY9Zs2D3bihQAB5+2HY1ktHSHF47d+5Mjx49aNGiBceOHaN169YAbN26lRtuuCHDCxT/kSMHPPusab/1ltnGT0REJC0SEuD11037qacgVy679UjGS3N4HTVqFAMHDqRy5cosW7aM3LlzA2Y4waOPPprhBYp/ue8+KFIEDhyAadNsVyMiIt7miy/gr78gXz4YMMB2NZIZHE6n02m7iMwUExNDeHg40dHRhIWF2S5HUmHUKBg82Ezg2rlT6/KJiEjqJCaaLWB37IBXX4UXX7RdkaRWWvJaqsLrggULaN26NdmzZ2fBggVXvW/79u3TVm0mU3j1PmfOQJkycPQoTJ1qxsKKiIhcy5dfml20wsNh717Ik8d2RZJaGR5eAwICiIqKolChQgQEXHmkgcPh8LhJWwqv3unNN83qAxUrmlfQgYG2KxIREU/mdEKtWvDrr6bH9dVXbVckaZGWvJaqMa+JiYkUKlQoqX2lw9OCq3ivRx+FvHnNsIG5c21XIyIinu6bb0xwzZ0bBg2yXY1kpgzZHtbl7NmzGfl04sfCwuCJJ0z71VfN7FEREZHLcTrdPa0DB5rJWuK70hxemzRpwsGDBy+5/qeffqJmzZoZUZMIYMJreDj8/ruZPSoiInI5ixfD5s0QEmIm/IpvS3N4DQsLo3r16syePRswwwiGDRvGbbfd5nGTtcS75clj1ugDeOUV9b6KiMilkve6PvIIFCxotx7JfOlaKmvChAkMGTKE9u3bs3fvXvbv38+UKVOSdtvyJJqw5d1iYqB0aThxAj77DHr0sF2RiIh4ksWLoXVryJkT9uyBiAjbFUl6ZPiErYs9/PDDPPbYY8yePZtNmzbx+eefe2RwFe8XFubufdXYVxERSc7phJdeMu0BAxRc/UWaw+uJEyfo0qUL48ePZ+LEidx99920bNmScePGZUZ9Ijz2mBl8v3On2a9aREQEYNEi2LjRjHV95hnb1UhWSXN4rVq1Kv/++y9btmyhf//+zJgxg08++YQXX3yRO++8MzNqFD8XFgZDhpj2q69CfLzdekRExL7kva6PPQb/v6Kn+IE0h9eHH36YH374gTJlyiRd161bN3799Vfi4uIytDgRl4EDIX9++PtvmDnTdjUiImLb11/Dli1mXVdXB4f4h3RN2PImmrDlO956C/73PyhXDv78E7Jls12RiIjYkJhodtPatg2GDoXXX7ddkVyvDN8e9nLOnj3L/v37L+ltrV69enqeLtMovPqO06ehbFk4ehQ+/RTuvdd2RSIiYsPcudC1qxlWtmePNiXwBWnJa2nuuzp69Cj33nsv33333WVv1xaxklly5zYD8p9+Gl57DXr1guzZbVclIiJZKSEBXn7ZtJ98UsHVH6V5zOugQYM4ceIEGzZsIDg4mMWLFzN16lTKly/PggULMqNGkSSPPGIG5e/ZA9Om2a5GRESy2hdfmJ0X8+SBQYNsVyM2pDm8rly5klGjRlGvXj0CAgIoVaoUvXr14u2332bEiBGZUaNIkly54NlnTfv110FzBEVE/EdCAgwbZtpDhpgAK/4nzeH1zJkzFPr/9Sjy5cvH0aNHAahWrRq//PJLxlYnchkPPwyFC8PevTB1qu1qREQkq8yaZdb8zpcPHn/cdjViS5rDa8WKFdm5cycANWvWZOLEiRw6dIgJEyZQpEiRDC9Q5GIhIfDcc6b92mtw/rzdekREJPPFx8Mrr5j2M89AaKjdesSedI15PXz4MAAvv/wyixcvpmTJkrz//vsMHz48wwsUuZyHHoLixeHAAZg40XY1IiKS2WbMgF27oGBBsxWs+K/rXuf17Nmz/Pnnn5QsWZICBQpkVF0ZRktl+a5Jk+DBB82JbPdusxqBiIj4nrg4uPFGM1n33XfhqadsVyQZLS15Lc09r8n9+OOPBAYGUrt2bY8MruLb+vWDG24w676OGWO7GhERySwff2yCa0SEWXVG/Nt1hdfWrVtz6NChjKpFJE2yZ4dXXzXtd96B48ft1iMiIhnvzBkzvwHgxRfNvAfxb9cVXn18Z1nxAt26QbVqEB1tAqyIiPiWsWMhKgrKlIEHHrBdjXiC6wqvIrYFBMAbb5j2mDHmBCciIr7hxAl46y3TfvVVyJHDbj3iGdIcXvv168cPP/wAwMSJEylcuHCGFyWSFm3bQoMGcO6cO8iKiIj3e+cdOHkSqlSB7t1tVyOeIs3h9dSpU7Rs2ZLy5cuzZ88eTp48mQlliaSewwGuVdomTjSbF4iIiHeLinJPxn3jDQgMtFuPeI40h9cvv/ySQ4cOMXDgQObOnUvp0qVp3bo1c+fO5cKFC5lRo8g1NW0KzZvDhQvuRaxFRMR7vf46nD1r3llr3952NeJJrnud1y1btvDpp5/y8ccfkzt3bnr16sWjjz5K+fLlM6rG66J1Xv3Hzz9D/fpmHOxvv0GlSrYrEhGR9NizBypWNB0SK1eaDgrxbVm2zuvhw4dZunQpS5cuJTAwkDZt2rBjxw4qV67MqFGjruepRdLsppugY0dITISXXrJdjYiIpNfLL5vg2qKFgqtcKs09rxcuXGDBggVMnjyZpUuXUr16dR544AF69uxJ6P9vNDx79mweeeQRTpw4kSlFp4V6Xv3Lb79B9ergdMKmTVCnju2KREQkLZKfxzduhLp1bVckWSEteS1bWp+8SJEiJCYm0r17d37++Wdq1qx5yX3uuOMO8uTJk9anFrluVatCz55mD+znn4clS2xXJCIiafHCCya4dumi4CqXl+ae1+nTp9O1a1dy5syZWTVlKPW8+p/du80e2BcuwLJlZiKXiIh4vvXr4eabNXfBH2XqmNfevXt7TXAV/1S2rHvv62eeMWNgRUTEszmd5h0zgL59FVzlyrTDlvikF16A0FDYsgVmz7ZdjYiIXMuSJbBqldlF6+WXbVcjnkzhVXxSwYLwv/+Z9tChEBtrtx4REbmyhAR4+mnTfuwxKFXKbj3i2RRexWcNGgRFi5odt8aNs12NiIhcybRpZoxrnjzuoQMiV6LwKj4rJMS929brr5v9sUVExLOcPQsvvmjaQ4dCvnx26xHPp/AqPq1fPzPo//hxeOst29WIiMjFRo+GQ4fMUIGBA21XI97Aanj94YcfaNeuHUWLFsXhcDB//vwUtzudToYNG0bRokUJDg6mSZMm7Nixw06x4pWyZYM33zTt0aPh4EGr5YiISDJHj7rP0W+8AVrMSFLDang9c+YMNWrU4IMPPrjs7W+//TbvvfceH3zwARs3biQiIoIWLVpw6tSpLK5UvFm7dnDrrXD+vLaNFRHxJK+9BqdOQe3a0L277WrEW6R5k4LM4nA4mDdvHh07dgRMr2vRokUZNGgQzz77LACxsbEULlyYt956i4ceeihVz6tNCgRgwwZo2NAsfP3rr2YnLhERsefvv6FyZYiPhxUroFkz2xWJTZm6SUFW2bNnD1FRUbRs2TLpuqCgIBo3bsy6deuu+LjY2FhiYmJSHCINGpitBhMT3UtoiYiIPc8/b4Jr69YKrpI2Hhteo6KiAChcuHCK6wsXLpx02+WMGDGC8PDwpKNEiRKZWqd4j+HDITAQFi0yC2GLiIgdGzbA3Lnm3TBNppW08tjw6uJwOFJ87HQ6L7kuueeee47o6Oik48CBA5ldoniJChXANdrk6ae1bayIiA1OJwwZYtr9+kG1albLES/kseE1IiIC4JJe1iNHjlzSG5tcUFAQYWFhKQ4Rl5deMtvGbtoEn31muxoREf/z9dfw448QHOxei1skLTw2vJYpU4aIiAiWLVuWdF1cXByrV6/m5ptvtliZeLPChd27tzz3HJw5Y7ceERF/cuGCe97Bk09C8eJ26xHvZDW8nj59mq1bt7J161bATNLaunUr+/fvx+FwMGjQIIYPH868efP47bff6NevHyEhIfTo0cNm2eLlBg2C0qXNotjvvmu7GhER/zFxIuzcCQUKwP8vJCSSZlaXylq1ahVNmza95Pq+ffsyZcoUnE4nr7zyChMnTuTEiRPUr1+fDz/8kKppWOdIS2XJ5Xz+OXTrZraQ/esvKFbMdkUiIr7t+HEoX95cjh8PDz9suyLxJGnJax6zzmtmUXiVy3E6zcYFP/4IffvClCm2KxIR8W2DBsGYMWad7S1bzA6IIi4+sc6rSGZyOGDUKNOeOhU2b7Zbj4iIL/vzT/jwQ9N+7z0FV7k+Cq/it+rVg169TPvJJ01vrIiIZLwhQ8yGBO3aQYsWtqsRb6fwKn5txAizXMuaNfDVV7arERHxPUuWmM1hsmfXJFnJGAqv4teKFzcbFgA88wzExtqtR0TEl8THw+DBpv3YY2azGJHrpfAqfu/pp6FIEdi9G95/33Y1IiK+46OP4PffIX9+ePFF29WIr1B4Fb+XOzcMH27ar78OR47YrUdExBecOGF2NQR47TXIk8dqOeJDFF5FgD59oHZtiImBl1+2XY2IiPd77TU4dgyqVIH+/W1XI75E4VUECAhwL5310Ufw66926xER8WZ//QVjx5r2qFFaGksylsKryP+77Taz61ZioplYoKWzRETSx7U0Vtu2WhpLMp7Cq0gy775rtoxdswZmzbJdjYiI91myBL75xvS2amksyQwKryLJFC8OQ4ea9tNPw+nTdusREfEmsbHmnSswlxUr2q1HfJPCq8hFBg+GsmUhMtKsPiAiIqkzejT8/TcULgzDhtmuRnyVwqvIRXLmNCdgMHtw//WX1XJERLzCwYNmhQGAd96BsDC79YjvUngVuYy2baF1a7hwAQYN0uQtEZFrGTIEzpyBRo2gVy/b1YgvU3gVuQyHw/S+Zs8O330HCxfarkhExHN9/z3MmWOWHRw71pxDRTKLwqvIFVSo4N6Te9AgOH/eajkiIh7pwgUYONC0H3kEata0Wo74AYVXkat44QUoWhR279aSLyIil/PBB/D771CggHvMq0hmUngVuYrcuc3EA4Dhw2H/frv1iIh4kqgo95bab74JefParUf8g8KryDV07w633grnzpkJCSIiYjzzDJw6BfXqwb332q5G/IXCq8g1OBxmAkJAAHzxBSxdarsiERH71q6F6dPNOfLDD805UiQr6FdNJBVq1HDvGvPoo6YXVkTEXyUkuCdp3X+/6XkVySoKryKp9OqrZvLWP/+YsV0iIv7qww/h11/NGNcRI2xXI/5G4VUklcLCYMwY037zTe28JSL+6eBBGDrUtIcPN6sMiGQlhVeRNOjSBVq1grg4M3xAO2+JiL954gk4fRoaNoQHH7RdjfgjhVeRNHA4zJqGOXPCihUwa5btikREss7ChfDVVxAYCBMmaJKW2KFfO5E0KlfObF4A8OSTcPKk1XJERLLEmTMwYIBpDx4M1avbrUf8l8KrSDoMGQIVK8KRI+6xXyIivuyVV8xGLaVKuTcmELFB4VUkHYKCYPx40x4/Hn7+2W49IiKZads2eO890/7gA8iVy2494t8UXkXSqWlT6N3bTNp6+GGIj7ddkYhIxktMhIceMmu7du4Mbdvarkj8ncKryHV4913Ikwe2bIFx42xXIyKS8SZNgg0bIHdu93KBIjYpvIpch0KF3BsWDB0KBw7YrUdEJCP9+y/873+m/frrULy43XpEQOFV5Lr17w8332zWPXzkEa39KiK+Y/Bgs6JK7dru7WBFbFN4FblOAQHw8ceQIwcsWgSzZ9uuSETk+i1dCjNnmnPcRx+ZtV1FPIHCq0gGqFTJvfbr44/Df//ZrUdE5HqcPu3ePWvgQKhTx249IskpvIpkkGefhapVTXB98knb1YiIpN8LL8C+fWZN1zfesF2NSEoKryIZJEcO+OQT8xbbjBnw3Xe2KxIRSbv16+H99037o4/MKgMinkThVSQD3XQTPPGEaT/0EJw6ZbceEZG0iI2F++83E0/79oWWLW1XJHIphVeRDPbaa1CmjFk26/nnbVcjIpJ6b7wBf/xhlgF07agl4mkUXkUyWK5c5q02gA8/hHXr7NYjIpIa27bBiBGm/eGHkC+f3XpErkThVSQTNG8O/fqZt94eeMC8FSci4qni481wgfh46NQJunSxXZHIlSm8imSSkSOhcGHzFpxm64qIJxszBjZtgvBw+OADcDhsVyRyZQqvIpkkXz4YO9a0R4yArVutliMicll//QUvvmjaI0dC0aJ26xG5FoVXkUx0113QubN5K65vX4iLs12RiIhbQoIZ4nTunBnudN99tisSuTaFV5FM5HDA+PFQoICZDPH667YrEhFxGzXKrOsaGmrWqdZwAfEGCq8imaxQIRg3zrSHD4fNm+3WIyICZjy+a1vrUaOgZEm79YiklsKrSBbo2hXuvtu8Rde3r1YfEBG74uPNcIHYWGjdWsMFxLsovIpkkQ8/NL2wO3bAK6/YrkZE/Nm778LPP5vVBSZN0nAB8S4KryJZpEABmDDBtN96y/zjEBHJar/9Bi+/bNrvvw/FitmtRyStFF5FslCnTtCzJyQmmuED58/brkhE/MmFC+6VT9q1g969bVckknYKryJZ7P33oUgR+PNP92QJEZGsMGIE/PIL5M0LEydquIB4J4VXkSyWL58ZYwbw3nuwapXVckTET/z8M7z6qml/8IF5ES3ijRReRSy4807o3x+cTujTB06etF2RiPiyM2egVy+z4sk990D37rYrEkk/hVcRS957D264AQ4cgIEDbVcjIr5syBD4+28oXtysO63hAuLNFF5FLMmdG6ZPh8BA+OwzmD3bdkUi4osWLXKvdDJlihnvKuLNFF5FLGrQAIYONe1HHjG9sCIiGeXIEfcGBE8+CbffbrcekYyg8Cpi2QsvQL16Ztxrv35mGS0RkevldJqx9UeOQNWqZntqEV+g8CpiWfbsMGMGhITAypUwZoztikTEF3zyCSxYADlymHNMzpy2KxLJGAqvIh6gQgUzgQvguedg2za79YiId9u1CwYNMu3XX4caNayWI5KhFF5FPMSDD0LbthAba5ayOXvWdkUi4o3i4sw55MwZaNIEBg+2XZFIxlJ4FfEQDgd8+ilERMAff5jJFSIiafX887B5s9kQxbWiiYgvUXgV8SAFC5qxaQ4HfPQRfPGF7YpExJt89x2MHGnan35q1nUV8TUKryIe5vbb4X//M+3+/WHfPrv1iIh3iIqCvn1Ne+BA6NDBbj0imUXhVcQDvfKKWQM2Ohp69ID4eNsViYgnS0yE3r3h6FGoXh3eecd2RSKZR+FVxANlzw4zZ0JYGKxbZ8KsiMiVvPsuLF8OwcFmtz4tiyW+TOFVxEOVKWPGvQK88QZ8/73dekTEM/30k3unvvffh0qV7NYjktkUXkU8WLducP/9Zqecnj3NTjkiIi4nTkD37mZo0d13m/OFiK9TeBXxcGPGQOXKcPiwGf+akGC7IhHxBE4n3Hsv7NkDpUvDxIlmpRIRX6fwKuLhcuUyS2aFhMCKFfDqq7YrEhFP8N578PXXZvvXuXMhTx7bFYlkDYVXES9QubLpVQF47TVYutRuPSJi148/wrPPmvbo0VCnjtVyRLKUwquIl+jVy2wh6xr/evCg7YpExIajR814+IQEsw3sww/brkgka3l0eB02bBgOhyPFERERYbssEWvGjIFateC//8w/rwsXbFckIlkpIcG8kD10CCpWNCuSaJyr+BuPDq8AVapU4fDhw0nH9u3bbZckYk3OnGb8a3i4Wf/1uedsVyQiWemNN8ywoeBgM841NNR2RSJZz+PDa7Zs2YiIiEg6ChYsaLskEavKlYPJk0175EiYN89uPSKSNZYvh2HDTHv8eKha1Wo5ItZ4fHj9+++/KVq0KGXKlOGee+5h9+7dV71/bGwsMTExKQ4RX9OpEzz5pGn37Qt//mm3HhHJXHv3mvGtTqdZy7VvX9sVidjj0eG1fv36TJs2jSVLljBp0iSioqK4+eabOXbs2BUfM2LECMLDw5OOEiVKZGHFIlnnrbfgttvg1Cno2BH0Ok3EN507B507w7FjULcufPCB7YpE7HI4nU6n7SJS68yZM5QrV45nnnmGwYMHX/Y+sbGxxMbGJn0cExNDiRIliI6OJiwsLKtKFckS//5rlsg5dMgE2C+/hACPfkkqImnhdEKfPjBjBhQoAJs3Q8mStqsSyXgxMTGEh4enKq951b+5XLlyUa1aNf7+++8r3icoKIiwsLAUh4ivKlwYvvrKLFI+fz4MH267IhHJSGPHmuAaGAiff67gKgJeFl5jY2P5448/KFKkiO1SRDzGTTfBuHGm/dJL8O23dusRkYyxejW43mR8911o2tRuPSKewqPD65AhQ1i9ejV79uzhp59+4q677iImJoa+GqkuksL995uFyp1O6NEDdu2yXZGIXI8DB6BrV7Oua8+e8MQTtisS8RweHV4PHjxI9+7dqVixIp07dyZHjhxs2LCBUqVK2S5NxOOMGQM33wzR0WY1gtOnbVckIulx/jx06WJ20qpZUxsRiFzMqyZspUdaBgCLeLvISDOBKyoKOnQw42E1gUvEezid0Ls3fPYZ5MsHmzZBmTK2qxLJfD47YUtErq5oUbNpQVAQfP01DB1quyIRSYsRI0xwzZbN7Kan4CpyKYVXER/ToAF88olpv/kmTJ9utx4RSZ2vvnK/4Bw7Fpo1s1uPiKdSeBXxQT17wvPPm/YDD8C6dXbrEZGr27LFDBcAeOwxMwFTRC5P4VXER732mpm4FRdnLvfts12RiFxOVBS0bw9nz0LLlvDee7YrEvFsCq8iPiogAKZNgxo14MgR889RKxCIeJbz583ueAcPQsWKMGeOGe8qIlem8Criw3LnhgULzE5c27aZNWATEmxXJSJgVha47z746SfImxe++Qby5LFdlYjnU3gV8XElS5qtY4OCzD/HQYPMP00RseuFF2DWLNPTOnculC9vuyIR76DwKuIHGjRwrzrwwQcwapTdekT83UcfwfDh7rZWFhBJPYVXET/RtavZHx3gqafMGpIikvW+/RYefdS0X34Z7r3Xbj0i3kbhVcSPDB4MAweadu/e8OOPdusR8Te//AJ3323Gnvfta8KriKSNwquIH3E4YPRos/JAbKy5/Osv21WJ+Id9++DOO+HMGWje3AwXcDhsVyXifRReRfxMYKCZJHLTTXD8OLRubZbSEpHMc+IEtGlj1nStVs1M0MqRw3ZVIt5J4VXED4WEmJUHypaF3bvNP9WYGNtVifims2fNuxy//w7Fipkxr+HhtqsS8V4KryJ+qlAh+O47KFgQNm82C6WfP2+7KhHfcuGCGeO6dq0JrN9+C8WL265KxLspvIr4sQoVTIANDYXvv4fu3SE+3nZVIr4hMdGsJLBoEQQHw8KFUL267apEvJ/Cq4ifq1PH7MIVFGQ2M3jwQW1iIHK9nE6zIchnn7k3IWjUyHZVIr5B4VVEaNIEZs+GgACYPBmefdZ2RSLe7fXXYexY054yxYwrF5GMofAqIoAZ8/rxx6b9zjvw9ttWyxHxWuPGwUsvmfaYMdCzp916RHyNwquIJLn3XvcuXM8+a/4Ji0jqTZvm3gjkpZfg8cft1iPiixReRSSFp56C55837QED3L2xInJ1s2ebF4BOp/nbGTbMdkUivknhVUQu8frr8OSTpv3gg6Y3SUSu7MsvoVcvs8LAAw/A++9r9yyRzKLwKiKXcDhg5EjTe+R0mt6kOXNsVyXimb75Bu65BxISoG9fmDjRTH4UkcyhPy8RuSyHw/QePfCA6U3q2RO++sp2VSKeZfFiuOsusz5y9+7wyScKriKZTX9iInJFAQGmF6lPH9OrdM89ppdJRGDlSujUCeLioEsXM7wmMNB2VSK+T+FVRK4qIAA+/dT0Kl24YP5Jz59vuyoRu5YsgTvvNFsqt2sHM2eazQhEJPMpvIrINQUGml6lu+82AfauuzQGVvzXwoXQvr0Jrm3bwhdfQI4ctqsS8R8KryKSKtmyma0ue/c2Qwh69IDp021XJZK1vvzSPVSgc2fzcVCQ7apE/IvCq4ikWrZsZvtY1ySuvn21Dqz4j1mzoFs39+SsOXPU4ypig8KriKRJYKCZxOVaRqt/f/jwQ9tViWSuKVPMihuu5bCmT9cYVxFbFF5FJM0CAmDsWBg82Hw8cCC89ZYJsyK+5sMP3Ttn9e9vJjBqVQERexReRSRdHA54910YOtR8/L//wZAhZjiBiC9wOuHll82LM4DHHtMGBCKeQH+CIpJuDofZSvbdd83H770H/fqZFQlEvFlCAjz6KLz6qvl42DAYM0Zbvop4AoVXEbluTz0FU6eat1KnT4eOHeHMGdtViaRPbKzZkGPCBBNWx40zPbAKriKeQeFVRDJEnz7w9dcQHAzffgstWsDx47arEkmbmBho0wbmzjUrCcyZA488YrsqEUlO4VVEMsydd8Ly5ZA3L6xfD7feCvv22a5KJHUiI6FpU7Pta+7c5kVY1662qxKRiym8ikiGuvlmWLMGihWD33+H+vXh559tVyVydb/+an5Xf/kFChaEVavg9tttVyUil6PwKiIZrkoV0/NavTr8+y80bmx2IhLxRN9+C40awcGDULGi+d2tU8d2VSJyJQqvIpIpSpSAtWvN+MHz5+Guu+Dtt7UWrHiWDz+Edu3g9GkzZGD9eihXznZVInI1Cq8ikmlCQ80krsceMx8/+6xZ5F1LaYltCQnwxBNmDdfERLjvPli82IzXFhHPpvAqIpkqWzZ4/31zBATAJ5/AHXfA0aO2KxN/dfIktG9vficBRoyAjz82qwuIiOdTeBWRLPHYY7BggZnF/f33ULeumRwjkpV27IB69cw415w54fPPze5wWsNVxHsovIpIlrnzTvjpJyhfHvbvh1tuMZsaiGSFuXPNigK7dkGpUvDjj1oKS8QbKbyKSJaqXNksndW2rZnI1aePGXuocbCSWRIS4LnnTFA9cwaaNYNNm6B2bduViUh6KLyKSJbLk8dM5HrpJfPx++9D8+YQFWW1LPFBx46ZHv833zQfP/UULFkCBQrYrUtE0k/hVUSsCAiAV16B+fPNqgQ//AA1a5odukQywtq15ndqyRKzbfHMmfDuu2YSoYh4L4VXEbGqQwczjKBqVbOhQcuW8MILEB9vuzLxVgkJ8MYb0KSJ2XigfHmzfmv37rYrE5GMoPAqItbdeKMJsA8+aDYxeOMNs2D8gQO2KxNvExUFrVqZF0AJCdCrF2zeDDVq2K5MRDKKwquIeITgYJg4EWbPNsMIXG/5LlhguzLxFsuWmZC6fDmEhMDkyTBtmvl9EhHfofAqIh6lWzfYssXsLX/8uBlW0L8/nDpluzLxVGfPwuOPmyEnR46YISibNkG/flq/VcQXKbyKiMcpVw7WrTMzwx0Os/tR9eqwerXtysTTbNgAtWrB2LHm40ceMUNQKlWyW5eIZB6FVxHxSDlymJnh338PpUvD3r1mHOzgwXDunO3qxLa4OBg61Gx08ddfUKwYLF4M48aZISgi4rsUXkXEozVuDNu2maEDTieMGmUWl//pJ9uViS1bt5otXocPh8REMylr+3a44w7blYlIVlB4FRGPFxoKH30EixZBkSLw55/QsCE89hhER9uuTrLKmTPw9NNQt655QVOgAHz5pdliOG9e29WJSFZReBURr9GmDfz2G/TubXphP/jAbDf75ZfmY/FdixaZn/W775olsO66y/wudO5suzIRyWoKryLiVfLlM8sfrVhhFp+PjDRBpn172LfPdnWS0SIjoWtXaNsW9u+HUqVg4UL44gsoXNh2dSJig8KriHilZs3MW8cvvQTZs5tAU7kyvP66JnT5gthYeOcds4HF3LkQGGiGDOzYAXfeabs6EbHJ4XT69pttMTExhIeHEx0dTVhYWNZ8UqcTTp+GkyfhxAlz6WqfOgXnz5szs+vS1b5wwWz4frkjMNCsup0r16VH7tyQP78ZAFagAAQFZc3XKeIh/vgDHn4YfvjBfFyiBLz1Ftxzj9b59DZOJ8ybZ4Lq7t3muptuMmOe07RLlus8fOwYxMRc/jh92px3L3ckJEC2bOaVUfLLbNnMUhihoe4jLMx9GRYGBQuaj/XLJ5JqaclrCq8ZrXZt0x2UkJD5n+tKcud2B9kCBcwaMiVKQPHi5tLV1rYz4kOcTpgzB555xr2tbIMGZnWCBg3s1iap88svZik013q+RYqYFQX69DGv4ZOcOWPGiOzbZ9ZQO3QI/v3XHEeOuNs2u+Bz5oRChdxH4cLmskQJM/bBdWRVp4qIh1N4TSbLw2utWmYdFzCv1PPmhTx53JehoWYRwqAg95Ezp7nMnt38B05MdF+6jvh4s43MmTOXHqdOmd6F//5LW2gODzerwZcvf+mRP796DcQrnTsHI0fCm2+aPw8wPbCvvAIVKtitTS5vzx549VWYOtWc+nLmhBcfPcag1jsJ2f8n7NwJ//zjDqv//Zf6J8+Z05zrXL2iyY9cuUwvavbsKXtYs2c373bFx6c8Llwwl7Gxptc2Jsacf0+dcrdPnjTn6tTKk8cdZMuXh4oV3UehQjoPi99QeE0my8Pr3r3mZJgnjwmpWXnicTrNukH//ec+jhyBgwfNceCA+/Ja6wvlyWMGEFatCtWquS/z58+SL0XkekVGwgsvwJQp5k8jIMD04L34IpQta7s6ATMBa8wLR/nts1+pkriNyvzOrQX+5IbEnQQev0ZADQszu1eUKmV6MwsXvvyRK1eWfC0pnDkDR4+6e4JdvcFRUeaL3r/fBPHjx6/+POHh5hXXjTeac3D16uYoUkShVnyOwmsyVsa8eoNTp8wJdNcu+PvvlMfBg1d+XJEi5iRaq5ZZbLFuXfMPRCdS8VBbtphJXQsXmo+zZTN73r/wgsk9kkUSE81WWFu2cGrtr+xf+Ct59/9KUQ5f+TElSrh7IcuXd4fV0qXNC2xv5zoP799vup//+sv0Mu/caTpCrvTvuUABE2Jr1DCXdeqYzobAwCwtXyQjKbwmo/CaDufOmVD722/m2L7dXO7Zc/n758vnDrKuo3hxBVrxKD//bELskiXm4+zZoW9fM8ayUiW7tfmkw4fNN/2nn8zlxo3mrfXLOFfsBoLrVzcvjG+80RwVKtjpNfUU58+b8/DOnWZXju3bzXyKnTvNC4GL5cplQmy9emaG2003maCv87B4CYXXZBReM9CpU/D77+YEunkzbNpk2hcuXHrfwoXNpuOuo1YtM5xCxLIff4SXXzbrxLq0bQtDhsBtt+l/fbrExppw+uOPJqj+/PNl38E5SzBbqcmv1OBMuRo0HVSDOv2qmUmmkjrnzrnPw7/+auZY/PKLOT9frEABE2Lr14dGjcylP78gEI+m8JqMwmsmi401PQKbNrmP3367dOJYcLA5ibrC7M03+8bbfuK1fvzR7Nb09dfud2fr1oWnnoIuXUzPrFzBqVOwfj2sWWPWJ/vpJ3MuSMYZEEB08Sr8GHcTX0fdxE/UZwdVaNEqG08/DU2b6oVChklMND2yrhcOP/9sgu3FHQvZspkVcW691YTZRo1MwBXxAAqvySi8WnD2rOkJWLvWJIR16y6dmOBwmPFaTZua1eZvvdVMThDJYn/9ZZbTmjLFvFML5o2D++6D/v2hTBmr5XmG//4zf8+usLply6UvUAsWhFtvJbpyA+YdvIk3FtdhV5TpUc2WDbp3N73b1atbqN8fxcaaAPvzz+YcvGbN5eczVKpkQmyTJuZcHBGR5aWKgMJrCgqvHsDVK/Djj+ZYu9aM5UouIMCM12rWzATaRo309pZkqaNHYdw4mDDBTAoH8xqrRQsTZNu1M/uE+IW4ONOzumSJOX755dL7lC5tXnTeeiux9W9jwZ8VmDLVwZIl7lxbuLB5AfDQQ2YYvFi2b5/7RcjatWa7sotVrgy3327OxU2a6B0yyTIKr8kovHqoqChYtQq+/94cf/+d8vbs2c0wg6ZNTXpo2FDv40qWuHABvvnGhNhly9zXh4aa4QQ9e5pfS5+b2L17tzusrlhh1jFNrnJlE1Zvuw1uvZWEoiVYu9ZsDDF7ttlA0KVRIxgwADp31lB3j3bsmOlQ+OEHcx7esiXlCgcBAWaYQbNmJtDecos6FSTTKLwmo/DqJQ4eNCfPlSvN5b59KW8PDTUn0JYt4Y47zOYKIpnsn3/g00/hs89S/koWKgTt20OnTuZ/ulfuyHz6tPlbcwXWi98NKVjQ/ffWsiUULkx8vOm0++IL+Oors3SpS/HiZh3dvn21GYTXOnbMbG+2YoU5F//5Z8rbs2c3r0zuuANatTJjQDRwWTKIwmsyCq9eas8ec/JcscJ0f128o065cu5/rE2baotFyVSJiWbY4IwZ8PnnKXsZQ0PN//E77jBvEpQsaa/Oq3I6zRhIV1hduzblhJ5s2cxEyjvuMEetWhAQQFQULF4M335r/hRPnnQ/JE8e6NjRh3uj/d2hQ+YFzooV5nDtu+wSEWHOw61amV9+Tf6S66DwmozCqw9ITDRvZy1dav7p/vij2aLRJVs2M6zA1UNUp85FG6GLZJy4ONM5NW8ezJ9vljNNrmJF83+8USPzLqvVsZ5Hj5rEuWSJ+ftxDeZ1KVPGnbz//0Xgv/+a3tXVq827ydu2pXxI/vzQoQN07WreDNGwAD/hdJre+SVLzKuZ779PuQ2uw2GW63C9+GnQwJybRVLJ58LruHHjeOeddzh8+DBVqlRh9OjR3Hrrral6rMKrDzp1yoyXvdLbnfnzu3sDWrbU7FnJNImJZjL34sUmG/7006Xrx5csaUJsnTpQs6ZZZCPTOqguXIANG9wB45dfUo5hzJXLhNT/DxgxhW5gy1YHmza5l26+ePg5mEzSujW0aWPWwFcPqxAbazoSFi82v28Xv8oJDzdjalwvjjz2LQnxFD4VXufMmUPv3r0ZN24ct9xyCxMnTuTjjz/m999/p2Qq/hgUXv3A7t3uXtkVKy5drLtWLXMCbdVKE78kU5086R62/eOP5l36y22GVLy4WaGofHlz3HCD6QQtWtS8FZ+mYYR79rhfyK1ceckuVglVa3C83h3sLn8HW0Ju4fd/gvjjDzOc8Uo7QVevbuZlNW5sLgsVSkM94p8iI93n4aVLL10esVIl93n4ttsgZ047dYrH8qnwWr9+fWrXrs348eOTrqtUqRIdO3ZkxIgR13y8wqufuXDBdH8tXmyOzZtT3h4aCs2buyccaHN7yUSnTplfx/Xr3Zsh/fPP1R+TM6cJsYULm84r1xEWZl535Uw4ww0HV3HD7iWU/XsJBY79leLx0dkLsCG0BcuztWL+mRbsOlPkqp+vZEnTK1ynjulhrVfP7Pgskm4JCebc6+qV3bAh5au44GCzDFfr1uY8fMMNmvglvhNe4+LiCAkJ4YsvvqBTp05J1z/xxBNs3bqV1atXX/KY2NhYYpPt9BITE0OJEiUUXv3VkSOmF8B1Er144teNN6bsDQgOtlOn+I2YGLMp3c6d5i36XbvM5f79KSeCuTmpxnbuYAl3sIRbWUMQcUm3xhPIOm7+/1vv4Bdq4yTlmO/8+aFECRNUK1Y0v/aVKpm2gqpkuhMnzLti331nzsWRkSlvL1vWfR5u2lTbBfspnwmvkZGRFCtWjB9//JGbb7456frhw4czdepUdu7cecljhg0bxiuvvHLJ9QqvQmKiGQPo6pXdsCHlLkE5c5reANdJtEIF9QZIljp3zkwAO/rnMRzLl5Hv58VEbF9K7piUs8L+Cy3NjmJ38GepO9hbthmEhxMUZN5YyJ/fBNJ8+cxqV8WLa2lO8SBOp9lC3HUeXrMm5aoXOXKY9YRd5+EqVXQe9hM+F17XrVtHw4YNk65/4403mD59On9evAYd6nmVNDh50vQGuE6iFw8ALF3afQJt1swkA5HMEB/vnmi1ZImZOZX81BwSYl5YuYa7lC+vf+jiG06fNmO1Fy82PbN796a8vVgx93m4eXPt+OXDfCa8pmfYwMU05lVSxemE3393B9kffjBrIrlky2amjLtOojVqKDxI+jmdZvDrsmVmWMtlJlpRrZp7pnajRl66E4JIGjidZgyN6zz8/fdw/rz79sBAM+nWdR7+/7WIxTf4THgFM2GrTp06jBs3Lum6ypUr06FDB03Yksxz5ox7Oa7Fiy9dPygiwt0L1qKFea9W5GpOnDAh1RVY9+xJeXv+/OZ3ybVecdGiduoU8RTnzpmOBFeYvfjd1oIF3efhli3Nx+K1fCq8upbKmjBhAg0bNuSjjz5i0qRJ7Nixg1KpmCmu8CoZ4p9/3EF25UoTbl0cDrjpJvdJtG5dLccl7jVXXWF148aUM66zZze9+S1amH+8tWppAVWRq9m7130eXr7cDDlwcTigdm2ztmyzZubdCg329io+FV7BbFLw9ttvc/jwYapWrcqoUaO47bbbUvVYhVfJcMkX51682EwdTy53bnPibNrUHLVqaacZfxAfbyYErlpljjVrUv5zBTPFv2VLE1gbN9asapH0iosza9C5VjD49deUt2fPbnb5atbMBNr69bUdnIfzufB6PRReJdMdOuRejmv58ksX5w4LM8twNWliwmyNGuph8wXx8Wbb4uRh9eINMlxDAVyB1epesSI+LDLSvCu2cqWZiLt/f8rbQ0JMp0KzZuZcXLu23iHzMAqvySi8SpZKTDQ9sd9/b47VqyE6OuV98uQxYfaWW9z7hmq3Gc93/rxZeH3dOvNzXbPm0klWefKYHtUmTcxRvbomlIhkNafT7LzoCrMrV5o1v5MLCTG9sbfeakJtgwZaUcYyhddkFF7FqoQEs62SK8xerncuRw4TYG++2Ry33GK2VxK7IiNNUF23zrw9uXlzyvUowWx9dXFYVa+6iGdxrSbj6pVds+bSd8gCAqBmTRNkGzUywbZECa0qk4UUXpNReBWPEh9vQtCaNSYU/fjjpT0CYHacuekmM/mrTh0zbjY8POvr9RfR0eZFxi+/mIlV69bBvn2X3q9QIfMCwzWmWUNARLxPYqJZuWDtWnMuXrv20vVlwXQi1KtnjptuMpdaWSbTKLwmo/AqHs319pYryK5bZ3afudyfZfny7k3o69QxY7YUaNPu+HETUl3H5s1mj9aLBQSYntSGDd294mXKqCdGxBcdPGhC7Nq15ly8fXvKHRhdypQxQbZOHXN+qF7dLJ2o88J1U3hNRuFVvM7Jk/DTT2aXpc2bzXHx5AOX4sWhalWzhaLrsnJlLREDZnjG77+7jx07zHGl72XJku4XBQ0bmn9QGgMn4p/OnTPvxmzcCD//bC7/+uvy982f3x1kq1c35+GKFbUbWBopvCaj8Co+4ehRdy/h5s0m2F4phDkcUKoU3HBDyqNcOTMcISQka2vPTKdPm57r3bvNWryu448/4MCBKz+uXDkTUmvXdg/LKFAg6+oWEe9z8qQ5//78s1maa9s22Lkz5frNyRUsaEJshQrmqFjRnHtKlTKr0EgKCq/JKLyKzzpxwvQo/vabu1fxt98uP4Y2uSJFzESEYsVMz63rsnhxs6tT/vymx8DmLHmn04xDjYoyS5FFRprD1T50yOxQ9e+/V3+eIkVMT3Tlyu5e6apVIW/erPk6RMS3nTtnXixv2+Y+/vjDnKeuJk8e825PyZImzJYsac7BhQq5jwIF7K8RHheXZevjKrwmo/AqfufoUTMZ4Z9/zFjO5MfFy3ZdSUCACXj58pkwmz+/+ThXLtNzm/wIDjaHK+y6xn45HOZwOs3GDufPmxP9uXMp2ydPmnGoJ06Yy+PHzXWXG292OXnzmt4M11G2LNx4o9kQIF++tH73RESu36lTZlvxv/4yvbOuyz17Ll3p4Gry5TNBNn9+M4wp+ZE7t7nMlcuE3GzZzATS5O2AALNKSlycuUzePn/eLPcXHe2+dLVPnoRjx0xHx86dmfZtSk7hNRmFV5H/53Sak+bu3abn8tAhM0kh+WVk5KW7QtkUFmZ6hosWNUfydunSJqiqF1VEvMmpU2ZY0/79ZlWT/fvNceiQ6Xw4cgT+++/KwxGyUv78ppYskJa8pj0rRfyFw+HuRa1X78r3i401vaDHjrkPV4/o2bOmt/Ts2ZTtc+dMOHa9Fk7eBggKMhsxBAdfepknj7uXN18+dztvXnO7iIgvCQ11D2e6koQEc851hdljx0zoPXXKdDC42qdOmXNwQoJZijE+PmU7MdG87Z89uzmSt4OCTAdBeLj7Mnm7QAGPXRpM4VVEUgoKMku/RETYrkRExD8FBpoJXwULXj3k+intWygiIiIiXkPhVURERES8hsKriIiIiHgNhVcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeBURERERr6HwKiIiIiJeQ+FVRERERLyGwquIiIiIeA2FVxERERHxGgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvEY22wVkNqfTCUBMTIzlSkRERETkclw5zZXbrsbnw+upU6cAKFGihOVKRERERORqTp06RXh4+FXv43CmJuJ6scTERCIjIwkNDcXhcNguxyfExMRQokQJDhw4QFhYmO1yJI308/N++hl6P/0MvZt+fhnP6XRy6tQpihYtSkDA1Ue1+nzPa0BAAMWLF7ddhk8KCwvTH60X08/P++ln6P30M/Ru+vllrGv1uLpowpaIiIiIeA2FVxERERHxGgqvkmZBQUG8/PLLBAUF2S5F0kE/P++nn6H308/Qu+nnZ5fPT9gSEREREd+hnlcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeJUMERsbS82aNXE4HGzdutV2OZJKe/fu5f7776dMmTIEBwdTrlw5Xn75ZeLi4myXJlcwbtw4ypQpQ86cOalTpw5r1qyxXZKk0ogRI6hXrx6hoaEUKlSIjh07snPnTttlyXUYMWIEDoeDQYMG2S7Fryi8SoZ45plnKFq0qO0yJI3+/PNPEhMTmThxIjt27GDUqFFMmDCB559/3nZpchlz5sxh0KBBDB06lC1btnDrrbfSunVr9u/fb7s0SYXVq1czYMAANmzYwLJly4iPj6dly5acOXPGdmmSDhs3buSjjz6ievXqtkvxO1oqS67bd999x+DBg/nyyy+pUqUKW7ZsoWbNmrbLknR65513GD9+PLt377Zdilykfv361K5dm/HjxyddV6lSJTp27MiIESMsVibpcfToUQoVKsTq1au57bbbbJcjaXD69Glq167NuHHjeP3116lZsyajR4+2XZbfUM+rXJd///2X/v37M336dEJCQmyXIxkgOjqafPny2S5DLhIXF8fmzZtp2bJliutbtmzJunXrLFUl1yM6OhpAf29eaMCAAdx55500b97cdil+KZvtAsR7OZ1O+vXrx8MPP0zdunXZu3ev7ZLkOv3zzz+MHTuWkSNH2i5FLvLff/+RkJBA4cKFU1xfuHBhoqKiLFUl6eV0Ohk8eDCNGjWiatWqtsuRNJg9eza//PILGzdutF2K31LPq1xi2LBhOByOqx6bNm1i7NixxMTE8Nxzz9kuWS6S2p9hcpGRkbRq1YquXbvywAMPWKpcrsXhcKT42Ol0XnKdeL6BAweybds2Zs2aZbsUSYMDBw7wxBNPMGPGDHLmzGm7HL+lMa9yif/++4///vvvqvcpXbo099xzD998802Kf5wJCQkEBgbSs2dPpk6dmtmlyhWk9mfoOvlGRkbStGlT6tevz5QpUwgI0OtaTxMXF0dISAhffPEFnTp1Srr+iSeeYOvWraxevdpidZIWjz32GPPnz+eHH36gTJkytsuRNJg/fz6dOnUiMDAw6bqEhAQcDgcBAQHExsamuE0yh8KrpNv+/fuJiYlJ+jgyMpI77riDuXPnUr9+fYoXL26xOkmtQ4cO0bRpU+rUqcOMGTN04vVg9evXp06dOowbNy7pusqVK9OhQwdN2PICTqeTxx57jHnz5rFq1SrKly9vuyRJo1OnTrFv374U1917773ceOONPPvssxoCkkU05lXSrWTJkik+zp07NwDlypVTcPUSkZGRNGnShJIlS/Luu+9y9OjRpNsiIiIsViaXM3jwYHr37k3dunVp2LAhH330Efv37+fhhx+2XZqkwoABA5g5cyZff/01oaGhSWOVw8PDCQ4OtlydpEZoaOglATVXrlzkz59fwTULKbyK+LGlS5eya9cudu3adckLDr0p43m6devGsWPHePXVVzl8+DBVq1bl22+/pVSpUrZLk1RwLXHWpEmTFNdPnjyZfv36ZX1BIl5KwwZERERExGtoVoaIiIiIeA2FVxERERHxGgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvIbCq4iID2vSpAmDBg2yXYaISIbRDlsiIj7s+PHjZM+endDQUNuliIhkCIVXEREREfEaGjYgIpIFjh49SkREBMOHD0+67qeffiJHjhwsXbr0so/ZuHEjLVq0oECBAoSHh9O4cWN++eWXpNtXrVpFjhw5WLNmTdJ1I0eOpECBAhw+fBi4dNjAuHHjKF++PDlz5qRw4cLcddddGfyViohkLoVXEZEsULBgQT799FOGDRvGpk2bOH36NL169eLRRx+lZcuWl33MqVOn6Nu3L2vWrGHDhg2UL1+eNm3acOrUKcAdTHv37k10dDS//vorQ4cOZdKkSRQpUuSS59u0aROPP/44r776Kjt37mTx4sXcdtttmfp1i4hkNA0bEBHJQgMGDGD58uXUq1ePX3/9lY0bN5IzZ85UPTYhIYG8efMyc+ZM2rZtC0BcXBwNGjSgfPny7Nixg4YNGzJp0qSkxzRp0oSaNWsyevRovvrqK+69914OHjyoMbAi4rXU8yoikoXeffdd4uPj+fzzz/nss8/ImTMn+/fvJ3fu3EmHa2jBkSNHePjhh6lQoQLh4eGEh4dz+vRp9u/fn/R8OXLkYMaMGXz55ZecO3eO0aNHX/Fzt2jRglKlSlG2bFl69+7NZ599xtmzZzP7SxYRyVDZbBcgIuJPdu/eTWRkJImJiezbt4/q1atTtGhRtm7dmnSffPnyAdCvXz+OHj3K6NGjKVWqFEFBQTRs2JC4uLgUz7lu3TrArCxw/PhxcuXKddnPHRoayi+//MKqVatYunQpL730EsOGDWPjxo3kyZMnU75eEZGMpmEDIiJZJC4ujptuuomaNWty44038t5777F9+3YKFy582fuHhoYybtw4evfuDcCBAwcoWbIko0aNSpqE9c8//1CzZk3ef/99Pv/8c86fP8+KFSsICDBvrCUfNnCxM2fOkCdPHubMmUPnzp0z5WsWEclo6nkVEckiQ4cOJTo6mvfff5/cuXPz3Xffcf/997Nw4cLL3v+GG25g+vTp1K1bl5iYGJ5++mmCg4OTbk9ISKB37960bNmSe++9l9atW1OtWjVGjhzJ008/fcnzLVy4kN27d3PbbbeRN29evv32WxITE6lYsWKmfc0iIhlNY15FRLLAqlWrGD16NNOnTycsLIyAgACmT5/O2rVrGT9+/GUf8+mnn3LixAlq1apF7969efzxxylUqFDS7W+88QZ79+7lo48+AiAiIoKPP/6YF154IcUwBJc8efLw1Vdf0axZMypVqsSECROYNWsWVapUyZSvWUQkM2jYgIiIiIh4DfW8ioiIiIjXUHgVEREREa+h8CoiIiIiXkPhVURERES8hsKriIiIiHgNhVcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeBURERERr6HwKiIiIiJe4/8AREhVHVRActsAAAAASUVORK5CYII=",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"\n",
"# Generate x values from -5 to 5\n",
"x = np.linspace(-5, 5, 400)\n",
"\n",
"# Define two functions\n",
"y1 = x**2\n",
"y2 = np.sin(x)\n",
"\n",
"# Create a new figure and axis\n",
"plt.figure(figsize=(8, 6))\n",
"plt.title('Plotting Two Functions')\n",
"plt.xlabel('x-axis')\n",
"plt.ylabel('y-axis')\n",
"\n",
"# Plot the first function in blue\n",
"plt.plot(x, y1, label='y = x^2', color='blue')\n",
"\n",
"# Plot the second function in red\n",
"plt.plot(x, y2, label='y = sin(x)', color='red')\n",
"\n",
"# Add a legend\n",
"plt.legend()\n",
"\n",
"# Show the plot\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "CdeS5eOoAuvF"
},
"source": [
"## Task 2.6: Average Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6eOmPKKwAxaL"
},
"source": [
"In this task, we need to implement `average_increase_in_cases`. This function takes `n_cases_increase` and `n_adj_entries_avg` as arguments, and **averages the increase in cases for each day using data from the previous and next `n_adj_entries_avg` number of days**.\n",
"\n",
"Similar to task 2.3, `n_cases_increase` is the output obtained from calling `compute_increase_in_cases(n_cases_cumulative)`.\n",
"\n",
"In this case, you can assume that **`n_adj_entries_avg` is a positive integer**.\n",
"\n",
"For example, if we find that the daily increase in cases for **one country** is given by `a = np.array([0, 5, 10, 15, 20, 25, 30])` and `n_adj_entries_avg = 2`, then\n",
"- the average increase on day 3 is $(0 + 5 + 10 + 15 + 20) / 5 = 10$\n",
"- the average increase on day 4 is $(5 + 10 + 15 + 20 + 25) / 5 = 15$\n",
"- the average increase on day 5 is $(10 + 15 + 20 + 25 + 30) / 5 = 20$\n",
"- it is not possible to compute the average for the other days since there will not be sufficient values to use for computing the mean\n",
"\n",
"Therefore, for **this** country, the average daily increase should be `np.array([np.nan, np.nan, 10, 15, 20, np.nan, np.nan])`.\n",
"\n",
"In other words, the average increase in cases for a particular country on the $(j + 1)$-th day is given by the mean of the daily increase in cases over the interval `[-n_adj_entries_avg + j, n_adj_entries_avg + j]` (Note: this interval includes the endpoints).\n",
"\n",
"The return value should be the mean increase in cases for each day -- using data from the previous and next `n_adj_entries_avg` number of days -- represented as a 2D `np.ndarray` such that the $(i, j)$ entry represents the average increase in daily cases on the $(j + 1)$-th day in the $i$th country, **rounded down to the smallest integer**.\n",
"\n",
"**Note:** In this task, you may use some of the Numpy functions that you have learned earlier, such as `numpy.mean` and `numpy.floor`.\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.In addition, you may benefit from using the following additional functions:\n",
"\n",
"* [`numpy.lib.stride_tricks.sliding_window_view`](https://numpy.org/devdocs/reference/generated/numpy.lib.stride_tricks.sliding_window_view.html): Create a sliding window view into the array with the given window shape.\n",
"* [`numpy.ndarray.fill`](https://numpy.org/doc/stable/reference/generated/numpy.ndarray.fill.html): Fill the array with a scalar value.\n",
"\n",
"The basic usage of these functions is given below."
]
},
{
"cell_type": "code",
"execution_count": 58,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[1 2 3]\n",
" [2 3 4]\n",
" [3 4 5]\n",
" [4 5 6]]\n",
"[0 0 3 4 5 6]\n"
]
}
],
"source": [
"a = np.array([1, 2, 3, 4, 5, 6])\n",
"print(np.lib.stride_tricks.sliding_window_view(a, 3)) # Create a sliding window of length 3\n",
"'''\n",
"[[1, 2, 3],\n",
" [2, 3, 4],\n",
" [3, 4, 5],\n",
" [4, 5, 6]]\n",
"'''\n",
"\n",
"a[:2].fill(0) # Fill the first two elements of the array a with 0\n",
"\n",
"print(a) # array([0, 0, 3, 4, 5, 6])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-33YHZWUAw7A"
},
"outputs": [],
"source": [
"def average_increase_in_cases(n_cases_increase, n_adj_entries_avg=7):\n",
" '''\n",
" Averages the increase in cases for each day using data from the previous\n",
" `n_adj_entries_avg` number of days and the next `n_adj_entries_avg` number\n",
" of days.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the daily increase in the number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" n_adj_entries_avg: int\n",
" Number of days from which data will be used to compute the average increase\n",
" in cases. This should be a positive integer.\n",
" \n",
" Returns\n",
" -------\n",
" Mean increase in cases for each day, using data from the previous\n",
" `n_adj_entries_avg` number of days and the next `n_adj_entries_avg` number\n",
" of days, as a 2D `ndarray` such that the (i, j) entry represents the\n",
" average increase in daily cases on the (j + 1)th day in the ith country,\n",
" rounded down to the smallest integer.\n",
" \n",
" The average increase in cases for a particular country on the (j + 1)th day\n",
" is given by the mean of the daily increase in cases over the interval\n",
" [-`n_adj_entries_avg` + j, `n_adj_entries_avg` + j]. (Note: this interval\n",
" includes the endpoints).\n",
" Note\n",
" ----\n",
" Since this computation requires data from the previous `n_adj_entries_avg`\n",
" number of days and the next `n_adj_entries_avg` number of days, it is not\n",
" possible to compute the average for the first and last `n_adj_entries_avg`\n",
" number of days. Therefore, set the average increase in cases for these days\n",
" to `np.nan` for all countries.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.6\n",
"n_cases_increase = np.array([[0, 5, 10, 15, 20, 25, 30]])\n",
"actual = average_increase_in_cases(n_cases_increase, n_adj_entries_avg=2)\n",
"expected = np.array([[np.nan, np.nan, 10, 15, 20, np.nan, np.nan]])\n",
"assert(np.array_equal(actual, expected, equal_nan=True))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Visualising the Data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To view the results of averaging, you can use the helper function `visualise_increase`. This function utilises the `Matplotlib` library to display data of different coutries in the same graph."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def visualise_increase(n_cases_increase, n_cases_increase_avg=None):\n",
" '''\n",
" Visualises the increase in cases for each country that is represented in\n",
" `n_cases_increase`. If `n_cases_increase_avg` is passed into the\n",
" function as well, visualisation will also be done for the average increase in\n",
" cases for each country.\n",
"\n",
" NOTE: If more than 5 countries are represented, only the plots for the first 5\n",
" countries will be shown.\n",
" '''\n",
" days = np.arange(1, n_cases_increase.shape[1] + 1) # Our x axis will be \"days\"\n",
" plt.figure() # Start a new graph\n",
" for i in range(min(5, n_cases_increase.shape[0])): # A curve for each row (country)\n",
" plt.plot(days, n_cases_increase[i, :], label='country {}'.format(i))\n",
" plt.legend()\n",
" plt.title('Increase in Cases')\n",
"\n",
" if n_cases_increase_avg is None:\n",
" plt.show()\n",
" return\n",
" \n",
" plt.figure() # Start a new graph \n",
" for i in range(min(5, n_cases_increase_avg.shape[0])): # A curve for each row (country)\n",
" plt.plot(days, n_cases_increase_avg[i, :], label='country {}'.format(i))\n",
" plt.legend()\n",
" plt.title('Average Increase in Cases')\n",
" plt.show() # Show all graphs"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To help you understand how this helper function works, the following is an example of using the helper function `visualise_increase` on a dummy data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"n_cases_increase = np.array([[0, 2, 5, 3, 11, 9, 12, 1, 15, 30], [20, 12, 1, 7, 12, 9, 9, 28, 4, 16]])\n",
"visualise_increase(n_cases_increase, average_increase_in_cases(n_cases_increase, n_adj_entries_avg=2))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FblvT7rbAxyh"
},
"source": [
"The results we obtained when using `n_cases_top_cumulative` to compute `n_cases_increase` and `n_cases_increase_avg`, with the default value of 7 for `n_adj_entries_avg`, are shown in two figures below respectively.\n",
"\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "pU2uVb4RIObo"
},
"source": [
"## Task 2.7: Finding Peaks in Daily Increase"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Wo2FuuQoISZu"
},
"source": [
"Our last task is to implement `is_peak`. This function takes `n_cases_increase_avg` and `n_adj_entries_peak` as arguments, and **determines whether the $(j + 1)$-th day was a day when the increase in cases peaked in the $i$th country**.\n",
"\n",
"In this case, `n_cases_increase_avg` is given by `average_increase_in_cases(n_cases_increase, n_adj_entries_avg)`.\n",
"\n",
"Suppose `a` is the average daily increase in cases, with the $(i, j)$ entry indicating the **average increase** in cases on the $(j + 1)$-th day in the $i$-th country. Moreover, let `n_adj_entries_peak` be denoted by `m`.\n",
"\n",
"In addition, an increase on the $(j + 1)$-th day is deemed *significant* in the $i$-th country if `a[i, j]` is greater than 10 percent of the mean of all **average daily increases** in the country. `np.nan` is, as the name suggests, not a number and cannot contribute to the mean. Therefore, if we have the set $\\{2, 3, `np.nan`\\}$, the mean should be $(2 + 3) / 2 = 2.5$.\n",
"\n",
"Now, to determine whether there is a *peak* on the $(j + 1)$-th day in the $i$-th country, check whether `a[i, j]` is *maximum* in`(a[i, j - m], a[i, j - m + 1], ..., a[i, j + m - 1], a[i, j + m])`. \n",
"\n",
"In the event that there are non-unique values such that there exists some value `a[i, k] = a[i, j]`, where $k \\neq j$ and $j - m \\leq k \\leq j + m$, we consider `a[i, j]` a maximum if and only if $k > j$. For example, in $(5, 10, 10)$, 10 is considered a maximum (since the second 10 appears to the right of the value 10 in the middle); but in $(10, 10, 5)$, 10 is not considered a maximum (since there exists another 10 to the left of the value in the middle).\n",
"\n",
"Then, **if `a[i, j]` is maximum and significant, then there is a peak on the $(j + 1)$-th day in the ith country; otherwise, there is no peak.**\n",
"\n",
"In this case, the return value of this function should be a 2D `np.ndarray` with the $(i, j)$ entry indicating whether there is a peak in the daily increase in cases on the $(j + 1)$-th day in the $i$th country.\n",
"\n",
"While imperfect, this approach gives a pretty decent result especially with the default value of 7 for `n_adj_entries_avg` and `n_adj_entries_peak`, as shown in figure below.\n",
"\n",
"\n",
"\n",
"**Note:** In this task, you may use some of the Numpy functions that you have learned earlier, including `np.lib.stride_tricks.sliding_window_view`. In addition, you may benefit from using the following additional functions:\n",
"- [`numpy.count_nonzero`](https://numpy.org/doc/stable/reference/generated/numpy.count_nonzero.html): This function (recursively) counts how many elements in an array (and in sub-arrays thereof) that have non-zero values.\n",
"- [`numpy.isnan`](https://numpy.org/doc/stable/reference/generated/numpy.isnan.html): Test element-wise for NaN and return result as a boolean array.\n",
"- [`numpy.nanmean`](https://numpy.org/doc/stable/reference/generated/numpy.nanmean.html): Compute the arithmetic mean along the specified axis, ignoring NaNs. Returns the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. \n",
"\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"The basic usage of these functions is given below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[0, 1, 7, 0], [3, 0, 2, 19]])\n",
"print(np.count_nonzero(a)) # 5\n",
"\n",
"a = np.array([1, 2, np.nan])\n",
"print(np.isnan(a)) # [False, False, True]\n",
"\n",
"a = np.array([[1, np.nan], [3, 5]])\n",
"print(np.nanmean(a)) # 3.0"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2noFaxZLIB1I"
},
"outputs": [],
"source": [
"def is_peak(n_cases_increase_avg, n_adj_entries_peak=7):\n",
" '''\n",
" Determines whether the (j + 1)th day was a day when the increase in cases\n",
" peaked in the ith country.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase_avg: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the average daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the average daily increase in the number of confirmed\n",
" cases on the (j + 1)th day in the ith country. In this case, the 'average'\n",
" is computed using the output from `average_increase_in_cases`.\n",
" n_adj_entries_peak: int\n",
" Number of days that determines the size of the window in which peaks are\n",
" to be detected. \n",
" \n",
" Returns\n",
" -------\n",
" 2D `ndarray` with the (i, j) entry indicating whether there is a peak in the\n",
" daily increase in cases on the (j + 1)th day in the ith country.\n",
" Suppose `a` is the average daily increase in cases, with the (i, j) entry\n",
" indicating the average increase in cases on the (j + 1)th day in the ith\n",
" country. Moreover, let `n_adj_entries_peak` be denoted by `m`.\n",
" In addition, an increase on the (j + 1)th day is deemed significant in the\n",
" ith country if `a[i, j]` is greater than 10 percent of the mean of all\n",
" average daily increases in the country.\n",
" Now, to determine whether there is a peak on the (j + 1)th day in the ith\n",
" country, check whether `a[i, j]` is maximum in {`a[i, j - m]`, `a[i, j - m + 1]`,\n",
" ..., `a[i, j + m - 1]`, `a[i, j + m]`}. If it is and `a[i, j]` is significant,\n",
" then there is a peak on the (j + 1)th day in the ith country; otherwise,\n",
" there is no peak.\n",
" Note\n",
" ----\n",
" Let d = `n_adj_entries_avg` + `n_adj_entries_peak`, where `n_adj_entries_avg`\n",
" is that used to compute `n_cases_increase_avg`. Observe that it is not\n",
" possible to detect a peak in the first and last d days, i.e. these days should\n",
" not be peaks.\n",
" \n",
" As described in `average_increase_in_cases`, to compute the average daily\n",
" increase, we need data from the previous and the next `n_adj_entries_avg`\n",
" number of days. Hence, we won't have an average for these days, precluding\n",
" the computation of peaks during the first and last `n_adj_entries_avg` days.\n",
" Moreover, similar to `average_increase_in_cases`, we need the data over the\n",
" interval [-`n_adj_entries_peak` + j, `n_adj_entries_peak` + j] to determine\n",
" whether the (j + 1)th day is a peak.\n",
" Hint: to determine `n_adj_entries_avg` from `n_cases_increase_avg`,\n",
" `np.count_nonzero` and `np.isnan` may be helpful.\n",
"\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
"\n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.7\n",
"\n",
"n_cases_increase_avg = np.array([[np.nan, np.nan, 10, 10, 5, 20, 7, np.nan, np.nan], [np.nan, np.nan, 15, 5, 16, 17, 17, np.nan, np.nan]])\n",
"n_adj_entries_peak = 1\n",
"\n",
"actual = is_peak(n_cases_increase_avg, n_adj_entries_peak=n_adj_entries_peak)\n",
"expected = np.array([[False, False, False, False, False, True, False, False, False],\n",
" [False, False, False, False, False, True, False, False, False]])\n",
"assert np.all(actual == expected)\n",
"\n",
"n_cases_increase_avg2 = np.array([[np.nan, np.nan, 10, 20, 20, 20, 20, np.nan, np.nan], [np.nan, np.nan, 20, 20, 20, 20, 10, np.nan, np.nan]])\n",
"n_adj_entries_peak2 = 1\n",
"\n",
"actual2 = is_peak(n_cases_increase_avg2, n_adj_entries_peak=n_adj_entries_peak2)\n",
"expected2 = np.array([[False, False, False, True, False, False, False, False, False],\n",
" [False, False, False, False, False, False, False, False, False]])\n",
"assert np.all(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Explanation of the example test case\n",
"\n",
"Below is the process on how the function should compute the above example test case.\n",
"\n",
"Consider:\n",
"- `n_cases_increase_avg = np.array([[np.nan, np.nan, 10, 10, 5, 20, 7, np.nan, np.nan], [np.nan, np.nan, 15, 5, 16, 17, 17, np.nan, np.nan]])`\n",
"- `n_adj_entries_peak = 1`\n",
"\n",
"Let's get the solution for this instance of `is_peak` function parameter values.\n",
"\n",
"1. Work with only the non-nan portion of the n_cases_increase_avg array -> [[10, 10, 5, 20, 7], [15, 5, 16, 17, 17]]\n",
"2. First, we check for max for each window of size 3 (1 left, middle, 1 right) -> 1 is the value of `n_adj_entries_peak`\n",
" * We have to look at the following windows for country 1:\n",
" 1. [10, 10, 5] for 10: False as there is an equal max element to its left in the window\n",
" 2. [10, 5, 20] for 5: False as it is not max\n",
" 3. [5, 20, 7] for 20: True as it is max\n",
" \n",
" So, for country 1, the max checking boolean result is: [False, False, True]\n",
"\n",
" * We have to look at the following windows for country 2: \n",
" 1. [15, 5, 16] for 5: False as it is not max\n",
" 2. [5, 16, 17] for 16: False as it is not max\n",
" 3. [16, 17, 17] for 17: True as it is max and the equal element is on its right side in the window. \n",
" \n",
" So, for country 2, the max checking boolean result is: [False, False, True]\n",
" \n",
" * So, final result for max checking is: [[False, False, True], [False, False, True]]\n",
"\n",
"\n",
"3. Now, we check for significance -> whether an element of interest is greater than 10% of the mean of avg daily increases in a country\n",
" - For country 1,\n",
" - The threshold value is: ((10 + 10 + 5 + 20 + 7) / 5) * 0.1 = 1.04\n",
" - 10, 5 and 20 -> all are greater than this value. \n",
" - So, the significance checking boolean result for country 1 is: [True, True, True]\n",
" - For country 2,\n",
" - The threshold value is: ((15 + 5 + 16 + 17 + 17) / 5) * 0.1 = 1.40\n",
" - 5, 16, 17 -> all are greater than this value. \n",
" - So, the significance checking boolean result for country 2 is: [True, True, True]\n",
" \n",
" - So, final result for significance checking is: [[True, True, True], [True, True, True]]\n",
"\n",
"4. The condition for being a peak is to satisfy both the max and the significance criteria.\n",
"So, we now have \"and\" the final resultant boolean arrays for max and significance checking that we derived a while ago\n",
"The result we get after the operation is: [[False, False, True], [False, False, True]]\n",
"\n",
"5. So, is it done? \n",
"Not yet. Our final result should have the same shape as the n_cases_increase_avg array, which in this\n",
"case is 2 X 9. But the result we have currently is of shape 2 X 3.\n",
"So, for each of the 2 rows, we have to pad with 6 False values; 3 on the left and 3 on the right which results in:\n",
"[[False, False, False, False, False, True, False, False, False], \n",
" [False, False, False, False, False, True, False, False, False]]\n",
" \n",
"6. At last! We got our final answer"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Visualising the peaks\n",
"\n",
"The peaks in daily increase can be highlighted on the graph using our helper function `visualise_peaks`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def visualise_peaks(n_cases_increase_avg, peaks):\n",
" '''\n",
" Visualises peaks for each of the country that is represented in\n",
" `n_cases_increase_avg` according to variable `peaks`.\n",
" \n",
" NOTE: If there are more than 5 countries, only the plots for the first 5\n",
" countries will be shown.\n",
" '''\n",
" days = np.arange(1, n_cases_increase_avg.shape[1] + 1) # Days will be our x-coordinates\n",
"\n",
" plt.figure() # Start a graph\n",
" \n",
" for i in range(min(5, n_cases_increase_avg.shape[0])): # A curve for each row (country) \n",
" plt.plot(days, n_cases_increase_avg[i, :], label='country {}'.format(i)) # Plot the daily increase curve\n",
" peak = (np.nonzero(peaks[i, :]))[0]\n",
" peak_days = peak + 1 # since data starts from day 1, not 0\n",
" plt.scatter(peak_days, n_cases_increase_avg[i, peak]) # Scatterplot of peak(s) that lay on top of the curve\n",
" \n",
" plt.legend()\n",
" plt.show() # Display graph"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To view the results of your solution, you can use `visualise_peaks` as follows."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Visualise the results on the test case\n",
"visualise_peaks(n_cases_increase_avg, is_peak(n_cases_increase_avg, n_adj_entries_peak=n_adj_entries_peak))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gv3IzLY8ISfY"
},
"source": [
"# Submission"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kIPn-5PNJ8k5"
},
"source": [
"Once you are done, please submit your work to Coursemology, by copying the right snippets of code into the corresponding box that says 'Your answer', and click 'Save'. After you save, you can make changes to your\n",
"submission.\n",
"\n",
"Once you are satisfied with what you have uploaded, click 'Finalize submission.' **Note that once your submission is finalized, it is considered to be submitted for grading and cannot be changed**. If you need to undo\n",
"this action, you will have to email your assigned tutor for help. Please do not finalize your submission until you are sure that you want to submit your solutions for grading. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Appendix"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Below is a non-exhaustive list of NumPy functions allowed and now allowed: "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Allowed functions:\n",
"\n",
"numpy.all\n",
"numpy.any\n",
"numpy.append\n",
"numpy.arange\n",
"numpy.argmax\n",
"numpy.compress\n",
"numpy.concatenate\n",
"numpy.cumsum\n",
"numpy.diff\n",
"numpy.divide\n",
"numpy.einsum\n",
"numpy.equal\n",
"numpy.full\n",
"numpy.greater\n",
"numpy.greater_equal\n",
"numpy.hstack\n",
"numpy.insert\n",
"numpy.lib.stride_tricks\n",
"numpy.logical_and\n",
"numpy.logical_not\n",
"numpy.ndarray.flatten\n",
"numpy.ndarray.reshape \n",
"numpy.newaxis\n",
"numpy.ones\n",
"numpy.pad\n",
"numpy.shape\n",
"numpy.squeeze\n",
"numpy.take\n",
"np.ufunc.reduce\n",
"numpy.where\n",
"numpy.zeros\n",
"numpy.zeros_like\n",
"\n",
"# Plus all functions mentioned in NumPy Basics\n",
"\n",
"# Not allowed:\n",
"\n",
"numpy.apply_along_axis\n",
"numpy.apply_over_axes\n",
"numpy.vectorize"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"name": "ps0.ipynb",
"provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.9"
},
"vscode": {
"interpreter": {
"hash": "b1bf6cc60825bc0168f0daef984b080cea2a9fe0c964c898af2495b9f96ac9e2"
}
}
},
"nbformat": 4,
"nbformat_minor": 1
}
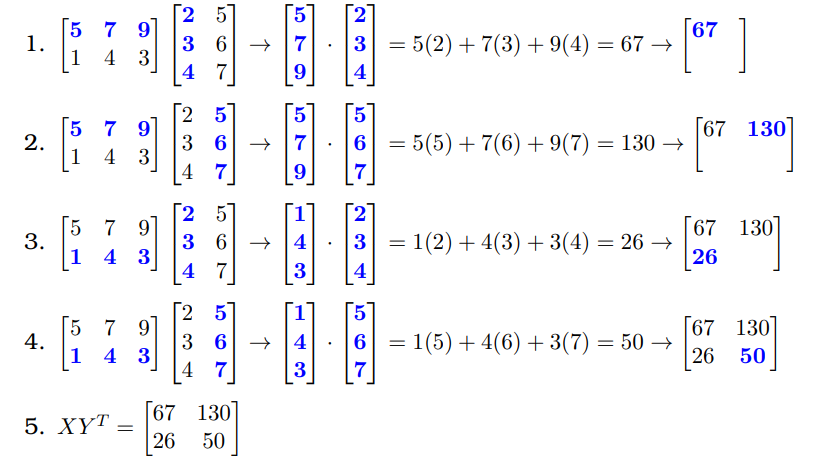 \n",
"\n",
"More formally, suppose that $A$ has dimension $n \\times m$ and $B$ has dimension $n' \\times m'$, where $m = n'$. Moreover, the $i$-th row in $A$ is denoted by $\\mathbf{r_i}$ and the $j$-th column in $B$ is denoted by $\\mathbf{c_j}$ such that\n",
"\n",
"\\begin{equation*}\n",
" B = \n",
" \\begin{bmatrix}\n",
" \\mathbf{c_0} & \\mathbf{c_1} & ... & \\mathbf{c_{m'-2}} & \\mathbf{c_{m'-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Then,\n",
"\\begin{equation}\n",
" AB =\n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0}^T \\cdot \\mathbf{c_0} & \\mathbf{r_0}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_0}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\mathbf{r_1}^T \\cdot \\mathbf{c_0} & \\mathbf{r_1}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_1}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\vdots & \\vdots & \\ddots & \\vdots\\\\\n",
" \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_0} & \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Food for thought: what is the dimension of $AB$? As a follow-up question, what does this tell us about the commutativity (or the lack of it) of matrix multiplication?\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {
"id": "3wUd3W6SrxiB"
},
"outputs": [],
"source": [
"def dot_prod(A, B):\n",
" if len(A) != len(B):\n",
" raise Exception('A and B cannot be multiplied as they have incompatible dimensions!')\n",
" return sum([A[i] * B[i] for i in range(len(A))])\n",
"\n",
"def mult_matrices(A, B):\n",
" \"\"\"\n",
" Multiplies matrix A by matrix B, giving AB.\n",
" Note\n",
" ----\n",
" Do not use numpy for this question.\n",
" \"\"\"\n",
" if len(A[0]) != len(B):\n",
" raise Exception('Incompatible dimensions for matrix multiplication of A and B')\n",
" res_rows = len(A)\n",
" res_cols = len(B[0])\n",
" result = [[0] * res_cols for _ in range(res_rows)]\n",
" trans_B = transpose_matrix(B)\n",
" for i in range(res_rows):\n",
" for j in range(res_cols):\n",
" result[i][j] = dot_prod(A[i], trans_B[j])\n",
" return result\n"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [],
"source": [
"# Test Cases for Task 1.4\n",
"A = [[5, 7, 9], [1, 4, 3]]\n",
"B = [[2, 5], [3, 6], [4, 7]]\n",
"A_copy = copy.deepcopy(A)\n",
"B_copy = copy.deepcopy(B)\n",
"\n",
"actual = mult_matrices(A, B)\n",
"expected = [[67, 130], [26, 50]]\n",
"assert(A == A_copy and B == B_copy)\n",
"assert(actual == expected)\n",
"\n",
"A2 = [[-13, -10], [-24, 14]]\n",
"B2 = [[1, 0], [0, 1]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"B2_copy = copy.deepcopy(B2)\n",
"\n",
"actual2 = mult_matrices(A2, B2)\n",
"expected2 = [[-13, -10], [-24, 14]]\n",
"assert(A2 == A2_copy and B2 == B2_copy)\n",
"assert(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uMfIOl_TvSuT"
},
"source": [
"### Task 1.5 Inverse of a Matrix"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0xaIDHhz1-x9"
},
"source": [
"This is the last task for this part of the homework. In this task, we are supposed to implement `invert_matrix`. This function takes in one argument, a matrix $A$, and tries to find the inverse of $A$. Yes, we said 'tries'.\n",
"\n",
"For the inverse of an $n \\times m$ matrix $A$ to exist, $A$ has to be a **square matrix**, i.e. $n = m$. Moreover, $A$ has to satisfy some [properties](https://en.wikipedia.org/wiki/Invertible_matrix) if you are interested in the technicalities of it. However, these are not required to complete this task. Therefore, it is not always possible to find the inverse of a matrix.\n",
"\n",
"Suppose the inverse of $A$ exists, then it is denoted by $A^{-1}$ and is such that\n",
"\\begin{equation}\n",
" AA^{-1} = I = A^{-1}A\n",
"\\end{equation}\n",
"where $I$ is the identity matrix. In other words, the dimension of $I$ depends on the context, e.g. if an invertible matrix $Q$ has a dimension of $2 \\times 2$, then $\n",
"QQ^{-1} = I =\n",
"\\begin{bmatrix}\n",
"1 & 0\\\\\n",
"0 & 1\n",
"\\end{bmatrix}\n",
"$ \n",
"with dimension $n \\times n$, diagonal entries that are all 1s, and off-diagonal entries that are all 0s, i.e.\n",
"\\begin{equation}\n",
" I_{i, j} =\n",
" \\begin{cases}\n",
" 1 & \\text{if $i = j$}\\\\\n",
" 0 & \\text{otherwise}\n",
" \\end{cases} \n",
"\\end{equation}\n",
"\n",
"For example, if we have\n",
"\\begin{equation*}\n",
" P = \n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & -4 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"then\n",
"\\begin{equation*}\n",
" P^{-1} = \n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & 4 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"We can check that this is true by computing $PP^{-1}$ and $P^{-1}P$. If the results evaluate to \n",
"$\n",
"\\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & 0 & 1\n",
"\\end{bmatrix}\n",
"$, then $P^{-1}$ is correctly computed.\n",
"\n",
"Quick question: what is the inverse of $P^{-1}$? In fact, more generally, given any *invertible matrix* $X$, i.e. $X^{-1}$ exists, what is the inverse of $X^{-1}$?\n",
"\n",
"The description of **our algorithm for finding the inverse of a matrix is as follows**.\n",
"\n",
"Given any matrix $A$, in order to attempt finding $A^{-1}$, we need to check whether $A$ is a square matrix. If it isn't, we should return False to indicate that it is not possible; otherwise, we will construct an adjacency matrix as shown below.\n",
"\n",
"\\begin{equation}\n",
" \\begin{bmatrix}\n",
" A & I\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Note that here, the adjacency matrix is of dimension $n \\times 2n$. Since both $A$ and $I$ have a dimension of $n \\times n$, placing their entries side-by-side will give $2n$ columns.\n",
"\n",
"For instance, suppose we have\n",
"\n",
"\\begin{equation*}\n",
" Z =\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2\\\\\n",
" 0 & 0 & 1\\\\\n",
" 1 & 5 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Then, the adjacency matrix is given by\n",
"\\begin{equation*}\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 1 & 5 & 3 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Next, for each $i$ th row in the augmented matrix, do the following\n",
"\n",
"1. Find a row $k$, where $i \\leq k \\leq (n - 1)$, that has a non-zero-valued entry in its $i$ th column, and swap it with the $i$ th row. If no such row exists, return False. The matrix is not invertible.\n",
"2. Multiply the new $i$ th row by a scalar such that the value in the $i$ th column becomes 1.\n",
"3. Add multiples of the new $i$ th row to all other rows such that the value in their $i$ th column becomes 0.\n",
"\n",
"Finally, get the last $n$ columns that is found in the resulting adjacency matrix. These columns form $A^{-1}$, i.e. if $\\mathbf{c_i}$ denotes the $i$ th column in the adjacency matrix, then\n",
"\\begin{equation}\n",
" A^{-1} =\n",
" \\begin{bmatrix}\n",
" \\mathbf{c_n} & \\mathbf{c_{n + 1}} & ... & \\mathbf{c_{2n - 1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Let us run through this algorithm to find $Z^{-1}$.\n",
"1. We have the adjacency matrix \n",
"$\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 1 & 5 & 3 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
"$\n",
" We shall swap the 2nd row with the 0th row, giving\n",
" $\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" \\end{bmatrix}\n",
" $\n",
"2. Since the value of $(0, 0)$ entry is 1, we don't need to multiply the 0th row by any scalar. Moreover, we do not need to add multiples of this row to the other rows because the value of the entry in the 0th column of the other rows are all 0s.\n",
"3. Moving on to $i = 1$, we see that we need to swap the last row with the $1$st row, giving \n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"4. Since the value of the $(1, 1)$ entry is 3, we need to divide the 1st row by $3$, giving\n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 1 & \\frac{2}{3} & \\frac{1}{3} & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"5. Given that the value of the $(0, 1)$ entry is 5, not 0, we need to add $-5 \\times \\mathbf{a_1}$, where $\\mathbf{a_1}$ represents the 1st row in the current adjacency matrix, to the 0th row. This leaves us with\n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 0 & -\\frac{1}{3} & -\\frac{5}{3} & 0 & 1\\\\\n",
" 0 & 1 & \\frac{2}{3} & \\frac{1}{3} & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"6. Now, $i = 2$. Observe that there are no other rows that can be swapped with the last row, since in this case substituting $i = 2$, we have $2 \\leq k \\leq 2 \\implies k = 2$. Moreover, we don't need to multiply the 2nd row by a scalar since the value in its last column is 1.\n",
"7. To get 0s in the last column of the other rows, we need to add $\\frac{1}{3} \\times \\mathbf{a_2}$ and $-\\frac{2}{3} \\times \\mathbf{a_2}$, where $\\mathbf{a_2}$ represents the last row in the adjacency matrix shown in step 6, to the 0th and 1st row, respectively. The result is \n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0 & -\\frac{5}{3} & \\frac{1}{3} & 1\\\\\n",
" 0 & 1 & 0 & \\frac{1}{3} & -\\frac{2}{3} & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"8. Finally, we can get $Z^{-1}$ by taking the last 3 columns.\n",
"\\begin{equation}\n",
" Z^{-1} = \n",
" \\begin{bmatrix}\n",
" -\\frac{5}{3} & \\frac{1}{3} & 1\\\\\n",
" \\frac{1}{3} & -\\frac{2}{3} & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Implement the function `invert_matrix` that takes in a matrix $A$ and returns the inverse matrix. If $A$ is not invertible, `invert_matrix` should return `False`.\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {
"id": "m1XBH6qwrytj"
},
"outputs": [],
"source": [
"def invert_matrix(A):\n",
" \"\"\"\n",
" Returns the inverse of matrix A, if it exists; otherwise, returns False\n",
" \"\"\"\n",
" if len(A[0]) != len(A):\n",
" return False\n",
" A_len = len(A)\n",
" result = copy.deepcopy(A)\n",
" # Step 0\n",
" for i in range(A_len):\n",
" result[i].extend([0] * A_len)\n",
" result[i][i + A_len] = 1\n",
" result = [[float(i) for i in row] for row in result]\n",
" # Step 1\n",
" for i in range(A_len):\n",
" # Step 1\n",
" for k in range(i, A_len):\n",
" if result[k][i] != 0:\n",
" break\n",
" if result[k][i] == 0:\n",
" return False\n",
" result[i], result[k] = result[k], result[i]\n",
" # Step 2\n",
" scalar = 1 / result[i][i]\n",
" result[i] = [scalar * x for x in result[i]]\n",
" # Step 3: Add multiples of the new ith row to all other rows such that the value in their ith column becomes 0\n",
" for k in range(A_len):\n",
" if k == i:\n",
" continue\n",
" scalar = -result[k][i]\n",
" result[k] = [result[k][j] + scalar * result[i][j] for j in range(2 * A_len)]\n",
" \n",
" for i in range(A_len):\n",
" result[i] = result[i][A_len:]\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": 39,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 1.5\n",
"A = [[1, 0 ,0], [0, 1, 0], [0, -4, 1]]\n",
"A_copy = copy.deepcopy(A)\n",
"\n",
"actual = invert_matrix(A)\n",
"expected = [[1, 0 ,0], [0, 1, 0], [0, 4, 1]]\n",
"assert(A == A_copy)\n",
"for i in range(len(A)):\n",
" for j in range(len(A[0])):\n",
" assert(round(actual[i][j], 11) == round(expected[i][j], 11))\n",
" \n",
" \n",
"A2 = [[0, 3, 2], [0, 0, 1], [1, 5, 3]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"\n",
"actual2 = invert_matrix(A2)\n",
"expected2 = [[-5/3, 1/3 ,1], [1/3, -2/3, 0], [0, 1, 0]]\n",
"assert(A2 == A2_copy)\n",
"for i in range(len(A2)):\n",
" for j in range(len(A2[0])):\n",
" assert(round(actual2[i][j], 11) == round(expected2[i][j], 11))\n",
" \n",
" \n",
"A3 = [[1, 0, 0], [0, 1, 0], [0, 0, 0]] # non-invertible matrix\n",
"actual3 = invert_matrix(A3)\n",
"expected3 = False\n",
"assert actual3 == expected3"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "J4pQSFqk5pi6"
},
"source": [
"# Part 2: Introduction to NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "v7NPTROk6Dp9"
},
"source": [
"Now that we have a better grasp of Python, let us take a look at NumPy, a commonly used package for multidimensional array manipulation! This will come in handy when we work with certain machine learning models later in the semester. Besides, in machine learning problems, large amount of data is usually present, necessitating approaches that make manipulating them easy and fast; and one such approach is to represent our data as multidimensional arrays before manipulating them.\n",
"\n",
"The tasks in this section are designed to give us the opportunity to apply what we are about to learn about NumPy to analyse [COVID-19 data](https://github.com/OxCGRT/covid-policy-tracker)."
]
},
{
"cell_type": "code",
"execution_count": 40,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Invert array without NumPy takes 0.24375009536743164s\n",
"Invert array with NumPy takes 0.0015101432800292969s\n"
]
}
],
"source": [
"import random\n",
"import time\n",
"\n",
"import numpy as np\n",
"\n",
"random.seed(2109)\n",
"A = [[random.random() for j in range(100)] for i in range(100)] # 100 x 100\n",
"start = time.time()\n",
"_ = invert_matrix(A)\n",
"end = time.time()\n",
"print(f'Invert array without NumPy takes {end - start}s')\n",
"\n",
"A_numpy = np.array(A)\n",
"start = time.time()\n",
"_ = np.linalg.inv(A)\n",
"end = time.time()\n",
"print(f'Invert array with NumPy takes {end - start}s')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note that **each task is independent**. In other words, even if you are stuck at a particular question, it is still possible to get full marks for the later questions.\n",
"\n",
"**IMPORTANT**: It is critical that we realise that the underlying implementation of the operations available in NumPy are often optimised for performance. As a result, using these operations, as opposed to iterative approaches, to manipulate elements in the array will often lead to more performant code. This, coupled with the fact that we want to practise using NumPy in this part of the homework, means that **your implementation in the following tasks should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops**. Instead, please work with the operations available in NumPy. \n",
"\n",
"You are allowed to use any [mathematical functions](https://numpy.org/doc/stable/reference/routines.math.html), but this **does not mean that you are allowed to use any NumPy functions** (there are NumPy functions that aren't mathematical functions). For example,[ np.vectorize ](https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html) is not allowed since it is iterative. Please refer to the forum post \"List of allowed numpy functions for assignments\" under \"Homework\" for a (non-exhaustive) list of functions that are considered non-iterative for PS0 and for the CS2109S course. If you are in doubt about an unlisted function, please ask in the forum. **Solutions that violate this will be heavily penalised**."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "z0uLebHS7W6u"
},
"source": [
"## NumPy Basics"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "yVL9SBwa7Y00"
},
"source": [
"### Import NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "R9eik6gP7c9r"
},
"source": [
"In order to use NumPy, we need to import it. This can be done by"
]
},
{
"cell_type": "code",
"execution_count": 41,
"metadata": {
"id": "GGPjViIWry89"
},
"outputs": [],
"source": [
"import numpy\n",
"a = numpy.arange(5) # Returns a NumPy array [0, 1, 2, 3, 4]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dA4YI8LT7kCB"
},
"source": [
"However, it is customary to use the shorthand np instead. Therefore, we will do"
]
},
{
"cell_type": "code",
"execution_count": 42,
"metadata": {
"id": "V5P8ESNy7lye"
},
"outputs": [],
"source": [
"import numpy as np\n",
"a = np.arange(5) # Note that here we use `np` instead of `numpy`"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UQaoJky47t6s"
},
"source": [
"### NumPy Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "W3NDseCE7-WB"
},
"source": [
"NumPy arrays are objects in NumPy that represent multidimensional arrays. Such\n",
"arrays have the data type `numpy.ndarray`, or `np.ndarray` for short. Unlike Python lists, NumPy arrays cannot store data that are of different types.\n",
"\n",
"To create a NumPy array from a Python list, we can do"
]
},
{
"cell_type": "code",
"execution_count": 44,
"metadata": {
"id": "1unOnNqB72_3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(3,)\n",
"1 2 3\n",
"[9 2 3]\n",
"(2, 3)\n",
"1 5 3\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([1, 2, 3]) # Create 1D array vector\n",
"print(a.shape) # Prints(3, )\n",
"print(a[0], a[1], a[2]) # Prints 1, 2, 3\n",
"a[0] = 9 # Change the zeroth element to 9\n",
"print(a) # Prints[9 2 3]\n",
"\n",
"b = np.array([[1, 2, 3], [4, 5, 6]]) # Creates 2D array (matrix)\n",
"print(b.shape) # Prints(2, 3)\n",
"print(b[0, 0], b[1, 1], b[0, 2]) # Prints 1, 5, 3\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tW_eQ0CN8uvW"
},
"source": [
"Alternatively, we can also create pre-filled arrays with a specified shape with certain NumPy functions. Several examples of these are shown below."
]
},
{
"cell_type": "code",
"execution_count": 45,
"metadata": {
"id": "ZlO57Ak38pX3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Object a\n",
"[[0. 0. 0.]\n",
" [0. 0. 0.]\n",
" [0. 0. 0.]]\n",
"Object b\n",
"[1. 1.]\n",
"Object c\n",
"[[1. 1. 1.]\n",
" [1. 1. 1.]\n",
" [1. 1. 1.]]\n",
"Object d\n",
"[[False False False]\n",
" [False False False]]\n",
"Object e\n",
"[0 1 2 3 4]\n"
]
}
],
"source": [
"a = np.zeros((3, 3)) # Create 3x3 matrix with all zeros\n",
"b = np.ones(2) # Create vector of size 2 with all ones\n",
"c = np.ones((3, 3)) # Create 3x3 matrix with all ones\n",
"d = np.full((2, 3), False) # Create a constant array\n",
"e = np.arange(5) # Creates a 1D array with values [0, 5)\n",
"\n",
"print('Object a')\n",
"print(a)\n",
"print('Object b')\n",
"print(b)\n",
"print('Object c')\n",
"print(c)\n",
"print('Object d')\n",
"print(d)\n",
"print('Object e')\n",
"print(e)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oc4X5elN9oNp"
},
"source": [
"Note that we can use functions like `np.zeros` and `np.ones` to pre-allocate arrays. We can then assign values to the entries using indexing.\n",
"More information about array creation in NumPy can be found [here](https://numpy.org/doc/stable/user/basics.creation.html#arrays-creation)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "TQ-gm6-I9yxd"
},
"source": [
"### Basic Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MKuUe8Dj96Mn"
},
"source": [
"Accessing the value of an element in a NumPy array is similar to that of lists in Python. However, observe that in the following, instead of doing something like a[i][j], we have `a[i, j]`."
]
},
{
"cell_type": "code",
"execution_count": 46,
"metadata": {
"id": "aVtAsMWM-Bsi"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\n",
"6\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"print(a[0, 0]) # Prints 1\n",
"print(a[1, 2]) # Prints 6"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Eghq5yqQ-IEN"
},
"source": [
"Slicing works very similarly too! For example,"
]
},
{
"cell_type": "code",
"execution_count": 47,
"metadata": {
"id": "WH1UVm53-JRA"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2 3]\n",
"[[2 3]\n",
" [5 6]]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3, 4], [4, 5, 6, 7]])\n",
"print(a[0, 1:3]) # Prints [2, 3]\n",
"print(a[:, 1:3]) # Prints [[2 3]\n",
" # [5 6]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YEC-5kzB96Qe"
},
"source": [
"However, do be careful of aliasing. The following illustrates an example of a side-effect that is caused by aliasing."
]
},
{
"cell_type": "code",
"execution_count": 48,
"metadata": {
"id": "b4aPSc9V9FqU"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"5\n"
]
}
],
"source": [
"b = a # Aliasing\n",
"b[0, 0] = 5\n",
"print(a[0, 0]) # Prints \"5\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "B7icHqWF-Sy3"
},
"source": [
"### Element-Wise Math Operation"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NISyJMKR-XWO"
},
"source": [
"NumPy provides several *element-wise math operations*. For example,"
]
},
{
"cell_type": "code",
"execution_count": 49,
"metadata": {
"id": "vNx9Wz_c-ROf"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 6 8]\n",
" [10 12]]\n",
"[[ 5 12]\n",
" [21 32]]\n"
]
}
],
"source": [
"x = np.array([[1,2],[3,4]])\n",
"y = np.array([[5,6],[7,8]])\n",
"\n",
"print(x + y) # Prints [[ 6 8]\n",
" # [10 12]]\n",
"\n",
"print(x * y) # Prints [[ 5 12]\n",
" # [21 32]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "81ptLkxU-a-w"
},
"source": [
"Similarly, operations for subtraction and division are also provided, and are given by `-` and `/`, respectively.\n",
"\n",
"**Note**: `*` is an element-wise multiplication of two matrices, not a matrix multiplication of\n",
"two matrices, as covered in task 1.4."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### General Math Operation"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"NumPy provides many *math operations*. We give some examples below. For a full list of what Numpy can do, please have a look at the following links:\n",
"\n",
"* [Math](https://numpy.org/doc/stable/reference/routines.math.html)\n",
"* [Statistics](https://numpy.org/doc/stable/reference/routines.statistics.html)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sum\n",
"\n",
"`numpy.sum` computes the sum of array elements over a given axis.\n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 50,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.0\n",
"2.0\n",
"6\n",
"[0 6]\n",
"[1 5]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"print(np.sum([])) # 0.0\n",
"print(np.sum([0.5, 1.5])) # 2.0\n",
"print(np.sum([[0, 1], [0, 5]])) # 6\n",
"print(np.sum([[0, 1], [0, 5]], axis=0)) # array([0, 6])\n",
"print(np.sum([[0, 1], [0, 5]], axis=1)) # array([1, 5])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Mean\n",
"\n",
"`numpy.mean` computes the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. \n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 51,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2.5\n",
"[2. 3.]\n",
"[1.5 3.5]\n"
]
}
],
"source": [
"a = np.array([[1, 2], [3, 4]])\n",
"print(np.mean(a)) # 2.5\n",
"print(np.mean(a, axis=0)) # array([2., 3.])\n",
"print(np.mean(a, axis=1)) # array([1.5, 3.5])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Floor & Ceil\n",
"\n",
"`numpy.floor` returns the floor of the input, element-wise. The floor of the scalar $x$ is the largest integer $i$, such that $i \\le x$. It is often denoted as $\\lfloor x \\rfloor$.\n",
"\n",
"`numpy.ceil` returns the ceiling of the input, element-wise. The ceil of the scalar x is the smallest integer i, such that i >= x. It is often denoted as $\\lceil x \\rceil$.\n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 54,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[-2. -2. -1. 0. 1. 1. 2.]\n",
"[-1. -1. -0. 1. 2. 2. 2.]\n"
]
}
],
"source": [
"a = np.array([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0])\n",
"print(np.floor(a)) # array([-2., -2., -1., 0., 1., 1., 2.])\n",
"print(np.ceil(a)) # array([-1., -1., -0., 1., 2., 2., 2.])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F-qWcOyh-q-w"
},
"source": [
"## COVID-19 Data as NumPy Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nu8iuUGZ-trh"
},
"source": [
"Now that we understand the representation of NumPy arrays, we will try to learn how to use NumPy by working on some practical problems. In particular, we shall take a look at the COVID-19 data which will be used in the following tasks. These data are [time series data](https://en.wikipedia.org/wiki/Time_series) obtained from 1 January 2020 to 31 December 2020. \n",
"\n",
"For the convenience of notation, we shall refer to 1 January 2020 as the $1$st day and 31 December 2019 as the $0$th day. Observe that this means that the following data **do not** contain measurements on the 0th day, i.e. 31 December 2019.} In addition, in the following tasks, assume that $i, j \\geq 0$, whenever they are used as indexes.\n",
"\n",
"First, let us describe the data set that we will be working with. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uLwkuhfF3PiC"
},
"source": [
"### **`cases_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HUbvGwPK3UPD"
},
"source": [
"It is a 2D `np.ndarray` with each row representing the data of a country while the columns of each row represent the time series data of the cumulative number of confirmed cases in that country, i.e. the $i$-th row of `cases_cumulative` contains the data of the $i$-th country, and the $(i, j)$ entry of `cases_cumulative` is the *cumulative number* of confirmed cases on the $(j + 1)$th day in the $i$th country.\n",
"\n",
"For example, suppose"
]
},
{
"cell_type": "code",
"execution_count": 53,
"metadata": {
"id": "3gbHqkGa-fkB"
},
"outputs": [],
"source": [
"cases_cumulative = np.array([[0, 1, 2, 3], [0, 20, 21, 35]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kGeE-oed3ofk"
},
"source": [
"This means that the 0th country has recorded 0, 1, 2 and 3 cases on the 1st, 2nd, 3rd and 4th day, respectively. Similarly, the 1st country has recorded 0, 20, 21 and 35 cases on the 1st, 2nd, 3rd and 4th day.\n",
"\n",
"**Important**:\n",
"\n",
"Observe that ${(i, j)}$ entry corresponds to the data for the ${i}$-th country but ${(j + 1)}$-th day. For day 0, assume that the number of cases recorded is 0 for all countries.\n",
"\n",
"Here, *cumulative number* means that the recorded data is the total number of cases detected since day 0, not only the new cases that have been detected on a particular day. Hence, generally, `cases_cumulative[i, j]` $\\leq$ `cases_cumulative[i, j + 1]`.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "K-bF65CK3tBV"
},
"source": [
"### **`cases_top_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oV4X8qcY4N8u"
},
"source": [
"This variable is similar to `cases_cumulative`. However, it only contains data for the three countries that recorded the most number of confirmed COVID-19 cases in 2020. These data might come in handy during debugging and testing.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XPBq32dV4SpE"
},
"source": [
"### **`deaths_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hATkVnyx4ViC"
},
"source": [
"`deaths_cumulative` is similar to `cases_cumulative`, but instead of recording the cumulative number of confirmed cases, it records the cumulative number of deaths caused by COVID-19.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hdnlmCc04kzp"
},
"source": [
"### **`healthcare_spending`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SjvPjJ9i4k28"
},
"source": [
"This is a 2D `np.ndarray` with each row representing the data of a country while the columns of each row represent the time series data of the emergency healthcare spending made by that country, i.e. the $i$-th row of `healthcare_spending` contains the data of the $i$-th country, and the $(i, j)$ entry of `healthcare_spending` is the amount which the $i$-th country spent on healthcare on the $(j + 1)$-th day. Assume that the healthcare spending on the 0-th day is \\$0 for all countries.\n",
"\n",
"For example, suppose"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "L5Dg8kPE3rid"
},
"outputs": [],
"source": [
"healthcare_spending = np.array([[0, 100, 0, 200], [0, 0, 0, 1000]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "AIKQ6qCb46hu"
},
"source": [
"Then, the 0th country only made an emergency expenditure on healthcare on the 2nd and 4th days that amounted to \\$100 and \\$200, respectively; similarly, the 1st country only made an emergency expenditure on the 4th day which amounted to \\$1000.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "mtbqt7uC5Bv3"
},
"source": [
"### **`mask_prices`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ce-xxi_t5Dlo"
},
"source": [
"`mask_prices` is a 1D `np.ndarray` such that the $j$-th entry represents the global average cost of 100 masks on the $(j + 1)$-th day.\n",
"\n",
"For example, if"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4x0dxMTJ4-X8"
},
"outputs": [],
"source": [
"mask_prices = np.array([4, 5, 20, 18])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WCnTULNz5R8y"
},
"source": [
"then the global average cost of 100 masks on the 1st, 2nd, 3rd and 4th day is \\$4, \\$5, \\$20 and \\$18, respectively.\n",
"\n",
"**Note**: The prices are not real but the overall fluctuations are chosen to simulate those observed in 2020."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n70RPHKx5fne"
},
"source": [
"### **`stringency_values`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_4yj4Ts55hsE"
},
"source": [
"This variable is a 3D `np.ndarray` with each row representing the data of a country, and the columns of each row representing the time series data of the stringency values as a vector. To be specific, on each day, there are four different stringency indicators: 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls'. \n",
"\n",
"For instance, suppose"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "JY_K3jkh5Yo_"
},
"outputs": [],
"source": [
"stringency_values = np.array([[[0, 0, 0, 0], [1, 0, 0, 0]],\\\n",
" [[0, 0, 0, 0], [0, 1, 2, 0]]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8Beq-_7r5hxI"
},
"source": [
"This means that for the 0th country, on the 1st day, the stringency values for 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls' were all 0. On the 2nd day, all the stringency values remained the same, except for 'school closing', which rose to 1.\n",
"\n",
"As for the 1st country, on the 1st day, the stringency values were the same as the 0th country's. However, on the 2nd day, the stringency values for 'workplace closing' and 'stay at home requirements' rose to 1 and 2, respectively.\n",
"\n",
"In this context, the higher the stringency value, the more restrictive the policy is."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Get the data from CSV"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As shown in the last few lines of `ps0.py`, we can get the data for these variables by doing the following"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from prepare_data import * # loads the `get_...` helper funtions\n",
"\n",
"df = get_data()\n",
"cases_cumulative = get_n_cases_cumulative(df)\n",
"deaths_cumulative = get_n_deaths_cumulative(df)\n",
"healthcare_spending = get_healthcare_spending(df)\n",
"mask_prices = get_mask_prices(healthcare_spending.shape[1])\n",
"stringency_values = get_stringency_values(df)\n",
"cases_top_cumulative = get_n_cases_top_cumulative(df)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iUOLLiiK52kC"
},
"source": [
"In the upcoming tasks, we will be manipulating these data, and finding answers to certain questions that we might have about issues that are related to COVID-19.\n",
"\n",
"**IMPORTANT**: You are allowed to use any of the [mathematical functions](https://numpy.org/doc/stable/reference/routines.math.html) from NumPy in all of the following tasks.\n",
"For your convenience, you may use some of the non-mathematical functions provided by NumPy, but not all of them. For example, [`np.vectorize`](https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html) isn't allowed since it is iterative. If in doubt, do ask in the forum :) With this said, do note that it is absolutely possible to complete these tasks without the non-mathematical functions that are not introduced in this document.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XtMITSIQ6wXR"
},
"source": [
"## Task 2.1: Computing Death Rates"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9BTFV_PG6yvu"
},
"source": [
"Our first task in this part of the homework is to implement `compute_death_rate_first_n_days`, which takes in three arguments, `n`, `cases_cumulative` and `deaths_cumulative`, and **computes the average number of deaths recorded for every confirmed case that has been recorded from the first day to the nth day (inclusive)**. This should be done for each country.\n",
"\n",
"The return value should be a `np.ndarray` such that the entry in the $i$-th row corresponds to the death rate in the $i$-th country as represented in `cases_cumulative` and `deaths_cumulative`.\n",
"\n",
"For instance, if the returned value is `np.array([0.5, 0.2])`, it means that in the 0th country, for every 2 individuals who contracted the virus, one of them will, on average, die. In contrast, in the 1st country, for every 5 individuals who contracted the virus, only one of them will, on average, die.\n",
"\n",
"**Note**:\n",
"You may assume that the $i$-th row in `cases_cumulative` represents the same country as the $i$-th row in `deaths_cumulative`. Moreover, if there are no confirmed cases for a particular country, its average death rate should be zero. If the data includes less than `n` days of data, then you just return the result for all the days given in the data provided. \n",
"\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to deal with `nan` values using `np.nan_to_num`, which has the following signature: `numpy.nan_to_num(x, copy=True, nan=0.0, posinf=None, neginf=None)`. You should also check out the detailed description [here](https://numpy.org/doc/stable/reference/generated/numpy.nan_to_num.html) because there are many functions of the same nature. Essentially, we can use `np.nan_to_num` to convert all the `nan` values in an `np.ndarray` to a specified value. Some examples of how `np.nan_to_num` can be used is shown below:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(np.nan_to_num(np.inf)) #1.7976931348623157e+308\n",
"print(np.nan_to_num(-np.inf)) #-1.7976931348623157e+308\n",
"print(np.nan_to_num(np.nan)) #0.0\n",
"x = np.array([np.inf, -np.inf, np.nan, -128, 128])\n",
"np.nan_to_num(x)\n",
"np.nan_to_num(x, nan=-9999, posinf=33333333, neginf=33333333) # Specify nan to be -9999, and both posinf and neginf to be 33333333\n",
"np.nan_to_num(y, nan=111111, posinf=222222) # Specify nan to be 111111, and both posinf and neginf to be 222222"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SOF2JEoW5xJE"
},
"outputs": [],
"source": [
"def compute_death_rate_first_n_days(n, cases_cumulative, deaths_cumulative):\n",
" '''\n",
" Computes the average number of deaths recorded for every confirmed case\n",
" that is recorded from the first day to the nth day (inclusive).\n",
" Parameters\n",
" ----------\n",
" n: int\n",
" How many days of data to return in the final array.\n",
" cases_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed cases in that country, i.e. the ith row of `cases_cumulative`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `cases_cumulative` is the cumulative number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" deaths_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed deaths (as a result of COVID-19) in that country, i.e. the ith\n",
" row of `n_deaths_cumulative` contains the data of the ith country, and\n",
" the (i, j) entry of `n_deaths_cumulative` is the cumulative number of\n",
" confirmed deaths on the (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Average number of deaths recorded for every confirmed case from the first day\n",
" to the nth day (inclusive) for each country as a 1D `ndarray` such that the\n",
" entry in the ith row corresponds to the death rate in the ith country as\n",
" represented in `cases_cumulative` and `deaths_cumulative`.\n",
" Note\n",
" ----\n",
" `cases_cumulative` and `deaths_cumulative` are such that the ith row in the \n",
" former and that in the latter contain data of the same country. In addition,\n",
" if there are no confirmed cases for a particular country, the expected death\n",
" rate for that country should be zero. (Hint: to deal with NaN look at\n",
" `np.nan_to_num`)\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test cases for Task 2.1\n",
"n_cases_cumulative = cases_cumulative[:3, :] #Using data from CSV. Make sure to run relevant cell above\n",
"n_deaths_cumulative = deaths_cumulative[:3, :]\n",
"expected = np.array([0.0337837838, 0.0562347188, 0.1410564226])\n",
"np.testing.assert_allclose(compute_death_rate_first_n_days(100, n_cases_cumulative, n_deaths_cumulative), expected)\n",
"\n",
"sample_cumulative = np.array([[1,2,3,4,8,8,10,10,10,10], [1,2,3,4,8,8,10,10,10,10]])\n",
"sample_death = np.array([[0,0,0,1,2,2,2,2,5,5], [0,0,0,1,2,2,2,2,5,5]])\n",
"\n",
"expected2 = np.array([0.5, 0.5])\n",
"assert(np.all(compute_death_rate_first_n_days(10, sample_cumulative, sample_death) == expected2))\n",
"\n",
"sample_cumulative2 = np.array([[1,2,3,4,8,8,10,10,10,10]])\n",
"sample_death2 = np.array([[0,0,0,1,2,2,2,2,5,5]])\n",
"\n",
"expected3 = np.array([0.5])\n",
"assert(compute_death_rate_first_n_days(10, sample_cumulative2, sample_death2) == expected3)\n",
"expected4 = np.array([0.25])\n",
"assert(compute_death_rate_first_n_days(5, sample_cumulative2, sample_death2) == expected4)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uCQ7_juB7ks0"
},
"source": [
"## Task 2.2: Computing Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E7W2-0HI72VS"
},
"source": [
"Our second task requires us to implement `compute_increase_in_cases` which accepts one argument `cases_cumulative` and **computes the daily increase in confirmed cases for each country, starting from the first day**.\n",
"\n",
"This function should return the daily increase in cases for each country as a 2D `np.ndarray` such that the $(i, j)$ entry corresponds to the increase in confirmed cases in the $i$-th country on the $(j + 1)$-th day, where $j$ is non-negative.\n",
"\n",
"Recall that as we have previously mentioned, the number of cases on the 0th day can be assumed to be 0 for all countries.\n",
"\n",
"To be specific, suppose `cases_cumulative` only contains data for 4 days such that it is equal to `np.array([[1, 2, 3, 4], [1, 3, 6, 10]])`. Then, the return value of this function should be `np.array([[1, 1, 1, 1], [1, 2, 3, 4]])`. This means that from days 1 to 4, in country 0, there was one new recorded case on each day. In contrast, in country 1, there were 2, 3 and 4 new cases on days 2, 3 and 4, respectively.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to compute differences between adjacent elements in an array using `np.diff`, which has the following signature: `numpy.diff(a, n=1, axis=-1, prepend=
\n",
"\n",
"More formally, suppose that $A$ has dimension $n \\times m$ and $B$ has dimension $n' \\times m'$, where $m = n'$. Moreover, the $i$-th row in $A$ is denoted by $\\mathbf{r_i}$ and the $j$-th column in $B$ is denoted by $\\mathbf{c_j}$ such that\n",
"\n",
"\\begin{equation*}\n",
" B = \n",
" \\begin{bmatrix}\n",
" \\mathbf{c_0} & \\mathbf{c_1} & ... & \\mathbf{c_{m'-2}} & \\mathbf{c_{m'-1}}\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Then,\n",
"\\begin{equation}\n",
" AB =\n",
" \\begin{bmatrix}\n",
" \\mathbf{r_0}^T \\cdot \\mathbf{c_0} & \\mathbf{r_0}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_0}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\mathbf{r_1}^T \\cdot \\mathbf{c_0} & \\mathbf{r_1}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_1}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\vdots & \\vdots & \\ddots & \\vdots\\\\\n",
" \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_0} & \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_1} & ... & \\mathbf{r_{n-1}}^T \\cdot \\mathbf{c_{m'-1}}\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Food for thought: what is the dimension of $AB$? As a follow-up question, what does this tell us about the commutativity (or the lack of it) of matrix multiplication?\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {
"id": "3wUd3W6SrxiB"
},
"outputs": [],
"source": [
"def dot_prod(A, B):\n",
" if len(A) != len(B):\n",
" raise Exception('A and B cannot be multiplied as they have incompatible dimensions!')\n",
" return sum([A[i] * B[i] for i in range(len(A))])\n",
"\n",
"def mult_matrices(A, B):\n",
" \"\"\"\n",
" Multiplies matrix A by matrix B, giving AB.\n",
" Note\n",
" ----\n",
" Do not use numpy for this question.\n",
" \"\"\"\n",
" if len(A[0]) != len(B):\n",
" raise Exception('Incompatible dimensions for matrix multiplication of A and B')\n",
" res_rows = len(A)\n",
" res_cols = len(B[0])\n",
" result = [[0] * res_cols for _ in range(res_rows)]\n",
" trans_B = transpose_matrix(B)\n",
" for i in range(res_rows):\n",
" for j in range(res_cols):\n",
" result[i][j] = dot_prod(A[i], trans_B[j])\n",
" return result\n"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [],
"source": [
"# Test Cases for Task 1.4\n",
"A = [[5, 7, 9], [1, 4, 3]]\n",
"B = [[2, 5], [3, 6], [4, 7]]\n",
"A_copy = copy.deepcopy(A)\n",
"B_copy = copy.deepcopy(B)\n",
"\n",
"actual = mult_matrices(A, B)\n",
"expected = [[67, 130], [26, 50]]\n",
"assert(A == A_copy and B == B_copy)\n",
"assert(actual == expected)\n",
"\n",
"A2 = [[-13, -10], [-24, 14]]\n",
"B2 = [[1, 0], [0, 1]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"B2_copy = copy.deepcopy(B2)\n",
"\n",
"actual2 = mult_matrices(A2, B2)\n",
"expected2 = [[-13, -10], [-24, 14]]\n",
"assert(A2 == A2_copy and B2 == B2_copy)\n",
"assert(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uMfIOl_TvSuT"
},
"source": [
"### Task 1.5 Inverse of a Matrix"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0xaIDHhz1-x9"
},
"source": [
"This is the last task for this part of the homework. In this task, we are supposed to implement `invert_matrix`. This function takes in one argument, a matrix $A$, and tries to find the inverse of $A$. Yes, we said 'tries'.\n",
"\n",
"For the inverse of an $n \\times m$ matrix $A$ to exist, $A$ has to be a **square matrix**, i.e. $n = m$. Moreover, $A$ has to satisfy some [properties](https://en.wikipedia.org/wiki/Invertible_matrix) if you are interested in the technicalities of it. However, these are not required to complete this task. Therefore, it is not always possible to find the inverse of a matrix.\n",
"\n",
"Suppose the inverse of $A$ exists, then it is denoted by $A^{-1}$ and is such that\n",
"\\begin{equation}\n",
" AA^{-1} = I = A^{-1}A\n",
"\\end{equation}\n",
"where $I$ is the identity matrix. In other words, the dimension of $I$ depends on the context, e.g. if an invertible matrix $Q$ has a dimension of $2 \\times 2$, then $\n",
"QQ^{-1} = I =\n",
"\\begin{bmatrix}\n",
"1 & 0\\\\\n",
"0 & 1\n",
"\\end{bmatrix}\n",
"$ \n",
"with dimension $n \\times n$, diagonal entries that are all 1s, and off-diagonal entries that are all 0s, i.e.\n",
"\\begin{equation}\n",
" I_{i, j} =\n",
" \\begin{cases}\n",
" 1 & \\text{if $i = j$}\\\\\n",
" 0 & \\text{otherwise}\n",
" \\end{cases} \n",
"\\end{equation}\n",
"\n",
"For example, if we have\n",
"\\begin{equation*}\n",
" P = \n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & -4 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"then\n",
"\\begin{equation*}\n",
" P^{-1} = \n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & 4 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"We can check that this is true by computing $PP^{-1}$ and $P^{-1}P$. If the results evaluate to \n",
"$\n",
"\\begin{bmatrix}\n",
" 1 & 0 & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" 0 & 0 & 1\n",
"\\end{bmatrix}\n",
"$, then $P^{-1}$ is correctly computed.\n",
"\n",
"Quick question: what is the inverse of $P^{-1}$? In fact, more generally, given any *invertible matrix* $X$, i.e. $X^{-1}$ exists, what is the inverse of $X^{-1}$?\n",
"\n",
"The description of **our algorithm for finding the inverse of a matrix is as follows**.\n",
"\n",
"Given any matrix $A$, in order to attempt finding $A^{-1}$, we need to check whether $A$ is a square matrix. If it isn't, we should return False to indicate that it is not possible; otherwise, we will construct an adjacency matrix as shown below.\n",
"\n",
"\\begin{equation}\n",
" \\begin{bmatrix}\n",
" A & I\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Note that here, the adjacency matrix is of dimension $n \\times 2n$. Since both $A$ and $I$ have a dimension of $n \\times n$, placing their entries side-by-side will give $2n$ columns.\n",
"\n",
"For instance, suppose we have\n",
"\n",
"\\begin{equation*}\n",
" Z =\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2\\\\\n",
" 0 & 0 & 1\\\\\n",
" 1 & 5 & 3\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Then, the adjacency matrix is given by\n",
"\\begin{equation*}\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 1 & 5 & 3 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
"\\end{equation*}\n",
"\n",
"Next, for each $i$ th row in the augmented matrix, do the following\n",
"\n",
"1. Find a row $k$, where $i \\leq k \\leq (n - 1)$, that has a non-zero-valued entry in its $i$ th column, and swap it with the $i$ th row. If no such row exists, return False. The matrix is not invertible.\n",
"2. Multiply the new $i$ th row by a scalar such that the value in the $i$ th column becomes 1.\n",
"3. Add multiples of the new $i$ th row to all other rows such that the value in their $i$ th column becomes 0.\n",
"\n",
"Finally, get the last $n$ columns that is found in the resulting adjacency matrix. These columns form $A^{-1}$, i.e. if $\\mathbf{c_i}$ denotes the $i$ th column in the adjacency matrix, then\n",
"\\begin{equation}\n",
" A^{-1} =\n",
" \\begin{bmatrix}\n",
" \\mathbf{c_n} & \\mathbf{c_{n + 1}} & ... & \\mathbf{c_{2n - 1}}\n",
" \\end{bmatrix}\n",
"\\end{equation}\n",
"\n",
"Let us run through this algorithm to find $Z^{-1}$.\n",
"1. We have the adjacency matrix \n",
"$\n",
" \\begin{bmatrix}\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 1 & 5 & 3 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
"$\n",
" We shall swap the 2nd row with the 0th row, giving\n",
" $\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" \\end{bmatrix}\n",
" $\n",
"2. Since the value of $(0, 0)$ entry is 1, we don't need to multiply the 0th row by any scalar. Moreover, we do not need to add multiples of this row to the other rows because the value of the entry in the 0th column of the other rows are all 0s.\n",
"3. Moving on to $i = 1$, we see that we need to swap the last row with the $1$st row, giving \n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 3 & 2 & 1 & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"4. Since the value of the $(1, 1)$ entry is 3, we need to divide the 1st row by $3$, giving\n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 5 & 3 & 0 & 0 & 1\\\\\n",
" 0 & 1 & \\frac{2}{3} & \\frac{1}{3} & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"5. Given that the value of the $(0, 1)$ entry is 5, not 0, we need to add $-5 \\times \\mathbf{a_1}$, where $\\mathbf{a_1}$ represents the 1st row in the current adjacency matrix, to the 0th row. This leaves us with\n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 0 & -\\frac{1}{3} & -\\frac{5}{3} & 0 & 1\\\\\n",
" 0 & 1 & \\frac{2}{3} & \\frac{1}{3} & 0 & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"6. Now, $i = 2$. Observe that there are no other rows that can be swapped with the last row, since in this case substituting $i = 2$, we have $2 \\leq k \\leq 2 \\implies k = 2$. Moreover, we don't need to multiply the 2nd row by a scalar since the value in its last column is 1.\n",
"7. To get 0s in the last column of the other rows, we need to add $\\frac{1}{3} \\times \\mathbf{a_2}$ and $-\\frac{2}{3} \\times \\mathbf{a_2}$, where $\\mathbf{a_2}$ represents the last row in the adjacency matrix shown in step 6, to the 0th and 1st row, respectively. The result is \n",
"$\n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0 & -\\frac{5}{3} & \\frac{1}{3} & 1\\\\\n",
" 0 & 1 & 0 & \\frac{1}{3} & -\\frac{2}{3} & 0\\\\\n",
" 0 & 0 & 1 & 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"$\n",
"8. Finally, we can get $Z^{-1}$ by taking the last 3 columns.\n",
"\\begin{equation}\n",
" Z^{-1} = \n",
" \\begin{bmatrix}\n",
" -\\frac{5}{3} & \\frac{1}{3} & 1\\\\\n",
" \\frac{1}{3} & -\\frac{2}{3} & 0\\\\\n",
" 0 & 1 & 0\\\\\n",
" \\end{bmatrix}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Implement the function `invert_matrix` that takes in a matrix $A$ and returns the inverse matrix. If $A$ is not invertible, `invert_matrix` should return `False`.\n",
"\n",
"*IMPORTANT NOTE:* **Do not use NumPy for this question**"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {
"id": "m1XBH6qwrytj"
},
"outputs": [],
"source": [
"def invert_matrix(A):\n",
" \"\"\"\n",
" Returns the inverse of matrix A, if it exists; otherwise, returns False\n",
" \"\"\"\n",
" if len(A[0]) != len(A):\n",
" return False\n",
" A_len = len(A)\n",
" result = copy.deepcopy(A)\n",
" # Step 0\n",
" for i in range(A_len):\n",
" result[i].extend([0] * A_len)\n",
" result[i][i + A_len] = 1\n",
" result = [[float(i) for i in row] for row in result]\n",
" # Step 1\n",
" for i in range(A_len):\n",
" # Step 1\n",
" for k in range(i, A_len):\n",
" if result[k][i] != 0:\n",
" break\n",
" if result[k][i] == 0:\n",
" return False\n",
" result[i], result[k] = result[k], result[i]\n",
" # Step 2\n",
" scalar = 1 / result[i][i]\n",
" result[i] = [scalar * x for x in result[i]]\n",
" # Step 3: Add multiples of the new ith row to all other rows such that the value in their ith column becomes 0\n",
" for k in range(A_len):\n",
" if k == i:\n",
" continue\n",
" scalar = -result[k][i]\n",
" result[k] = [result[k][j] + scalar * result[i][j] for j in range(2 * A_len)]\n",
" \n",
" for i in range(A_len):\n",
" result[i] = result[i][A_len:]\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": 39,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 1.5\n",
"A = [[1, 0 ,0], [0, 1, 0], [0, -4, 1]]\n",
"A_copy = copy.deepcopy(A)\n",
"\n",
"actual = invert_matrix(A)\n",
"expected = [[1, 0 ,0], [0, 1, 0], [0, 4, 1]]\n",
"assert(A == A_copy)\n",
"for i in range(len(A)):\n",
" for j in range(len(A[0])):\n",
" assert(round(actual[i][j], 11) == round(expected[i][j], 11))\n",
" \n",
" \n",
"A2 = [[0, 3, 2], [0, 0, 1], [1, 5, 3]]\n",
"A2_copy = copy.deepcopy(A2)\n",
"\n",
"actual2 = invert_matrix(A2)\n",
"expected2 = [[-5/3, 1/3 ,1], [1/3, -2/3, 0], [0, 1, 0]]\n",
"assert(A2 == A2_copy)\n",
"for i in range(len(A2)):\n",
" for j in range(len(A2[0])):\n",
" assert(round(actual2[i][j], 11) == round(expected2[i][j], 11))\n",
" \n",
" \n",
"A3 = [[1, 0, 0], [0, 1, 0], [0, 0, 0]] # non-invertible matrix\n",
"actual3 = invert_matrix(A3)\n",
"expected3 = False\n",
"assert actual3 == expected3"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "J4pQSFqk5pi6"
},
"source": [
"# Part 2: Introduction to NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "v7NPTROk6Dp9"
},
"source": [
"Now that we have a better grasp of Python, let us take a look at NumPy, a commonly used package for multidimensional array manipulation! This will come in handy when we work with certain machine learning models later in the semester. Besides, in machine learning problems, large amount of data is usually present, necessitating approaches that make manipulating them easy and fast; and one such approach is to represent our data as multidimensional arrays before manipulating them.\n",
"\n",
"The tasks in this section are designed to give us the opportunity to apply what we are about to learn about NumPy to analyse [COVID-19 data](https://github.com/OxCGRT/covid-policy-tracker)."
]
},
{
"cell_type": "code",
"execution_count": 40,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Invert array without NumPy takes 0.24375009536743164s\n",
"Invert array with NumPy takes 0.0015101432800292969s\n"
]
}
],
"source": [
"import random\n",
"import time\n",
"\n",
"import numpy as np\n",
"\n",
"random.seed(2109)\n",
"A = [[random.random() for j in range(100)] for i in range(100)] # 100 x 100\n",
"start = time.time()\n",
"_ = invert_matrix(A)\n",
"end = time.time()\n",
"print(f'Invert array without NumPy takes {end - start}s')\n",
"\n",
"A_numpy = np.array(A)\n",
"start = time.time()\n",
"_ = np.linalg.inv(A)\n",
"end = time.time()\n",
"print(f'Invert array with NumPy takes {end - start}s')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note that **each task is independent**. In other words, even if you are stuck at a particular question, it is still possible to get full marks for the later questions.\n",
"\n",
"**IMPORTANT**: It is critical that we realise that the underlying implementation of the operations available in NumPy are often optimised for performance. As a result, using these operations, as opposed to iterative approaches, to manipulate elements in the array will often lead to more performant code. This, coupled with the fact that we want to practise using NumPy in this part of the homework, means that **your implementation in the following tasks should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops**. Instead, please work with the operations available in NumPy. \n",
"\n",
"You are allowed to use any [mathematical functions](https://numpy.org/doc/stable/reference/routines.math.html), but this **does not mean that you are allowed to use any NumPy functions** (there are NumPy functions that aren't mathematical functions). For example,[ np.vectorize ](https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html) is not allowed since it is iterative. Please refer to the forum post \"List of allowed numpy functions for assignments\" under \"Homework\" for a (non-exhaustive) list of functions that are considered non-iterative for PS0 and for the CS2109S course. If you are in doubt about an unlisted function, please ask in the forum. **Solutions that violate this will be heavily penalised**."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "z0uLebHS7W6u"
},
"source": [
"## NumPy Basics"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "yVL9SBwa7Y00"
},
"source": [
"### Import NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "R9eik6gP7c9r"
},
"source": [
"In order to use NumPy, we need to import it. This can be done by"
]
},
{
"cell_type": "code",
"execution_count": 41,
"metadata": {
"id": "GGPjViIWry89"
},
"outputs": [],
"source": [
"import numpy\n",
"a = numpy.arange(5) # Returns a NumPy array [0, 1, 2, 3, 4]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dA4YI8LT7kCB"
},
"source": [
"However, it is customary to use the shorthand np instead. Therefore, we will do"
]
},
{
"cell_type": "code",
"execution_count": 42,
"metadata": {
"id": "V5P8ESNy7lye"
},
"outputs": [],
"source": [
"import numpy as np\n",
"a = np.arange(5) # Note that here we use `np` instead of `numpy`"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UQaoJky47t6s"
},
"source": [
"### NumPy Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "W3NDseCE7-WB"
},
"source": [
"NumPy arrays are objects in NumPy that represent multidimensional arrays. Such\n",
"arrays have the data type `numpy.ndarray`, or `np.ndarray` for short. Unlike Python lists, NumPy arrays cannot store data that are of different types.\n",
"\n",
"To create a NumPy array from a Python list, we can do"
]
},
{
"cell_type": "code",
"execution_count": 44,
"metadata": {
"id": "1unOnNqB72_3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(3,)\n",
"1 2 3\n",
"[9 2 3]\n",
"(2, 3)\n",
"1 5 3\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([1, 2, 3]) # Create 1D array vector\n",
"print(a.shape) # Prints(3, )\n",
"print(a[0], a[1], a[2]) # Prints 1, 2, 3\n",
"a[0] = 9 # Change the zeroth element to 9\n",
"print(a) # Prints[9 2 3]\n",
"\n",
"b = np.array([[1, 2, 3], [4, 5, 6]]) # Creates 2D array (matrix)\n",
"print(b.shape) # Prints(2, 3)\n",
"print(b[0, 0], b[1, 1], b[0, 2]) # Prints 1, 5, 3\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tW_eQ0CN8uvW"
},
"source": [
"Alternatively, we can also create pre-filled arrays with a specified shape with certain NumPy functions. Several examples of these are shown below."
]
},
{
"cell_type": "code",
"execution_count": 45,
"metadata": {
"id": "ZlO57Ak38pX3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Object a\n",
"[[0. 0. 0.]\n",
" [0. 0. 0.]\n",
" [0. 0. 0.]]\n",
"Object b\n",
"[1. 1.]\n",
"Object c\n",
"[[1. 1. 1.]\n",
" [1. 1. 1.]\n",
" [1. 1. 1.]]\n",
"Object d\n",
"[[False False False]\n",
" [False False False]]\n",
"Object e\n",
"[0 1 2 3 4]\n"
]
}
],
"source": [
"a = np.zeros((3, 3)) # Create 3x3 matrix with all zeros\n",
"b = np.ones(2) # Create vector of size 2 with all ones\n",
"c = np.ones((3, 3)) # Create 3x3 matrix with all ones\n",
"d = np.full((2, 3), False) # Create a constant array\n",
"e = np.arange(5) # Creates a 1D array with values [0, 5)\n",
"\n",
"print('Object a')\n",
"print(a)\n",
"print('Object b')\n",
"print(b)\n",
"print('Object c')\n",
"print(c)\n",
"print('Object d')\n",
"print(d)\n",
"print('Object e')\n",
"print(e)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oc4X5elN9oNp"
},
"source": [
"Note that we can use functions like `np.zeros` and `np.ones` to pre-allocate arrays. We can then assign values to the entries using indexing.\n",
"More information about array creation in NumPy can be found [here](https://numpy.org/doc/stable/user/basics.creation.html#arrays-creation)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "TQ-gm6-I9yxd"
},
"source": [
"### Basic Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MKuUe8Dj96Mn"
},
"source": [
"Accessing the value of an element in a NumPy array is similar to that of lists in Python. However, observe that in the following, instead of doing something like a[i][j], we have `a[i, j]`."
]
},
{
"cell_type": "code",
"execution_count": 46,
"metadata": {
"id": "aVtAsMWM-Bsi"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\n",
"6\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"print(a[0, 0]) # Prints 1\n",
"print(a[1, 2]) # Prints 6"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Eghq5yqQ-IEN"
},
"source": [
"Slicing works very similarly too! For example,"
]
},
{
"cell_type": "code",
"execution_count": 47,
"metadata": {
"id": "WH1UVm53-JRA"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[2 3]\n",
"[[2 3]\n",
" [5 6]]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3, 4], [4, 5, 6, 7]])\n",
"print(a[0, 1:3]) # Prints [2, 3]\n",
"print(a[:, 1:3]) # Prints [[2 3]\n",
" # [5 6]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YEC-5kzB96Qe"
},
"source": [
"However, do be careful of aliasing. The following illustrates an example of a side-effect that is caused by aliasing."
]
},
{
"cell_type": "code",
"execution_count": 48,
"metadata": {
"id": "b4aPSc9V9FqU"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"5\n"
]
}
],
"source": [
"b = a # Aliasing\n",
"b[0, 0] = 5\n",
"print(a[0, 0]) # Prints \"5\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "B7icHqWF-Sy3"
},
"source": [
"### Element-Wise Math Operation"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NISyJMKR-XWO"
},
"source": [
"NumPy provides several *element-wise math operations*. For example,"
]
},
{
"cell_type": "code",
"execution_count": 49,
"metadata": {
"id": "vNx9Wz_c-ROf"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 6 8]\n",
" [10 12]]\n",
"[[ 5 12]\n",
" [21 32]]\n"
]
}
],
"source": [
"x = np.array([[1,2],[3,4]])\n",
"y = np.array([[5,6],[7,8]])\n",
"\n",
"print(x + y) # Prints [[ 6 8]\n",
" # [10 12]]\n",
"\n",
"print(x * y) # Prints [[ 5 12]\n",
" # [21 32]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "81ptLkxU-a-w"
},
"source": [
"Similarly, operations for subtraction and division are also provided, and are given by `-` and `/`, respectively.\n",
"\n",
"**Note**: `*` is an element-wise multiplication of two matrices, not a matrix multiplication of\n",
"two matrices, as covered in task 1.4."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### General Math Operation"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"NumPy provides many *math operations*. We give some examples below. For a full list of what Numpy can do, please have a look at the following links:\n",
"\n",
"* [Math](https://numpy.org/doc/stable/reference/routines.math.html)\n",
"* [Statistics](https://numpy.org/doc/stable/reference/routines.statistics.html)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sum\n",
"\n",
"`numpy.sum` computes the sum of array elements over a given axis.\n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 50,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.0\n",
"2.0\n",
"6\n",
"[0 6]\n",
"[1 5]\n"
]
}
],
"source": [
"import numpy as np\n",
"\n",
"print(np.sum([])) # 0.0\n",
"print(np.sum([0.5, 1.5])) # 2.0\n",
"print(np.sum([[0, 1], [0, 5]])) # 6\n",
"print(np.sum([[0, 1], [0, 5]], axis=0)) # array([0, 6])\n",
"print(np.sum([[0, 1], [0, 5]], axis=1)) # array([1, 5])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Mean\n",
"\n",
"`numpy.mean` computes the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. \n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 51,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2.5\n",
"[2. 3.]\n",
"[1.5 3.5]\n"
]
}
],
"source": [
"a = np.array([[1, 2], [3, 4]])\n",
"print(np.mean(a)) # 2.5\n",
"print(np.mean(a, axis=0)) # array([2., 3.])\n",
"print(np.mean(a, axis=1)) # array([1.5, 3.5])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Floor & Ceil\n",
"\n",
"`numpy.floor` returns the floor of the input, element-wise. The floor of the scalar $x$ is the largest integer $i$, such that $i \\le x$. It is often denoted as $\\lfloor x \\rfloor$.\n",
"\n",
"`numpy.ceil` returns the ceiling of the input, element-wise. The ceil of the scalar x is the smallest integer i, such that i >= x. It is often denoted as $\\lceil x \\rceil$.\n",
"\n",
"The following is a sample execution of how this function works:"
]
},
{
"cell_type": "code",
"execution_count": 54,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[-2. -2. -1. 0. 1. 1. 2.]\n",
"[-1. -1. -0. 1. 2. 2. 2.]\n"
]
}
],
"source": [
"a = np.array([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0])\n",
"print(np.floor(a)) # array([-2., -2., -1., 0., 1., 1., 2.])\n",
"print(np.ceil(a)) # array([-1., -1., -0., 1., 2., 2., 2.])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F-qWcOyh-q-w"
},
"source": [
"## COVID-19 Data as NumPy Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nu8iuUGZ-trh"
},
"source": [
"Now that we understand the representation of NumPy arrays, we will try to learn how to use NumPy by working on some practical problems. In particular, we shall take a look at the COVID-19 data which will be used in the following tasks. These data are [time series data](https://en.wikipedia.org/wiki/Time_series) obtained from 1 January 2020 to 31 December 2020. \n",
"\n",
"For the convenience of notation, we shall refer to 1 January 2020 as the $1$st day and 31 December 2019 as the $0$th day. Observe that this means that the following data **do not** contain measurements on the 0th day, i.e. 31 December 2019.} In addition, in the following tasks, assume that $i, j \\geq 0$, whenever they are used as indexes.\n",
"\n",
"First, let us describe the data set that we will be working with. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uLwkuhfF3PiC"
},
"source": [
"### **`cases_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HUbvGwPK3UPD"
},
"source": [
"It is a 2D `np.ndarray` with each row representing the data of a country while the columns of each row represent the time series data of the cumulative number of confirmed cases in that country, i.e. the $i$-th row of `cases_cumulative` contains the data of the $i$-th country, and the $(i, j)$ entry of `cases_cumulative` is the *cumulative number* of confirmed cases on the $(j + 1)$th day in the $i$th country.\n",
"\n",
"For example, suppose"
]
},
{
"cell_type": "code",
"execution_count": 53,
"metadata": {
"id": "3gbHqkGa-fkB"
},
"outputs": [],
"source": [
"cases_cumulative = np.array([[0, 1, 2, 3], [0, 20, 21, 35]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kGeE-oed3ofk"
},
"source": [
"This means that the 0th country has recorded 0, 1, 2 and 3 cases on the 1st, 2nd, 3rd and 4th day, respectively. Similarly, the 1st country has recorded 0, 20, 21 and 35 cases on the 1st, 2nd, 3rd and 4th day.\n",
"\n",
"**Important**:\n",
"\n",
"Observe that ${(i, j)}$ entry corresponds to the data for the ${i}$-th country but ${(j + 1)}$-th day. For day 0, assume that the number of cases recorded is 0 for all countries.\n",
"\n",
"Here, *cumulative number* means that the recorded data is the total number of cases detected since day 0, not only the new cases that have been detected on a particular day. Hence, generally, `cases_cumulative[i, j]` $\\leq$ `cases_cumulative[i, j + 1]`.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "K-bF65CK3tBV"
},
"source": [
"### **`cases_top_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oV4X8qcY4N8u"
},
"source": [
"This variable is similar to `cases_cumulative`. However, it only contains data for the three countries that recorded the most number of confirmed COVID-19 cases in 2020. These data might come in handy during debugging and testing.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XPBq32dV4SpE"
},
"source": [
"### **`deaths_cumulative`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hATkVnyx4ViC"
},
"source": [
"`deaths_cumulative` is similar to `cases_cumulative`, but instead of recording the cumulative number of confirmed cases, it records the cumulative number of deaths caused by COVID-19.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hdnlmCc04kzp"
},
"source": [
"### **`healthcare_spending`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SjvPjJ9i4k28"
},
"source": [
"This is a 2D `np.ndarray` with each row representing the data of a country while the columns of each row represent the time series data of the emergency healthcare spending made by that country, i.e. the $i$-th row of `healthcare_spending` contains the data of the $i$-th country, and the $(i, j)$ entry of `healthcare_spending` is the amount which the $i$-th country spent on healthcare on the $(j + 1)$-th day. Assume that the healthcare spending on the 0-th day is \\$0 for all countries.\n",
"\n",
"For example, suppose"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "L5Dg8kPE3rid"
},
"outputs": [],
"source": [
"healthcare_spending = np.array([[0, 100, 0, 200], [0, 0, 0, 1000]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "AIKQ6qCb46hu"
},
"source": [
"Then, the 0th country only made an emergency expenditure on healthcare on the 2nd and 4th days that amounted to \\$100 and \\$200, respectively; similarly, the 1st country only made an emergency expenditure on the 4th day which amounted to \\$1000.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "mtbqt7uC5Bv3"
},
"source": [
"### **`mask_prices`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ce-xxi_t5Dlo"
},
"source": [
"`mask_prices` is a 1D `np.ndarray` such that the $j$-th entry represents the global average cost of 100 masks on the $(j + 1)$-th day.\n",
"\n",
"For example, if"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4x0dxMTJ4-X8"
},
"outputs": [],
"source": [
"mask_prices = np.array([4, 5, 20, 18])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WCnTULNz5R8y"
},
"source": [
"then the global average cost of 100 masks on the 1st, 2nd, 3rd and 4th day is \\$4, \\$5, \\$20 and \\$18, respectively.\n",
"\n",
"**Note**: The prices are not real but the overall fluctuations are chosen to simulate those observed in 2020."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n70RPHKx5fne"
},
"source": [
"### **`stringency_values`**"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_4yj4Ts55hsE"
},
"source": [
"This variable is a 3D `np.ndarray` with each row representing the data of a country, and the columns of each row representing the time series data of the stringency values as a vector. To be specific, on each day, there are four different stringency indicators: 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls'. \n",
"\n",
"For instance, suppose"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "JY_K3jkh5Yo_"
},
"outputs": [],
"source": [
"stringency_values = np.array([[[0, 0, 0, 0], [1, 0, 0, 0]],\\\n",
" [[0, 0, 0, 0], [0, 1, 2, 0]]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8Beq-_7r5hxI"
},
"source": [
"This means that for the 0th country, on the 1st day, the stringency values for 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls' were all 0. On the 2nd day, all the stringency values remained the same, except for 'school closing', which rose to 1.\n",
"\n",
"As for the 1st country, on the 1st day, the stringency values were the same as the 0th country's. However, on the 2nd day, the stringency values for 'workplace closing' and 'stay at home requirements' rose to 1 and 2, respectively.\n",
"\n",
"In this context, the higher the stringency value, the more restrictive the policy is."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Get the data from CSV"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As shown in the last few lines of `ps0.py`, we can get the data for these variables by doing the following"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from prepare_data import * # loads the `get_...` helper funtions\n",
"\n",
"df = get_data()\n",
"cases_cumulative = get_n_cases_cumulative(df)\n",
"deaths_cumulative = get_n_deaths_cumulative(df)\n",
"healthcare_spending = get_healthcare_spending(df)\n",
"mask_prices = get_mask_prices(healthcare_spending.shape[1])\n",
"stringency_values = get_stringency_values(df)\n",
"cases_top_cumulative = get_n_cases_top_cumulative(df)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iUOLLiiK52kC"
},
"source": [
"In the upcoming tasks, we will be manipulating these data, and finding answers to certain questions that we might have about issues that are related to COVID-19.\n",
"\n",
"**IMPORTANT**: You are allowed to use any of the [mathematical functions](https://numpy.org/doc/stable/reference/routines.math.html) from NumPy in all of the following tasks.\n",
"For your convenience, you may use some of the non-mathematical functions provided by NumPy, but not all of them. For example, [`np.vectorize`](https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html) isn't allowed since it is iterative. If in doubt, do ask in the forum :) With this said, do note that it is absolutely possible to complete these tasks without the non-mathematical functions that are not introduced in this document.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XtMITSIQ6wXR"
},
"source": [
"## Task 2.1: Computing Death Rates"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9BTFV_PG6yvu"
},
"source": [
"Our first task in this part of the homework is to implement `compute_death_rate_first_n_days`, which takes in three arguments, `n`, `cases_cumulative` and `deaths_cumulative`, and **computes the average number of deaths recorded for every confirmed case that has been recorded from the first day to the nth day (inclusive)**. This should be done for each country.\n",
"\n",
"The return value should be a `np.ndarray` such that the entry in the $i$-th row corresponds to the death rate in the $i$-th country as represented in `cases_cumulative` and `deaths_cumulative`.\n",
"\n",
"For instance, if the returned value is `np.array([0.5, 0.2])`, it means that in the 0th country, for every 2 individuals who contracted the virus, one of them will, on average, die. In contrast, in the 1st country, for every 5 individuals who contracted the virus, only one of them will, on average, die.\n",
"\n",
"**Note**:\n",
"You may assume that the $i$-th row in `cases_cumulative` represents the same country as the $i$-th row in `deaths_cumulative`. Moreover, if there are no confirmed cases for a particular country, its average death rate should be zero. If the data includes less than `n` days of data, then you just return the result for all the days given in the data provided. \n",
"\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to deal with `nan` values using `np.nan_to_num`, which has the following signature: `numpy.nan_to_num(x, copy=True, nan=0.0, posinf=None, neginf=None)`. You should also check out the detailed description [here](https://numpy.org/doc/stable/reference/generated/numpy.nan_to_num.html) because there are many functions of the same nature. Essentially, we can use `np.nan_to_num` to convert all the `nan` values in an `np.ndarray` to a specified value. Some examples of how `np.nan_to_num` can be used is shown below:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(np.nan_to_num(np.inf)) #1.7976931348623157e+308\n",
"print(np.nan_to_num(-np.inf)) #-1.7976931348623157e+308\n",
"print(np.nan_to_num(np.nan)) #0.0\n",
"x = np.array([np.inf, -np.inf, np.nan, -128, 128])\n",
"np.nan_to_num(x)\n",
"np.nan_to_num(x, nan=-9999, posinf=33333333, neginf=33333333) # Specify nan to be -9999, and both posinf and neginf to be 33333333\n",
"np.nan_to_num(y, nan=111111, posinf=222222) # Specify nan to be 111111, and both posinf and neginf to be 222222"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SOF2JEoW5xJE"
},
"outputs": [],
"source": [
"def compute_death_rate_first_n_days(n, cases_cumulative, deaths_cumulative):\n",
" '''\n",
" Computes the average number of deaths recorded for every confirmed case\n",
" that is recorded from the first day to the nth day (inclusive).\n",
" Parameters\n",
" ----------\n",
" n: int\n",
" How many days of data to return in the final array.\n",
" cases_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed cases in that country, i.e. the ith row of `cases_cumulative`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `cases_cumulative` is the cumulative number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" deaths_cumulative: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the cumulative number of\n",
" confirmed deaths (as a result of COVID-19) in that country, i.e. the ith\n",
" row of `n_deaths_cumulative` contains the data of the ith country, and\n",
" the (i, j) entry of `n_deaths_cumulative` is the cumulative number of\n",
" confirmed deaths on the (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Average number of deaths recorded for every confirmed case from the first day\n",
" to the nth day (inclusive) for each country as a 1D `ndarray` such that the\n",
" entry in the ith row corresponds to the death rate in the ith country as\n",
" represented in `cases_cumulative` and `deaths_cumulative`.\n",
" Note\n",
" ----\n",
" `cases_cumulative` and `deaths_cumulative` are such that the ith row in the \n",
" former and that in the latter contain data of the same country. In addition,\n",
" if there are no confirmed cases for a particular country, the expected death\n",
" rate for that country should be zero. (Hint: to deal with NaN look at\n",
" `np.nan_to_num`)\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test cases for Task 2.1\n",
"n_cases_cumulative = cases_cumulative[:3, :] #Using data from CSV. Make sure to run relevant cell above\n",
"n_deaths_cumulative = deaths_cumulative[:3, :]\n",
"expected = np.array([0.0337837838, 0.0562347188, 0.1410564226])\n",
"np.testing.assert_allclose(compute_death_rate_first_n_days(100, n_cases_cumulative, n_deaths_cumulative), expected)\n",
"\n",
"sample_cumulative = np.array([[1,2,3,4,8,8,10,10,10,10], [1,2,3,4,8,8,10,10,10,10]])\n",
"sample_death = np.array([[0,0,0,1,2,2,2,2,5,5], [0,0,0,1,2,2,2,2,5,5]])\n",
"\n",
"expected2 = np.array([0.5, 0.5])\n",
"assert(np.all(compute_death_rate_first_n_days(10, sample_cumulative, sample_death) == expected2))\n",
"\n",
"sample_cumulative2 = np.array([[1,2,3,4,8,8,10,10,10,10]])\n",
"sample_death2 = np.array([[0,0,0,1,2,2,2,2,5,5]])\n",
"\n",
"expected3 = np.array([0.5])\n",
"assert(compute_death_rate_first_n_days(10, sample_cumulative2, sample_death2) == expected3)\n",
"expected4 = np.array([0.25])\n",
"assert(compute_death_rate_first_n_days(5, sample_cumulative2, sample_death2) == expected4)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uCQ7_juB7ks0"
},
"source": [
"## Task 2.2: Computing Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E7W2-0HI72VS"
},
"source": [
"Our second task requires us to implement `compute_increase_in_cases` which accepts one argument `cases_cumulative` and **computes the daily increase in confirmed cases for each country, starting from the first day**.\n",
"\n",
"This function should return the daily increase in cases for each country as a 2D `np.ndarray` such that the $(i, j)$ entry corresponds to the increase in confirmed cases in the $i$-th country on the $(j + 1)$-th day, where $j$ is non-negative.\n",
"\n",
"Recall that as we have previously mentioned, the number of cases on the 0th day can be assumed to be 0 for all countries.\n",
"\n",
"To be specific, suppose `cases_cumulative` only contains data for 4 days such that it is equal to `np.array([[1, 2, 3, 4], [1, 3, 6, 10]])`. Then, the return value of this function should be `np.array([[1, 1, 1, 1], [1, 2, 3, 4]])`. This means that from days 1 to 4, in country 0, there was one new recorded case on each day. In contrast, in country 1, there were 2, 3 and 4 new cases on days 2, 3 and 4, respectively.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to compute differences between adjacent elements in an array using `np.diff`, which has the following signature: `numpy.diff(a, n=1, axis=-1, prepend=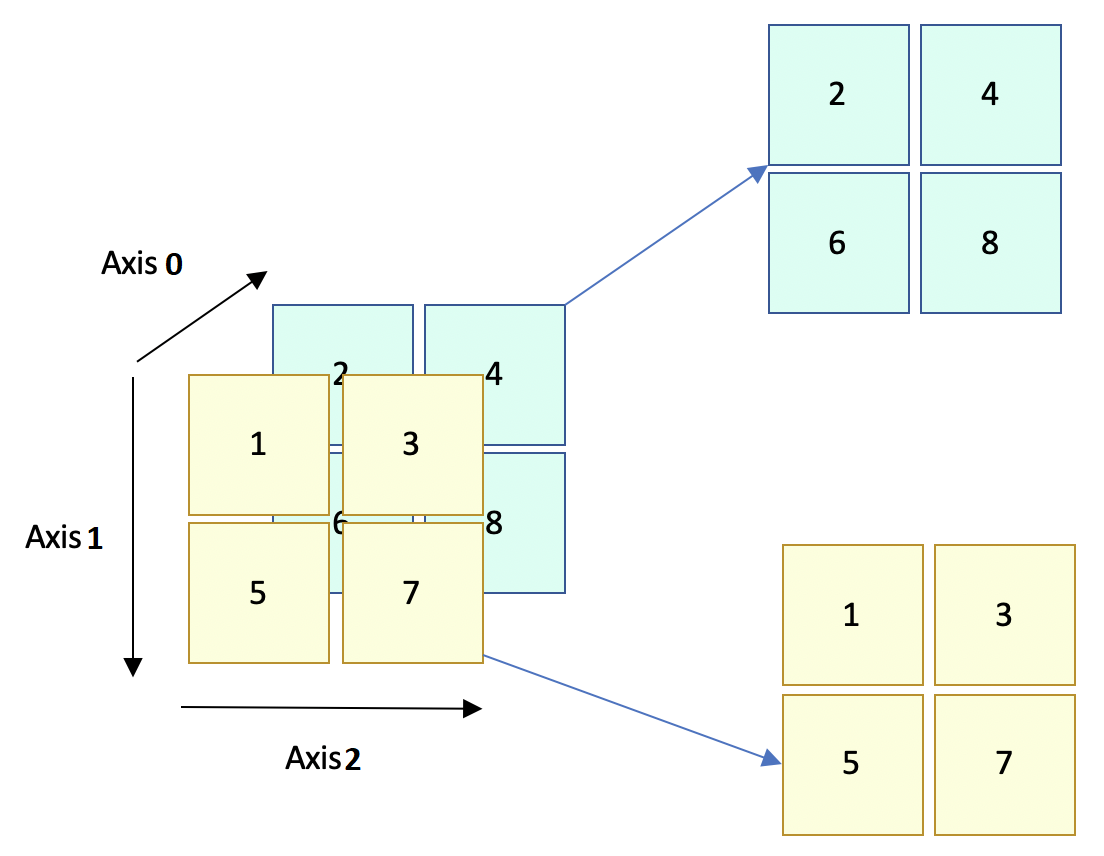 \n",
"\n",
"*Note*: NumPy arrays can have an arbitrary positive integer number of axes. If we have an N-D array with N > 3, we just need to (mentally) project it onto a smaller dimensional space so that we can have a handle of what each axis means.}\n",
"\n",
"Therefore, returning to `np.sum`, we see that"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "GtCGMCpp8QQT"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])\n",
"print(np.sum(a, axis=0)) # Prints [[ 6, 8],\n",
" # [10, 12]]\n",
"print(np.sum(a, axis=1)) # Prints [[ 4, 6],\n",
" # [12, 14]]\n",
"print(np.sum(a, axis=2)) # Prints [[ 3, 7],\n",
" # [11, 15]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "aF5DV48W9AKp"
},
"source": [
"## Task 2.3: Finding Maximum Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nKwWcvbp9CiU"
},
"source": [
"Our third task is to implement `find_max_increase_in_cases` which takes in one argument `n_cases_increase` and **finds the maximum daily increase in confirmed cases for each country**.\n",
"\n",
"In this case, `n_cases_increase` is the output obtained from calling `compute_increase_in_cases(n_cases_cumulative)`.\n",
"\n",
"The return value should be a 1D `np.ndarray` that represents the maximum daily increase in cases for each country. In particular, the $i$-th entry of this array should correspond to the increase in confirmed cases in the $i$-th country as represented in `n_cases_increase`.\n",
"\n",
"Returning to our previous example in task 2.2, suppose the daily increase in cases is given by `np.array([[1, 1, 1, 1], [1, 2, 3, 4]])`. Clearly, the maximum daily increase in cases is 1 and 4 for country 0 and 1, respectively. Therefore, we should expect the output of this function to be `np.array([1, 4])`.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to use `np.max`, or the equivalent `np.amax`, to find the max value in a column of a matrix. The following is a sample execution of how these functions work:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.arange(4).reshape((2,2)) # array([[0, 1], [2, 3]])\n",
"np.amax(a) # 3 -> Maximum of the flattened array\n",
"np.amax(a, axis=0) # array([2, 3]) -> Maxima along the first axis (first column) \n",
"np.amax(a, axis=1) # array([1, 3]) -> Maxima along the second axis (second column)\n",
"np.amax(a, where=[False, True], initial=-1, axis=0) # array([-1, 3])\n",
"b = np.arange(5, dtype=float) # array([0., 1., 2., 3., 4.])\n",
"b[2] = np.NaN # array([ 0., 1., nan, 3., 4.])\n",
"np.amax(b) # nan"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TnYgBS0m9B63"
},
"outputs": [],
"source": [
"def find_max_increase_in_cases(n_cases_increase):\n",
" '''\n",
" Finds the maximum daily increase in confirmed cases for each country.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the daily increase in the number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Maximum daily increase in cases for each country as a 1D `ndarray` such that the\n",
" ith entry corresponds to the increase in confirmed cases in the ith country as\n",
" represented in `n_cases_increase`.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.3\n",
"n_cases_increase = np.ones((100, 20))\n",
"actual = find_max_increase_in_cases(n_cases_increase)\n",
"expected = np.ones(100)\n",
"assert(np.all(actual == expected))\n",
"\n",
"sample_increase = np.array([[1,2,3,4,8,8,10,10,10,10],[1,1,3,5,8,10,15,20,25,30]])\n",
"expected2 = np.array([10, 30]) # max of [1,2,3,4,8,8,10,10,10,10] => 10, max of [1,1,3,5,8,10,15,20,25,30] => 30\n",
"assert(np.all(find_max_increase_in_cases(sample_increase) == expected2))\n",
"\n",
"sample_increase2 = np.array([\\\n",
" [51764, 84, 159, 140, 183, 0],\\\n",
" [55755, 499, 318, 574, 581, 589],\\\n",
" [97857, 392, 382, 357, 323, 299]])\n",
"expected3 = np.array([51764, 55755, 97857])\n",
"assert(np.all(find_max_increase_in_cases(sample_increase2) == expected3))\n",
"\n",
"n_cases_increase2 = compute_increase_in_cases(cases_top_cumulative.shape[1], cases_top_cumulative)\n",
"expected4 = np.array([ 68699., 97894., 258110.])\n",
"assert(np.all(find_max_increase_in_cases(n_cases_increase2) == expected4))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "e10BJ74p9eS-"
},
"source": [
"## Broadcasting"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PPuJv8kC9hJb"
},
"source": [
"*Broadcasting* makes it possible for us to apply arithmetic operations to arrays with different shapes. This is especially helpful when we have a smaller array and larger array such that we want to copy the smaller array multiple times such that its shape (i.e. the number of elements in each axis) is the same as the larger array's, before performing arithmetic operations on both arrays. Specifically, with broadcasting, we do not need to explicitly make copies of the smaller array for the arithmetic operation to work. \n",
"\n",
"For example,\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5danymoS9cqj"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"b = np.array([[0, 1, 2]])\n",
"c = np.array([[0, 1, 2], [0, 1, 2]])\n",
"d = np.full((2, 3), 5)\n",
"\n",
"print(a + b) # Prints [[1 3 5]\n",
" # [4 6 8]]\n",
" # Equivalent to a + c\n",
"print(a + 5) # Prints [[ 6, 7, 8],\n",
" # [ 9, 10, 11]]\n",
" # Equivalent to a + d"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3wZr_D4z9s3C"
},
"source": [
"The details of broadcasting can be found [here](https://numpy.org/doc/stable/user/basics.broadcasting.html).\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "EeYafm-090kt"
},
"source": [
"At times, we might need to add dimensions to one of the arrays so that broadcasting gives us our desired result. To do so, we can use `None`. \n",
"\n",
"For example, suppose we want to create a $3 \\times 2$ matrix, represented by `c`, from `a = np.array([4, 5, 6])` and `b = np.array([1, 2])` such that `c[i, j] = a[i] + b[j]`. Then, we can do the following"
]
},
{
"cell_type": "code",
"execution_count": 55,
"metadata": {
"id": "nbe68bm--FuQ"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[4 5 6]\n",
"[1 2]\n",
"[[4]\n",
" [5]\n",
" [6]]\n",
"[[1 2]]\n",
"[[5 6]\n",
" [6 7]\n",
" [7 8]]\n"
]
}
],
"source": [
"a = np.array([4, 5, 6])\n",
"print(a) # Prints [4, 5, 6]\n",
"b = np.array([1, 2])\n",
"print(b) # Prints [1, 2]\n",
"c = a[:, None] \n",
"print(c) # Prints [[4]\n",
" # [5]\n",
" # [6]]\n",
"d = b[None, :]\n",
"print(d) # Prints [[1 2]]\n",
"e = c + d\n",
"print(e) # Prints [[5 6]\n",
" # [6 7]\n",
" # [7 8]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qhIjMRK1-JM-"
},
"source": [
"Alternatively, we can use `reshape` to get the same results.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fulFjQf8-Icw"
},
"outputs": [],
"source": [
"c = a.reshape((3, 1)) + b\n",
"print(c) # Prints [[5 6]\n",
" # [6 7]\n",
" # [7 8]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ts_b7Hrk-QZ3"
},
"source": [
"## Task 2.4: Computing Number of Purchaseable Masks"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6DhPv99S-Tin"
},
"source": [
"Our fourth task is to implement `compute_n_masks_purchaseable`. This function takes two arguments, namely `healthcare_spending` and `mask_prices`, and it should **compute the total number of masks that each country can purchase if she spends all her emergency healthcare spending on masks**.\n",
"\n",
"Assume that all countries bought the masks at the global average costs, and to reduce administrative hassle, they only buy masks on day $(j + 1)$ with their emergency funds on day $(j + 1)$, i.e. the masks that are bought on a particular day are not purchased with funding from the previous days.\n",
"\n",
"The return value should be the total number of masks, which each country can purchase, represented as a 1D `np.ndarray` such that the $i$-th entry corresponds to the total number of masks purchaseable by the $i$-th country as represented in `healthcare_spending`.\n",
"\n",
"For example, if we have `healthcare_spending = np.array([[0, 100, 0], [100, 0, 200]])` and `mask_prices = np.array([4, 3, 20])`. Then, we expect the return value to be `np.array([3300. 3500.])`. This is because country 0 can only buy $33 \\times 100 = 3300$ masks on day 2 with \\$100 since the masks are priced at \\$3 and are sold in batches of 100. Similarly, we find that country 1 can only buy $(25 + 10) \\times 100 = 3500$ masks. \n",
"\n",
"In this task, you may use the `np.sum` and the `np.floor` functions.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "lscWd3LX-SR7"
},
"outputs": [],
"source": [
"def compute_n_masks_purchaseable(healthcare_spending, mask_prices):\n",
" '''\n",
" Computes the total number of masks that each country can purchase if she\n",
" spends all her emergency healthcare spending on masks.\n",
" Parameters\n",
" ----------\n",
" healthcare_spending: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the emergency healthcare\n",
" spending made by that country, i.e. the ith row of `healthcare_spending`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `healthcare_spending` is the amount which the ith country spent on healthcare\n",
" on (j + 1)th day.\n",
" mask_prices: np.ndarray\n",
" 1D `ndarray` such that the jth entry represents the cost of 100 masks on the\n",
" (j + 1)th day.\n",
" \n",
" Returns\n",
" -------\n",
" Total number of masks which each country can purchase as a 1D `ndarray` such\n",
" that the ith entry corresponds to the total number of masks purchaseable by the\n",
" ith country as represented in `healthcare_spending`.\n",
" Note\n",
" ----\n",
" The masks can only be bought in batches of 100s.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.4\n",
"prices_constant = np.ones(5)\n",
"healthcare_spending_constant = np.ones((7, 5))\n",
"actual = compute_n_masks_purchaseable(healthcare_spending_constant, prices_constant)\n",
"expected = np.ones(7) * 500\n",
"assert(np.all(actual == expected))\n",
"\n",
"healthcare_spending1 = healthcare_spending[:3, :] #Using data from CSV\n",
"expected2 = [3068779300, 378333500, 6208321700]\n",
"assert(np.all(compute_n_masks_purchaseable(healthcare_spending1, mask_prices)==expected2))\n",
"\n",
"healthcare_spending2 = np.array([[0, 100, 0], [100, 0, 200]])\n",
"mask_prices2 = np.array([4, 3, 20])\n",
"expected3 = np.array([3300, 3500])\n",
"assert(np.all(compute_n_masks_purchaseable(healthcare_spending2, mask_prices2)==expected3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "h-S8a06N_GP6"
},
"source": [
"## Matrix Multiplication"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_lN2l9BV_INc"
},
"source": [
"To perform matrix multiplication on two NumPy arrays, we use the syntax `@`. In particular, if we want to multiply array `A` and `B`, we will do `A @ B`. For example,\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.array([[1,1],[1,2]]) # array([[1, 1], [1, 2]])\n",
"b = np.array([[1],[1]]) # array([[1], [1]])\n",
"c = a @ b\n",
"print(c) # Prints [[2]\n",
" # [3]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The specifics of this operations is as follow:\n",
"\n",
"- if A and B are both 2D, they are multiplied like conventional matrices.\n",
"- if one of them is N-D, with N > 2, that matrix is treated as a stack of matrices. Broadcasting will be done where necessary.\n",
"\n",
"More details can be found [here](https://numpy.org/doc/stable/user/basics.broadcasting.html)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZMRfyy8s_gCg"
},
"source": [
"## Task 2.5: Computing Stringency Index"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DdY664xo_hhn"
},
"source": [
"Our fifth last task for this homework is to implement `compute_stringency_index`. This function takes `stringency_values` as argument, and **computes the daily stringency index for each country**.\n",
"\n",
"This function returns the daily stringency index for each country as a 2D `np.ndarray` such that the $(i, j)$ entry corresponds to the stringency index in the $i$-th country on the $(j + 1)$-th day. In this case, the higher the stringency index, the more restrictive the measures are.\n",
"\n",
"Recall that on each day, each country has four stringency values for ’school closing’, ’workplace closing’, ’stay at home requirements’ and ’international travel controls’. In this case, we shall assume that 'stay at home requirements' is the most restrictive regulation among the other regulations; 'international travel controls' is more restrictive than 'school closing' and 'workplace closing'; and 'school closing' and 'workplace closing' are equally restrictive. Thus, to compute the stringency index, we shall weigh each stringency value by 1, 1, 3 and 2 for 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls', respectively. Then, **the stringency index for the $i$th country on the $(j + 1)$th day is given by**:\n",
"\n",
"`stringency_values[i, j, 0] + stringency_values[i, j, 1] + 3 * stringency_values[i, j, 2] + 2 * stringency_values[i, j, 3]`\n",
"\n",
"**Note**: Use the matrix multiplication operator (`@` operator) to compute the stringency index. Please do not use iterative approaches like for-loops."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TnEqpaNo-z2v"
},
"outputs": [],
"source": [
"def compute_stringency_index(stringency_values):\n",
" '''\n",
" Computes the daily stringency index for each country.\n",
" Parameters\n",
" ----------\n",
" stringency_values: np.ndarray\n",
" 3D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the stringency values as a\n",
" vector. To be specific, on each day, there are four different stringency\n",
" values for 'school closing', 'workplace closing', 'stay at home requirements'\n",
" and 'international travel controls', respectively. For instance, the (i, j, 0)\n",
" entry represents the `school closing` stringency value for the ith country\n",
" on the (j + 1)th day.\n",
" \n",
" Returns\n",
" -------\n",
" Daily stringency index for each country as a 2D `ndarray` such that the (i, j)\n",
" entry corresponds to the stringency index in the ith country on the (j + 1)th\n",
" day.\n",
" In this case, we shall assume that 'stay at home requirements' is the most\n",
" restrictive regulation among the other regulations, 'international travel\n",
" controls' is more restrictive than 'school closing' and 'workplace closing',\n",
" and 'school closing' and 'workplace closing' are equally restrictive. Thus,\n",
" to compute the stringency index, we shall weigh each stringency value by 1,\n",
" 1, 3 and 2 for 'school closing', 'workplace closing', 'stay at home\n",
" requirements' and 'international travel controls', respectively. Then, the \n",
" index for the ith country on the (j + 1)th day is given by\n",
" `stringency_values[i, j, 0] + stringency_values[i, j, 1] +\n",
" 3 * stringency_values[i, j, 2] + 2 * stringency_values[i, j, 3]`.\n",
" Note\n",
" ----\n",
" Use matrix operations and broadcasting to complete this question. Please do\n",
" not use iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.5\n",
"stringency_values = np.ones((10, 20, 4))\n",
"stringency_values[:, 10:, :] *= 2\n",
"actual = compute_stringency_index(stringency_values)\n",
"expected = np.ones((10, 20)) * (1 + 1 + 3 + 2)\n",
"expected[:, 10:] *= 2\n",
"assert(np.all(actual == expected))\n",
"\n",
"stringency_values2 = np.array([[[0, 0, 0, 0], [1, 0, 0, 0]], [[0, 0, 0, 0], [0, 1, 2, 0]]])\n",
"actual2 = compute_stringency_index(stringency_values2)\n",
"expected2 = np.array([[0, 1], [0, 7]])\n",
"assert(np.all(actual2 == expected2))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nqtOvepLARkQ"
},
"source": [
"## More Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F5OtHQYwAU_q"
},
"source": [
"In fact, indexing in NumPy can be more sophisticated than what we have seen previously! \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZMxvRCGCAZe9"
},
"source": [
"### Integer Array Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "17ngFFwGAddt"
},
"source": [
"We can use a Python list or a NumPy array to index a NumPy array. For example,"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "te4V8yif_6JG"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"print(a[:, [0, 2]]) # Prints [[1 3]\n",
" # [4 6]]\n",
"print(a[[1, 0], [1, 2]]) # Prints [5 3]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7J5iATyJAffY"
},
"source": [
"Note that `a[[1, 0], [1, 2]]` essentially returns `a[1, 1]` and `a[0, 2]`."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PO3JUERDAp-V"
},
"source": [
"### Boolean Array Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "wofAGm5VAq84"
},
"source": [
"An array of Boolean can be used to determine which elements of a given array should be left out. For instance,"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "RPG5cp5EAlpr"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([4, 3, 1, 5, 10])\n",
"desired_indices = a > 3\n",
"print(a[desired_indices]) # Selects values in `a` that are\n",
" # greater than 3; prints [ 4 5 10]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Introduction to Matplotlib\n",
"\n",
"Matplotlib is a powerful and widely-used Python library for creating visualisations. We can use it to generate a wide variety of plots, charts, and graphs. We will make use of this library often in future problem sets.\n",
"\n",
"Below is an example of how to use Matplotlib to plot two different functions in the same graph"
]
},
{
"cell_type": "code",
"execution_count": 57,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAIhCAYAAABg21M1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8qNh9FAAAACXBIWXMAAA9hAAAPYQGoP6dpAAB0RUlEQVR4nO3dd1jV5f/H8ecBFUEBt7hXau6dWpYjNTW3mblt2NLKzOpbNmxpy9QsR1bOHGVppuVO09RS0zQry9wiaQ5wgsD5/XH/DgecgMB9xutxXZ/r3JzFm/Xhde5zD4fT6XQiIiIiIuIFAmwXICIiIiKSWgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvIbCq4iIiIh4DYVXEREREfEaCq8ikiGmTJmCw+FIOrJly0bx4sW59957OXToUNL9Vq1ahcPhYNWqVWn+HOvWrWPYsGGcPHnyktvGjRvHlClTLrl+7969OByOy96WmZo0aZLi+3GlY9iwYVlaV79+/a5Yy8KFC7O0losNHz6c+fPnX3L99fzOiIjvyWa7ABHxLZMnT+bGG2/k3Llz/PDDD4wYMYLVq1ezfft2cuXKdV3PvW7dOl555RX69etHnjx5Utw2btw4ChQoQL9+/VJcX6RIEdavX0+5cuWu63On1bhx44iJiUn6eNGiRbz++utJ3x+X4sWLZ2ldAMHBwaxcufKS65PXZcPw4cO566676NixY4rra9euzfr166lcubKdwkTEoyi8ikiGqlq1KnXr1gWgadOmJCQk8NprrzF//nx69uyZ5fUEBQXRoEGDLP+8FwetP//8E0j5/bElICDAyvckvcLCwryqXhHJXBo2ICKZyhU69u3bd9X7LViwgIYNGxISEkJoaCgtWrRg/fr1SbcPGzaMp59+GoAyZcokvdW9atUqSpcuzY4dO1i9enXS9aVLlwYuP2xg2LBhOBwOduzYQffu3QkPD6dw4cLcd999REdHp6jr5MmT3H///eTLl4/cuXNz5513snv37ut+y//DDz8kICCAI0eOJF03cuRIHA4HAwYMSLouMTGRvHnz8tRTTyVdd/z4cR599FGKFStGjhw5KFu2LEOHDiU2Njbd9bhc6S36y30f+/XrR+7cudm1axdt2rQhd+7clChRgqeeeuqSWmJjY3n11VepVKkSOXPmJH/+/DRt2pR169YB4HA4OHPmDFOnTk36GTZp0uSqNV3rdwbS9rP+4osvqF+/PuHh4YSEhFC2bFnuu+++9H8zRSRTKLyKSKbatWsXAAULFrzifWbOnEmHDh0ICwtj1qxZfPLJJ5w4cYImTZqwdu1aAB544AEee+wxAL766ivWr1/P+vXrqV27NvPmzaNs2bLUqlUr6fp58+Zds7YuXbpQoUIFvvzyS/73v/8xc+ZMnnzyyaTbExMTadeuHTNnzuTZZ59l3rx51K9fn1atWl3PtwSA5s2b43Q6WbFiRdJ1y5cvJzg4mGXLliVdt2nTJk6ePEnz5s0BOH/+PE2bNmXatGkMHjyYRYsW0atXL95++206d+6c6s8fHx+f4khISEjX13HhwgXat2/P7bffztdff819993HqFGjeOutt1J8rtatW/Paa6/Rtm1b5s2bx5QpU7j55pvZv38/AOvXryc4OJg2bdok/QzHjRt3xc+bmt+Z5K71s16/fj3dunWjbNmyzJ49m0WLFvHSSy8RHx+fru+LiGQip4hIBpg8ebITcG7YsMF54cIF56lTp5wLFy50FixY0BkaGuqMiopyOp1O5/fff+8EnN9//73T6XQ6ExISnEWLFnVWq1bNmZCQkPR8p06dchYqVMh58803J133zjvvOAHnnj17Lvn8VapUcTZu3PiS6/fs2eMEnJMnT0667uWXX3YCzrfffjvFfR999FFnzpw5nYmJiU6n0+lctGiRE3COHz8+xf1GjBjhBJwvv/xymr8/GzduTLquePHizvvuu8/pdDqdsbGxzly5cjmfffZZJ+Dct2+f0+l0Ot944w1n9uzZnadPn3Y6nU7nhAkTnIDz888/T/H8b731lhNwLl269Kp19O3b1wlcctxyyy1Op/PSn4/L5b6Prue6uJY2bdo4K1asmPTxtGnTnIBz0qRJV60tV65czr59+15y/fX8zqT2Z/3uu+86AefJkyevWqOI2KeeVxHJUA0aNCB79uyEhobStm1bIiIi+O677yhcuPBl779z504iIyPp3bs3AQHuU1Lu3Lnp0qULGzZs4OzZs5lSa/v27VN8XL16dc6fP5/0Vv7q1asBuPvuu1Pcr3v37hny+W+//XaWL18OmMloZ8+eZfDgwRQoUCCp93X58uU0bNgwabLbypUryZUrF3fddVeK53JNVEvek3slwcHBbNy4McXxySefpOtrcDgctGvXLsV11atXTzFM5LvvviNnzpwZ9hZ8en5nrvWzrlevHmB+1p9//nmKFTJExLMovIpIhpo2bRobN25ky5YtREZGsm3bNm655ZYr3v/YsWOAWRXgYkWLFiUxMZETJ05kSq358+dP8XFQUBAA586dS6otW7Zs5MuXL8X9rhTE06p58+bs37+fv//+m+XLl1OrVi0KFSpEs2bNWL58OefOnWPdunVJQwZcNUVEROBwOFI8V6FChciWLVvS9/NqAgICqFu3boqjYsWK6foaQkJCyJkzZ4rrgoKCOH/+fNLHR48epWjRoimC5vVIz+/MtX7Wt912G/Pnzyc+Pp4+ffpQvHhxqlatyqxZszKkZhHJOAqvIpKhKlWqRN26dalZs+Zlw8XFXKHi8OHDl9wWGRlJQEAAefPmzfA6UyN//vzEx8dz/PjxFNdHRUVlyPPffvvtgOldXbZsGS1atEi6fsWKFfzwww/ExsamCK/58+fn33//xel0pniuI0eOEB8fT4ECBa6rJlcQvXjC1X///Zfu5yxYsCCRkZEkJiZeV20umfU706FDB1asWEF0dDSrVq2iePHi9OjR45JJYCJil8KriFhVsWJFihUrxsyZM1MEsjNnzvDll18mzSaHS3vLkgsKCrrs9dejcePGAMyZMyfF9bNnz86Q5y9SpAiVK1fmyy+/ZPPmzUnhtUWLFhw9epT33nuPsLCwpLe0wQTb06dPX7KY/7Rp05Juvx6uVRq2bduW4voFCxak+zlbt27N+fPnr7lRRGp/hmn5nUmPoKAgGjdunDTpbMuWLel+LhHJeFrnVUSsCggI4O2336Znz560bduWhx56iNjYWN555x1OnjzJm2++mXTfatWqATBmzBj69u1L9uzZqVixIqGhoVSrVo3Zs2czZ84cypYtS86cOZPun16tWrXilltu4amnniImJoY6deqwfv36pKCYEW+D33777YwdO5bg4OCk4RVlypShTJkyLF26lPbt25Mtm/tU3adPHz788EP69u3L3r17qVatGmvXrmX48OG0adMmRS9tekRERNC8eXNGjBhB3rx5KVWqFCtWrOCrr75K93N2796dyZMn8/DDD7Nz506aNm1KYmIiP/30E5UqVeKee+4BzM931apVfPPNNxQpUoTQ0NDLDmdIy+9Mar300kscPHiQ22+/neLFi3Py5EnGjBlD9uzZk17EiIhnUM+riFjXo0cP5s+fz7Fjx+jWrRv33nsvYWFhfP/99zRq1Cjpfk2aNOG5557jm2++oVGjRtSrV4/NmzcD8Morr9C4cWP69+/PTTfddMkkovQICAjgm2++4Z577uHNN9+kQ4cOrFmzhhkzZgBcsstXerjCZqNGjVKMHXVdf3EYzZkzJ99//z09e/bknXfeoXXr1kyZMoUhQ4ZcV8BMbvr06dx+++08++yzdO3alUOHDl3X2M9s2bLx7bff8txzzzFv3jw6dOhAnz59WLt2LaVKlUq635gxYyhfvjz33HMP9erV46GHHrric6b2dya16tevT1RUFM8++ywtW7bkwQcfTNqJrEqVKun6ukUkczicFw+cEhGRq5o5cyY9e/bkxx9/5Oabb7ZdjoiIX1F4FRG5ilmzZnHo0CGqVatGQEAAGzZs4J133qFWrVpJS2mJiEjW0ZhXEZGrCA0NZfbs2bz++uucOXOGIkWK0K9fP15//XXbpYmI+CX1vIqIiIiI19CELRERERHxGgqvIiIiIuI1FF5FRERExGv4/IStxMREIiMjCQ0NvWQvcBERERGxz+l0curUKYoWLXrNDWB8PrxGRkZSokQJ22WIiIiIyDUcOHCA4sWLX/U+Ph9eQ0NDAfPNCAsLs1yNiIiIiFwsJiaGEiVKJOW2q/H58OoaKhAWFqbwKiIiIuLBUjPEUxO2RERERMRrKLyKiIiIiNdQeBURERERr+HzY15FxL84nU7i4+NJSEiwXYpcp8DAQLJly6ZlDkUkBYVXEfEZcXFxHD58mLNnz9ouRTJISEgIRYoUIUeOHLZLEREPofAqIj4hMTGRPXv2EBgYSNGiRcmRI4d67LyY0+kkLi6Oo0ePsmfPHsqXL3/NhctFxD8ovIqIT4iLiyMxMZESJUoQEhJiuxzJAMHBwWTPnp19+/YRFxdHzpw5bZckIh5AL2NFxKeod8636OcpIhfTWUFEREREvIbCq4iIiIh4DYVXERG5qnnz5pEtWzYqVKjAkSNHbJcjIn5O4VVERK7o+++/p0ePHrz88ssUKlSIVq1aERMTk+I+e/fu5f7776dMmTIEBwdTrlw5Xn75ZeLi4ixVLSK+TOFVREQua/PmzXTq1In33nuPF198kSVLlpAvXz7at2/P+fPnk+73559/kpiYyMSJE9mxYwejRo1iwoQJPP/88xarFxFfpfAqIj7L6YQzZ+wcTmfqapw2bRr58+cnNjY2xfVdunShT58+mfBdgVWrVpEjRw7WrFmTdN3IkSMpUKAAhw8fBmDnzp20bduW999/n0ceeQSAXLlysWjRIsLCwujWrRvx8fEAtGrVismTJ9OyZUvKli1L+/btGTJkCF999VWm1C8i/s1qeB0xYgT16tUjNDSUQoUK0bFjR3bu3JniPv369cPhcKQ4GjRoYKliEfEmZ89C7tx2jtRu8tW1a1cSEhJYsGBB0nX//fcfCxcu5N57773i46pUqULu3LmveFSpUuWKj23SpAmDBg2id+/eREdH8+uvvzJ06FAmTZpEkSJFAKhYsSKHDx++JEAHBQWxYMECvv76a7Jlu/JS4dHR0eTLly913wQRkTSwuknB6tWrGTBgAPXq1SM+Pp6hQ4fSsmVLfv/9d3LlypV0P9erehdtEygiviI4OJgePXowefJkunbtCsBnn31G8eLFadKkyRUf9+2333LhwoUr3p49e/arft7XX3+d5cuX8+CDD7Jjxw569+5Np06d0vU1XOyff/5h7NixjBw5MkOeT0QkOavhdfHixSk+njx5MoUKFWLz5s3cdtttSdcHBQURERGR1eWlyz//wLx5MHgwaG1tEbtCQuD0aXufO7X69+9PvXr1OHToEMWKFWPy5MlJ7zpdSalSpa6rvhw5cjBjxgyqV69OqVKlGD169HU9n0tkZCStWrWia9euPPDAAxnynCKStZxOGDMGWrWCG2+0Xc2lPGp72OjoaIBL3mpatWoVhQoVIk+ePDRu3Jg33niDQoUKXfY5YmNjU4wdu3hWbGaKjYXatSEmBho0gEaNsuxTi8hlOByQ7E0cj1WrVi1q1KjBtGnTuOOOO9i+fTvffPPNVR9TpUoV9u3bd8XbS5UqxY4dO676HOvWrQPg+PHjHD9+PMU7XukRGRlJ06ZNadiwIR999NF1PZeI2LNtGzz5JPzvf3D0KISG2q4oJY8Jr06nk8GDB9OoUSOqVq2adH3r1q3p2rUrpUqVYs+ePbz44os0a9aMzZs3ExQUdMnzjBgxgldeeSUrS08SFASdOsHUqfDZZwqvIpJ6DzzwAKNGjeLQoUM0b96cEiVKXPX+1zts4J9//uHJJ59k0qRJfP755/Tp04cVK1akezvWQ4cO0bRpU+rUqcPkyZO1rauIF5s501y2bet5wRXA4XSmdk5s5howYACLFi1i7dq1FC9e/Ir3O3z4MKVKlWL27Nl07tz5ktsv1/NaokQJoqOjCQsLy5Tak1u2DFq2hHz54PBh0PBckaxx/vx59uzZQ5kyZciZM6ftctIsJiaGIkWKEB8fz7Rp0+jWrVumfa6EhARuvfVWihQpwpdffklUVBTVqlXjmWee4emnn07z80VGRtK4cWNKlizJtGnTCAwMTLrteod8efvPVcTbJCZCmTKwfz/MnQtdumTN542JiSE8PDxVec0jel4fe+wxFixYwA8//HDV4ApQpEgRSpUqxd9//33Z24OCgi7bI5tVmjWDwoXh339h6VLzqkVE5FrCwsLo0qULixYtomPHjpn6ud544w327t2bNDQhIiKCjz/+mLvvvpsWLVpQs2bNND3f0qVL2bVrF7t27brkHO4h/SMikkrr1pngGhYGbdrYrubyrL6v43Q6GThwIF999RUrV66kTJky13zMsWPHOHDgQNJyLp4mMBDuuce0P/vMbi0i4l0OHz5Mz549M/0F+EsvvURkZCT58+dPuq5Dhw7ExsamObiCWdLQ6XRe9hAR7+IaMtC5MwQH263lSqyG1wEDBjBjxgxmzpxJaGgoUVFRREVFce7cOQBOnz7NkCFDWL9+PXv37mXVqlW0a9eOAgUKZNiSLpmhZ09z+fXXcOqU3VpExPMdP36c2bNns3LlSgYMGGC7HBHxUxcuwOefm3b37nZruRqrwwbGjx8PcMlahq5lYgIDA9m+fTvTpk3j5MmTFClShKZNmzJnzhxCPXEE8f+rWxfKl4e//zYBtlcv2xWJiCerXbs2J06c4K233qJixYq2yxERP7V8ORw7BoUKmWGQnspqeL3WW0rBwcEsWbIki6rJOA4H9OgBr7xihg4ovIrI1ezdu9d2CSIiSUMGunWDq2ygZ53WMskkrqEDy5bBkSN2axERERG5mrNnzSZL4NlDBkDhNdOULw/16kFCgnv8iIiIiIgn+vprOHPGLJPVoIHtaq5O4TUTuXpfteqAiIiIeDJXVunZ0wx/9GQKr5moWzcICIANG+Cff2xXIyIiInKpo0dh8WLTdnW8eTKF10wUEQG3327as2bZrUVERETkcubMMcMc69aFG2+0Xc21KbxmsuRDB7Ret4iIiHia5EMGvIHCaybr1Aly5oQ//4QtW2xXIyJybaVLl2b06NFpftyLL77Igw8+mOr7f/DBB7Rv3z7Nn0dEMs6uXWZ4Y0CAe4dQT6fwmsnCwqBdO9N2rZ8mIuLJNm7cmKYQCvDvv/8yZswYnn/++VQ/pn///mzcuJG1a9emtUQRySCubNKihRnu6A0UXrOAqxt+1iwzpkRExJMVLFiQkJCQND3mk08+oWHDhpQuXTrVjwkKCqJHjx6MHTs2jRWKSEZwOmHGDNP2liEDoPCaJVq3hrx5ITISVq+2XY2IH3E6zcKFNo5UDnKfNm0a+fPnJzY2NsX1Xbp0oU+fPpnxXQFg2LBhlCxZkqCgIIoWLcrjjz+edNvFwwYcDgcff/wxnTp1IiQkhPLly7NgwYIUzzd79uwUQwCOHj1KREQEw4cPT7rup59+IkeOHCxdujTpuvbt2zN//nzOnTuXCV+liFzNxo1mK/uQEDPM0VsovGaBHDngrrtMW0MHRLLQ2bOQO7ed4+zZVJXYtWtXEhISUoTB//77j4ULF3Lvvfde8XFVqlQhd+7cVzyqVKlyxcfOnTuXUaNGMXHiRP7++2/mz59PtWrVrlrnK6+8wt133822bdto06YNPXv25Pjx4wCcOHGC3377jbp16ybdv2DBgnz66acMGzaMTZs2cfr0aXr16sWjjz5Ky5Ytk+5Xt25dLly4wM8//3zN75WIZCzXRK0OHcxpy1t48M61vqVnT5g0CebOhQ8+MJO4RESCg4Pp0aMHkydPpmvXrgB89tlnFC9enCZNmlzxcd9++y0XLly44u3Zs2e/4m379+8nIiKC5s2bkz17dkqWLMlNN9101Tr79etH9//fM3L48OGMHTuWn3/+mVatWrFv3z6cTidFixZN8Zg2bdrQv39/evbsSb169ciZMydvvvlmivvkypWLPHnysHfvXho3bnzVGkQk48THw+zZpt2rl91a0krhNYvceiuUKAEHDsC330LnzrYrEvEDISFw+rS9z51K/fv3p169ehw6dIhixYoxefJk+vXrh+Mq29yUKlUq3aV17dqV0aNHU7ZsWVq1akWbNm1o164d2bJd+V9C9erVk9q5cuUiNDSUI0eOACS95Z/zMq/K3333XapWrcrnn3/Opk2bLnuf4OBgzqayp1pEMsby5XDkCBQsaCZreRMNG8giAQHw/50WGjogklUcDsiVy86Rhv0Va9WqRY0aNZg2bRq//PIL27dvp1+/fld9zPUMGyhRogQ7d+7kww8/JDg4mEcffZTbbrstTT25DoeDxMREAAoUKACY4QMX2717N5GRkSQmJrJv377LPvfx48cpWLDgVb9eEclYrola3brBVd6o8Ujqec1CPXrA22/DwoUQHQ3h4bYrEhFP8cADDzBq1CgOHTpE8+bNKVGixFXvfz3DBsD0drZv35727dszYMAAbrzxRrZv307t2rXTXHu5cuUICwvj999/p0KFCknXx8XF0bNnT7p168aNN97I/fffz/bt2ylcuHDSff755x/Onz9PrVq10vx5RSR9Tp+GefNM29uGDIDCa5aqXh2qVIEdO+DLL+G++2xXJCKeomfPngwZMoRJkyYxbdq0a97/eoYNTJkyhYSEBOrXr09ISAjTp08nODg43c8ZEBBA8+bNWbt2LR07dky6fujQoURHR/P++++TO3duvvvuO+6//34WLlyYdJ81a9ZQtmxZypUrl+6vR0TS5uuvzZzSG26Aawx390gaNpCFHI6U28WKiLiEhYXRpUsXcufOnSIAZoY8efIwadIkbrnlFqpXr86KFSv45ptvyJ8/f7qf88EHH2T27NlJQwlWrVrF6NGjmT59OmFhYQQEBDB9+nTWrl3L+PHjkx43a9Ys+vfvf91fk4ikXvK1XdMwwsljOJzOVC5G6KViYmIIDw8nOjqasLAw2+Wwbx+ULm1+WfbtM5O4ROT6nT9/nj179lCmTJnLTgryBi1atKBSpUq8//77tktJM6fTSYMGDRg0aFDSqgTX8ttvv3H77bfz119/EX6FcVS+8HMV8ST//gtFi0JiIvz1F5Qvb7siIy15TT2vWaxUKWjSxKxfrt5XEQEzYWn27NmsXLmSAQMG2C4nXRwOBx999BHx8fGpfkxkZCTTpk27YnAVkYw3Z44JrvXre05wTSuNebWgd29YtQqmT4dnn/XOLnsRyTi1a9fmxIkTvPXWW1SsWNF2OelWo0YNatSoker7J9+sQESyhjduB3sxhVcL7roLBgyA33+HX36BOnVsVyQiNu3du9d2CSLiB/76y2wJGxholsjyVho2YEFYGLjmY6RiUrGIiIjIdXMNV2zZEgoVslvL9VB4taRPH3M5axZcZalGEUkjH5+D6nf08xTJGE6ne8iAN67tmpzCqyUtWkDhwnD0KCxZYrsaEe/nWpRf24z6FtfP81qbLojI1f30E+zebTYA7NDBdjXXR2NeLcmWzey4NWqUmbjVtq3tikS8W2BgIHny5OHIkSMAhISE4NBsSK/ldDo5e/YsR44cIU+ePAQGBtouScSrTZ9uLjt1MgHWm2mdV4u2bIHatSEoCKKiIE8e2xWJeDen00lUVBQnT560XYpkkDx58hAREaEXIiLXITYWihSBEydg6VLz7q+nSUteU8+rRTVrQtWq8NtvMHcuPPCA7YpEvJvD4aBIkSIUKlSICxpM7vWyZ8+uHleRDLBokQmuxYpBs2a2q7l+Cq8WORxmzddnnzWrDii8imSMwMBAhR4Rkf83daq57NXLLJPl7TRhyzLXvsJr1sCePbarEREREV9y9Ch8+61pu1Y68nYKr5YVKwa3327ariUsRERERDLCrFkQHw9160LlyraryRgKrx7A9Upo2jSzDpuIiIhIRnBthtS3r906MpLCqwfo1AlCQmDXLrMOm4iIiMj12rEDNm+G7NnhnntsV5NxFF49QO7c0KWLaWu7WBEREckIrkxx551QoIDdWjKSwquH6N3bXM6ZY9ZjExEREUmvhAT3XBpfmajlovDqIZo1g6JF4fhx96xAERERkfRYvhwiIyFfPtPz6ksUXj1EYKBZNgvcW7iJiIiIpIdryED37pAjh91aMprCqwdxdesvXAjHjtmtRURERLxTTAzMm2favrTKgIvCqwepWtVsGXvhAnz+ue1qRERExBvNnQvnzsGNN5r1XX2NwquHSb7mq4iIiEhaubaD7dvX7OLpaxRePUz37hAQABs2wF9/2a5GREREvMmePfDDDya09uplu5rMofDqYSIioFUr03a9chIRERFJDdek79tvh+LF7daSWRRePVC/fuZy6lSzTpuIiIjItTid7mGHvra2a3IKrx6ofXvImxcOHYIVK2xXIyIiIt5g3Tr45x+zc2fnzraryTwKrx4oKAh69DDtyZPt1iIiIiLewdXretddkCuX3Voyk8Krh7r3XnM5bx6cOGG3FhEREfFs586ZLebBt4cMgMKrx6pd26z7Ghvr/mUUERERuZwFCyA6GkqWhMaNbVeTuRRePZTD4e591dABERERuRrXkIHevc2Sm77Mx78879arF2TLBj//DL//brsaERER8USHD8OSJabt60MGQOHVoxUqBG3amPaUKVZLEREREQ81bZpZWvPmm6FCBdvVZD6FVw/nGjowfTrEx9utRURERDyL0+keXnjffXZrySoKrx6uTRsoUACiotxvCYiIiIgArF8PO3dCSAjcfbftarKGwquHy5HDvTexJm6JiIhIcp9+ai67doXQULu1ZBWFVy/gGjqwYAEcO2a3FhEREfEMZ864l9P0lyEDoPDqFapXh1q14MIFmDnTdjUiIiLiCebOhdOn4YYb4NZbbVeTdRRevYSr91WrDoiIiAi4hwz062fWh/cXCq9eont3yJ4dfvkFtm2zXY2IiIjYtGsX/PCDCa19+9quJmspvHqJAgWgfXvT1sQtERER/+Z6J7ZlSyhe3GopWU7h1Yu4hg7MmAFxcXZrERERETsSEmDqVNP2p4laLgqvXuSOOyAiAv77D7791nY1IiIiYsPy5XDwIOTLBx062K4m6ym8epFs2aB3b9PWxC0RERH/5Jqo1aMHBAXZrcUGhVcv06+fuVy0CI4csVqKiIiIZLHjx2H+fNP2xyEDoPDqdSpXhptugvh4M/ZVRERE/MfMmWbeS40aZg14f6Tw6oVcE7c+/RScTru1iIiISNZxDRnw115XUHj1SvfcA8HBsGMH/PST7WpEREQkK2zdClu2QI4c0LOn7WrsUXj1QnnyQNeupv3JJ1ZLERERkSziWue9fXvIn99uLTYpvHqpBx4wl7NmwalTdmsRERGRzBUb657r4s9DBkDh1Ws1agQVKsCZM/D557arERERkcz0zTdmpYFixcyuWv5M4dVLORxw//2m/fHHdmsRERGRzOWaqNWnDwQG2q3FNoVXL9anj9m4YMMG+O0329WIiIhIZjh0CJYsMW3XikP+TOHVi0VEQLt2pq2JWyIiIr5p6lRITDRDBsuXt12NfVbD64gRI6hXrx6hoaEUKlSIjh07snPnzhT3cTqdDBs2jKJFixIcHEyTJk3YsWOHpYo9j2vi1rRpZjC3iIiI+I7ERPfwQNdwQX9nNbyuXr2aAQMGsGHDBpYtW0Z8fDwtW7bkzJkzSfd5++23ee+99/jggw/YuHEjERERtGjRglOaYg/AHXeYwdvHj8PXX9uuRkRERDLSypWwZw+EhbmXyfR3VsPr4sWL6devH1WqVKFGjRpMnjyZ/fv3s3nzZsD0uo4ePZqhQ4fSuXNnqlatytSpUzl79iwzZ8687HPGxsYSExOT4vBlgYHuJTM0cUtERMS3uP639+wJuXLZrcVTeNSY1+joaADy5csHwJ49e4iKiqJlsjUhgoKCaNy4MevWrbvsc4wYMYLw8PCko0SJEplfuGWuwdvLlplXZyIiIuL9/vsP5s0z7f797dbiSTwmvDqdTgYPHkyjRo2oWrUqAFFRUQAULlw4xX0LFy6cdNvFnnvuOaKjo5OOAwcOZG7hHqBMGWje3LRdu2+IiIiId5s+HeLioHZtqFXLdjWew2PC68CBA9m2bRuzZs265DaHw5HiY6fTecl1LkFBQYSFhaU4/IFr4tann0JCgt1aRERE5Po4nTBpkmmr1zUljwivjz32GAsWLOD777+nePHiSddHREQAXNLLeuTIkUt6Y/1dx46QL1/KteBERETEO61bB3/8ASEh0KOH7Wo8i9Xw6nQ6GThwIF999RUrV66kTJkyKW4vU6YMERERLFu2LOm6uLg4Vq9ezc0335zV5Xq0oCCzaQFozVcRERFv55qodffdZqUBcbMaXgcMGMCMGTOYOXMmoaGhREVFERUVxblz5wAzXGDQoEEMHz6cefPm8dtvv9GvXz9CQkLooZchl3Ct/7ZgAfz7r91aREREJH2io2HOHNPWkIFLWQ2v48ePJzo6miZNmlCkSJGkY47rJwY888wzDBo0iEcffZS6dety6NAhli5dSmhoqMXKPVPVqtCgAcTHm00LRERExPvMnAnnzkHlytCwoe1qPI/D6XQ6bReRmWJiYggPDyc6OtovJm99/LF5lVahAvz5J1xhXpuIiIh4qDp14JdfYNQoGDTIdjVZIy15zSMmbEnG6dbNLGL811+wdq3takRERCQtfvnFHDlyQK9etqvxTAqvPiY0FO65x7S145aIiIh3cS2P1bkzFChgtxZPpfDqg1xrvn7xBZw8abUUERERSaUzZ8x4V9BEratRePVB9etDlSpmsPeMGbarERERkdT44guIiYFy5aBJE9vVeC6FVx/kcMBDD5n2xIlmlw4RERHxbK4hA/ffDwFKaFekb42P6t0bgoPht99g/Xrb1YiIiMjV/P672VUrMBD69bNdjWdTePVRefKYlQfA9L6KiIiI53L1urZtC0WK2K3F0ym8+jDX0IHPP4cTJ+zWIiIiIpd37hxMnWrarv/dcmUKrz6sfn2oXh3On9eOWyIiIp7qiy9MJ1Pp0tCype1qPJ/Cqw/TxC0RERHP5xre17+/GfMqV6fw6uN69oSQEPjjD+24JSIi4mm2bTMTtbJlg/vus12Nd1B49XHh4e4dtzRxS0RExLO4/jd37AgREVZL8RoKr37ANXRg7lw4dsxuLSIiImKcPg3Tp5v2ww/brcWbKLz6gXr1oGZNiI11z2YUERERu2bPhlOnoHx5aNrUdjXeQ+HVDySfuPXRR5q4JSIi4glcQwYefFA7aqWFvlV+okcPyJULdu6E1attVyMiIuLfNm0yR44c2lErrRRe/URYmAmwoIlbIiIitrn+F991FxQoYLcWb6Pw6kdcQwe+/BKOHrVbi4iIiL+KjoZZs0xbE7XSTuHVj9SpY44LF2DKFNvViIiI+KfPPoMzZ6BSJWjUyHY13kfh1c8kn7iVmGi3FhEREX/jdMKECab98MNmUrWkjcKrn+neHUJDYdcuWLnSdjUiIiL+ZcMG2L4dgoOhd2/b1XgnhVc/kzu3+49l/Hi7tYiIiPgbV69rt26QN6/dWryVwqsfeuQRc/n113DwoN1aRERE/MXx4/D556atiVrpp/Dqh6pWhdtug4QEmDTJdjUiIiL+Ydo0OH8eatSAm26yXY33Unj1UwMGmMuPPjKrD4iIiEjmSUyEceNMWxO1ro/Cq5/q2BEiIiAqCubPt12NiIiIb1uxAv7+20ya7tXLdjXeTeHVT+XIAf37m7brlaCIiIhkjg8/NJd9+5rJ05J+Cq9+7MEHITAQVq2C33+3XY2IiIhv2r8fvvnGtB991G4tvkDh1Y8VLw7t25u2ls0SERHJHBMnmjGvzZqZXbXk+ii8+jnXK8CpU+H0abu1iIiI+JrYWPfKPq7J0nJ9FF79XLNmUKECnDoFM2bYrkZERMS3zJ0LR49CsWLudzvl+ii8+rmAAPemBePGmT2XRUREJGO4JkU/9BBky2a3Fl+h8Cr07Wv2WN6+HX780XY1IiIivmHrVli3zoRW1wo/cv0UXoW8eaFHD9PWslkiIiIZw7U8VpcuZm11yRgKrwK4J27NnQv//mu3FhEREW938iR89plpa6JWxlJ4FQBq14b69c1WsZ98YrsaERER7zZlCpw7B9WqQaNGtqvxLQqvksTV+zphAiQk2K1FRETEWyUmuofhPfooOBx26/E1Cq+S5O67IX9+OHAAFi60XY2IiIh3Wr4c/v4bwsKgVy/b1fgehVdJkjMnPPCAaY8da7cWERERb+Xqde3bF3LntluLL1J4lRQeecSs/bpiBezYYbsaERER77J/P3zzjWm7huNJxlJ4lRRKlYIOHUz7gw/s1iIiIuJtJkwwY16bNYMbb7RdjW9SeJVLPP64uZw2zSz1ISIiItd27hx89JFpa3mszKPwKpdo3BiqVoWzZ+HTT21XIyIi4h1mz4Zjx8y7mO3b267Gdym8yiUcDnfv64cfatksERGRa3E64f33TXvAALMlrGQOhVe5rJ49zbaxu3fDd9/ZrkZERMSzrV0LW7dCcDDcf7/tanybwqtcVkiI+4/P9UpSRERELs/1v7J3b8iXz24tvk7hVa5owACzbNayZfDnn7arERER8Uz798O8eab92GN2a/EHCq9yRaVLQ7t2pq1ls0RERC5v/HgzP6RZMzPhWTKXwqtclesV5JQpEB1ttRQRERGPk3x5LPW6Zg2FV7mqZs2gcmU4c8YEWBEREXGbOROOHzfLY7nerZTMpfAqV+VwuF9JfvCB2TVEREREUi6PNXAgBAbarcdfKLzKNfXqBeHhsGsXLF5suxoRERHP8MMPsG1byhV6JPMpvMo15c7t/qMcO9ZuLSIiIp4i+fJYefParcWfKLxKqgwYYIYQLF4Mf/1luxoRERG79u2D+fNNWxO1spbCq6RK2bLQtq1pa9MCERHxd+PGmXkgt98OVarYrsa/KLxKqg0aZC4nT4YTJ6yWIiIiYs3ZszBpkmk//rjdWvyRwqukWtOmUL16yj9aERERf/PZZ6YTp0wZuPNO29X4H4VXSTWHw937OnYsXLhgtRwREZEs53TCmDGmPWCAlseyQeFV0qR7dyhUCA4ehK++sl2NiIhI1lq2DHbsMCvxPPCA7Wr8k8KrpEnOnPDoo6Y9apTdWkRERLLae++Zy/vvN2ugS9ZTeJU0e+QRyJEDfvoJ1q+3XY2IiEjW2LEDliwxw+g0UcsehVdJs0KFoGdP01bvq4iI+IvRo81lp05mCUmxQ+FV0uXJJ83ll1+ahZpFRER82dGjMH26aQ8ebLcWf6fwKulSrZpZmDkxET74wHY1IiIimWv8eIiNhXr14OabbVfj3xReJd1cva+TJsHp03ZrERERySznz8OHH5r24MFmzKvYo/Aq6da6NVSoANHRZtctERERXzRrFhw5AsWLQ5cutqsRhVdJt4AAeOIJ0x4zBhIS7NYjIiKS0ZxO9+Tkxx+H7Nnt1iMKr3Kd+vaFvHnhn39g4ULb1YiIiGSsFStg+3bIlQv697ddjYDCq1ynXLngwQdN27WEiIiIiK9w9bredx/kyWO1FPl/VsPrDz/8QLt27ShatCgOh4P58+enuL1fv344HI4UR4MGDewUK1c0cKDZ23nVKtiyxXY1IiIiGeOPP+Dbb80ELdcwObHPang9c+YMNWrU4IOrrLXUqlUrDh8+nHR8++23WVihpEbx4tC1q2mPHGm3FhERkYwyZoy57NABypWzW4u4ZbP5yVu3bk3r1q2vep+goCAiIiKyqCJJryFDYPZsc4wYASVK2K5IREQk/f77D6ZONW3X0pDiGTx+zOuqVasoVKgQFSpUoH///hw5cuSq94+NjSUmJibFIZmvTh1o2tSsOOB6pSoiIuKtJkww67vWqQO33mq7GknOo8Nr69at+eyzz1i5ciUjR45k48aNNGvWjNjY2Cs+ZsSIEYSHhycdJdQFmGWGDDGXH31k1n4VERHxRufPu3ePfPJJbUrgaRxOp9NpuwgAh8PBvHnz6Nix4xXvc/jwYUqVKsXs2bPp3LnzZe8TGxubItzGxMRQokQJoqOjCQsLy+iyJRmnE6pWhd9/h7ffhqeftl2RiIhI2k2aZFbSKVHCLAWptV0zX0xMDOHh4anKax7d83qxIkWKUKpUKf7+++8r3icoKIiwsLAUh2QNh8Pd+zpmDMTF2a1HREQkrRIT3ZOPn3xSwdUTeVV4PXbsGAcOHKBIkSK2S5Er6NEDihSBQ4fM5C0RERFv8s03sHMnhIfDAw/YrkYux2p4PX36NFu3bmXr1q0A7Nmzh61bt7J//35Onz7NkCFDWL9+PXv37mXVqlW0a9eOAgUK0KlTJ5tly1UEBZnt8wDefdcMJRAREfEW77xjLh95BEJD7dYil2d1zOuqVato2rTpJdf37duX8ePH07FjR7Zs2cLJkycpUqQITZs25bXXXkvTJKy0jKGQjHHypBkndPo0LF4Md9xhuyIREZFrW7cObrkFcuSAvXvNO4mSNdKS16yu89qkSROulp2XLFmShdVIRsmTx7zVMnq0eQWr8CoiIt7A1evaq5eCqyfzqjGv4j0GDTJbxq5YoS1jRUTE8/31F3z9tWm7Jh+LZ1J4lUxRqhTcfbdpv/uu3VpERESuZeRIM0+jXTuoVMl2NXI1Cq+SaVyvXOfMgf377dYiIiJyJf/+694KVmuUez6FV8k0tWtDs2Zmy9jRo21XIyIicnljx0JsLNSvD40a2a5GrkXhVTKV6xXspElmFQIRERFPcvo0jBtn2s88o61gvYHCq2SqO+4wW8aePg0TJtiuRkREJKVPP4UTJ+CGG6BDB9vVSGoovEqmcjjcva+jR8O5c1bLERERSRIfD++9Z9pPPWVWyRHPp/Aqma57dyhZMuWAeBEREdu++AL27YOCBaFvX9vVSGopvEqmy57dvfLAO++YV7oiIiI2OZ3uTQkGDoTgYLv1SOopvEqWuP9+KFAAdu82r3RFRERsWrLEbKKTKxcMGGC7GkkLhVfJEiEh8MQTpv3mm+YVr4iIiC0jRpjLBx+E/Pnt1iJpo/AqWWbAAMidG7Ztg8WLbVcjIiL+6scf4YcfzLC2wYNtVyNppfAqWSZvXnjoIdN2veIVERHJaq7/QX36QPHidmuRtFN4lSw1eDDkyAFr1phXviIiIllp2zZYtAgCAuDZZ21XI+mh8CpZqmhR80oXzNhXERGRrOT633PXXVC+vN1aJH0UXiXLPf202bxg4ULYvt12NSIi4i/++QfmzDHt//3Pbi2SfgqvkuUqVDCveAHefttuLSIi4j/eeQcSE6FVK6hVy3Y1kl4Kr2KF6xXvrFmwZ4/dWkRExPdFRsLkyab9/PN2a5Hro/AqVtSuDS1bQkICjBxpuxoREfF1o0ZBXBzccgvceqvtauR6KLyKNa7e108+gSNH7NYiIiK+68QJmDDBtJ97zm4tcv0UXsWaJk3gppvg/HkYPdp2NSIi4qs++ABOn4bq1aFNG9vVyPVSeBVrHA73uKMPPjCvjEVERDLSmTMwZoxpP/ec+d8j3k3hVaxq1w6qVYNTp+D9921XIyIivubjj+HYMShXzr3SjXg3hVexKiAAXnjBtEePhpgYq+WIiIgPiY2Fd9817WeegWzZ7NYjGSNDwuvJkycz4mnET3XpAjfeCCdPwrhxtqsRERFfMWUKHDwIxYpB3762q5GMkubw+tZbbzHHtT0FcPfdd5M/f36KFSvGr7/+mqHFiX8IDHSPfR050oxPEhERuR4XLsCIEab9zDMQFGS3Hsk4aQ6vEydOpESJEgAsW7aMZcuW8d1339G6dWuefvrpDC9Q/EP37lC2LPz3H0ycaLsaERHxdtOnw759ULgw9O9vuxrJSGkOr4cPH04KrwsXLuTuu++mZcuWPPPMM2zcuDHDCxT/kC2be+29d94xy2eJiIikR3w8vPGGaT/9NAQH261HMlaaw2vevHk5cOAAAIsXL6Z58+YAOJ1OEhISMrY68St9+kDJkhAVZTYuEBERSY9Zs2D3bihQAB5+2HY1ktHSHF47d+5Mjx49aNGiBceOHaN169YAbN26lRtuuCHDCxT/kSMHPPusab/1ltnGT0REJC0SEuD11037qacgVy679UjGS3N4HTVqFAMHDqRy5cosW7aM3LlzA2Y4waOPPprhBYp/ue8+KFIEDhyAadNsVyMiIt7miy/gr78gXz4YMMB2NZIZHE6n02m7iMwUExNDeHg40dHRhIWF2S5HUmHUKBg82Ezg2rlT6/KJiEjqJCaaLWB37IBXX4UXX7RdkaRWWvJaqsLrggULaN26NdmzZ2fBggVXvW/79u3TVm0mU3j1PmfOQJkycPQoTJ1qxsKKiIhcy5dfml20wsNh717Ik8d2RZJaGR5eAwICiIqKolChQgQEXHmkgcPh8LhJWwqv3unNN83qAxUrmlfQgYG2KxIREU/mdEKtWvDrr6bH9dVXbVckaZGWvJaqMa+JiYkUKlQoqX2lw9OCq3ivRx+FvHnNsIG5c21XIyIinu6bb0xwzZ0bBg2yXY1kpgzZHtbl7NmzGfl04sfCwuCJJ0z71VfN7FEREZHLcTrdPa0DB5rJWuK70hxemzRpwsGDBy+5/qeffqJmzZoZUZMIYMJreDj8/ruZPSoiInI5ixfD5s0QEmIm/IpvS3N4DQsLo3r16syePRswwwiGDRvGbbfd5nGTtcS75clj1ugDeOUV9b6KiMilkve6PvIIFCxotx7JfOlaKmvChAkMGTKE9u3bs3fvXvbv38+UKVOSdtvyJJqw5d1iYqB0aThxAj77DHr0sF2RiIh4ksWLoXVryJkT9uyBiAjbFUl6ZPiErYs9/PDDPPbYY8yePZtNmzbx+eefe2RwFe8XFubufdXYVxERSc7phJdeMu0BAxRc/UWaw+uJEyfo0qUL48ePZ+LEidx99920bNmScePGZUZ9Ijz2mBl8v3On2a9aREQEYNEi2LjRjHV95hnb1UhWSXN4rVq1Kv/++y9btmyhf//+zJgxg08++YQXX3yRO++8MzNqFD8XFgZDhpj2q69CfLzdekRExL7kva6PPQb/v6Kn+IE0h9eHH36YH374gTJlyiRd161bN3799Vfi4uIytDgRl4EDIX9++PtvmDnTdjUiImLb11/Dli1mXVdXB4f4h3RN2PImmrDlO956C/73PyhXDv78E7Jls12RiIjYkJhodtPatg2GDoXXX7ddkVyvDN8e9nLOnj3L/v37L+ltrV69enqeLtMovPqO06ehbFk4ehQ+/RTuvdd2RSIiYsPcudC1qxlWtmePNiXwBWnJa2nuuzp69Cj33nsv33333WVv1xaxklly5zYD8p9+Gl57DXr1guzZbVclIiJZKSEBXn7ZtJ98UsHVH6V5zOugQYM4ceIEGzZsIDg4mMWLFzN16lTKly/PggULMqNGkSSPPGIG5e/ZA9Om2a5GRESy2hdfmJ0X8+SBQYNsVyM2pDm8rly5klGjRlGvXj0CAgIoVaoUvXr14u2332bEiBGZUaNIkly54NlnTfv110FzBEVE/EdCAgwbZtpDhpgAK/4nzeH1zJkzFPr/9Sjy5cvH0aNHAahWrRq//PJLxlYnchkPPwyFC8PevTB1qu1qREQkq8yaZdb8zpcPHn/cdjViS5rDa8WKFdm5cycANWvWZOLEiRw6dIgJEyZQpEiRDC9Q5GIhIfDcc6b92mtw/rzdekREJPPFx8Mrr5j2M89AaKjdesSedI15PXz4MAAvv/wyixcvpmTJkrz//vsMHz48wwsUuZyHHoLixeHAAZg40XY1IiKS2WbMgF27oGBBsxWs+K/rXuf17Nmz/Pnnn5QsWZICBQpkVF0ZRktl+a5Jk+DBB82JbPdusxqBiIj4nrg4uPFGM1n33XfhqadsVyQZLS15Lc09r8n9+OOPBAYGUrt2bY8MruLb+vWDG24w676OGWO7GhERySwff2yCa0SEWXVG/Nt1hdfWrVtz6NChjKpFJE2yZ4dXXzXtd96B48ft1iMiIhnvzBkzvwHgxRfNvAfxb9cVXn18Z1nxAt26QbVqEB1tAqyIiPiWsWMhKgrKlIEHHrBdjXiC6wqvIrYFBMAbb5j2mDHmBCciIr7hxAl46y3TfvVVyJHDbj3iGdIcXvv168cPP/wAwMSJEylcuHCGFyWSFm3bQoMGcO6cO8iKiIj3e+cdOHkSqlSB7t1tVyOeIs3h9dSpU7Rs2ZLy5cuzZ88eTp48mQlliaSewwGuVdomTjSbF4iIiHeLinJPxn3jDQgMtFuPeI40h9cvv/ySQ4cOMXDgQObOnUvp0qVp3bo1c+fO5cKFC5lRo8g1NW0KzZvDhQvuRaxFRMR7vf46nD1r3llr3952NeJJrnud1y1btvDpp5/y8ccfkzt3bnr16sWjjz5K+fLlM6rG66J1Xv3Hzz9D/fpmHOxvv0GlSrYrEhGR9NizBypWNB0SK1eaDgrxbVm2zuvhw4dZunQpS5cuJTAwkDZt2rBjxw4qV67MqFGjruepRdLsppugY0dITISXXrJdjYiIpNfLL5vg2qKFgqtcKs09rxcuXGDBggVMnjyZpUuXUr16dR544AF69uxJ6P9vNDx79mweeeQRTpw4kSlFp4V6Xv3Lb79B9ergdMKmTVCnju2KREQkLZKfxzduhLp1bVckWSEteS1bWp+8SJEiJCYm0r17d37++Wdq1qx5yX3uuOMO8uTJk9anFrluVatCz55mD+znn4clS2xXJCIiafHCCya4dumi4CqXl+ae1+nTp9O1a1dy5syZWTVlKPW8+p/du80e2BcuwLJlZiKXiIh4vvXr4eabNXfBH2XqmNfevXt7TXAV/1S2rHvv62eeMWNgRUTEszmd5h0zgL59FVzlyrTDlvikF16A0FDYsgVmz7ZdjYiIXMuSJbBqldlF6+WXbVcjnkzhVXxSwYLwv/+Z9tChEBtrtx4REbmyhAR4+mnTfuwxKFXKbj3i2RRexWcNGgRFi5odt8aNs12NiIhcybRpZoxrnjzuoQMiV6LwKj4rJMS929brr5v9sUVExLOcPQsvvmjaQ4dCvnx26xHPp/AqPq1fPzPo//hxeOst29WIiMjFRo+GQ4fMUIGBA21XI97Aanj94YcfaNeuHUWLFsXhcDB//vwUtzudToYNG0bRokUJDg6mSZMm7Nixw06x4pWyZYM33zTt0aPh4EGr5YiISDJHj7rP0W+8AVrMSFLDang9c+YMNWrU4IMPPrjs7W+//TbvvfceH3zwARs3biQiIoIWLVpw6tSpLK5UvFm7dnDrrXD+vLaNFRHxJK+9BqdOQe3a0L277WrEW6R5k4LM4nA4mDdvHh07dgRMr2vRokUZNGgQzz77LACxsbEULlyYt956i4ceeihVz6tNCgRgwwZo2NAsfP3rr2YnLhERsefvv6FyZYiPhxUroFkz2xWJTZm6SUFW2bNnD1FRUbRs2TLpuqCgIBo3bsy6deuu+LjY2FhiYmJSHCINGpitBhMT3UtoiYiIPc8/b4Jr69YKrpI2Hhteo6KiAChcuHCK6wsXLpx02+WMGDGC8PDwpKNEiRKZWqd4j+HDITAQFi0yC2GLiIgdGzbA3Lnm3TBNppW08tjw6uJwOFJ87HQ6L7kuueeee47o6Oik48CBA5ldoniJChXANdrk6ae1bayIiA1OJwwZYtr9+kG1albLES/kseE1IiIC4JJe1iNHjlzSG5tcUFAQYWFhKQ4Rl5deMtvGbtoEn31muxoREf/z9dfw448QHOxei1skLTw2vJYpU4aIiAiWLVuWdF1cXByrV6/m5ptvtliZeLPChd27tzz3HJw5Y7ceERF/cuGCe97Bk09C8eJ26xHvZDW8nj59mq1bt7J161bATNLaunUr+/fvx+FwMGjQIIYPH868efP47bff6NevHyEhIfTo0cNm2eLlBg2C0qXNotjvvmu7GhER/zFxIuzcCQUKwP8vJCSSZlaXylq1ahVNmza95Pq+ffsyZcoUnE4nr7zyChMnTuTEiRPUr1+fDz/8kKppWOdIS2XJ5Xz+OXTrZraQ/esvKFbMdkUiIr7t+HEoX95cjh8PDz9suyLxJGnJax6zzmtmUXiVy3E6zcYFP/4IffvClCm2KxIR8W2DBsGYMWad7S1bzA6IIi4+sc6rSGZyOGDUKNOeOhU2b7Zbj4iIL/vzT/jwQ9N+7z0FV7k+Cq/it+rVg169TPvJJ01vrIiIZLwhQ8yGBO3aQYsWtqsRb6fwKn5txAizXMuaNfDVV7arERHxPUuWmM1hsmfXJFnJGAqv4teKFzcbFgA88wzExtqtR0TEl8THw+DBpv3YY2azGJHrpfAqfu/pp6FIEdi9G95/33Y1IiK+46OP4PffIX9+ePFF29WIr1B4Fb+XOzcMH27ar78OR47YrUdExBecOGF2NQR47TXIk8dqOeJDFF5FgD59oHZtiImBl1+2XY2IiPd77TU4dgyqVIH+/W1XI75E4VUECAhwL5310Ufw66926xER8WZ//QVjx5r2qFFaGksylsKryP+77Taz61ZioplYoKWzRETSx7U0Vtu2WhpLMp7Cq0gy775rtoxdswZmzbJdjYiI91myBL75xvS2amksyQwKryLJFC8OQ4ea9tNPw+nTdusREfEmsbHmnSswlxUr2q1HfJPCq8hFBg+GsmUhMtKsPiAiIqkzejT8/TcULgzDhtmuRnyVwqvIRXLmNCdgMHtw//WX1XJERLzCwYNmhQGAd96BsDC79YjvUngVuYy2baF1a7hwAQYN0uQtEZFrGTIEzpyBRo2gVy/b1YgvU3gVuQyHw/S+Zs8O330HCxfarkhExHN9/z3MmWOWHRw71pxDRTKLwqvIFVSo4N6Te9AgOH/eajkiIh7pwgUYONC0H3kEata0Wo74AYVXkat44QUoWhR279aSLyIil/PBB/D771CggHvMq0hmUngVuYrcuc3EA4Dhw2H/frv1iIh4kqgo95bab74JefParUf8g8KryDV07w633grnzpkJCSIiYjzzDJw6BfXqwb332q5G/IXCq8g1OBxmAkJAAHzxBSxdarsiERH71q6F6dPNOfLDD805UiQr6FdNJBVq1HDvGvPoo6YXVkTEXyUkuCdp3X+/6XkVySoKryKp9OqrZvLWP/+YsV0iIv7qww/h11/NGNcRI2xXI/5G4VUklcLCYMwY037zTe28JSL+6eBBGDrUtIcPN6sMiGQlhVeRNOjSBVq1grg4M3xAO2+JiL954gk4fRoaNoQHH7RdjfgjhVeRNHA4zJqGOXPCihUwa5btikREss7ChfDVVxAYCBMmaJKW2KFfO5E0KlfObF4A8OSTcPKk1XJERLLEmTMwYIBpDx4M1avbrUf8l8KrSDoMGQIVK8KRI+6xXyIivuyVV8xGLaVKuTcmELFB4VUkHYKCYPx40x4/Hn7+2W49IiKZads2eO890/7gA8iVy2494t8UXkXSqWlT6N3bTNp6+GGIj7ddkYhIxktMhIceMmu7du4Mbdvarkj8ncKryHV4913Ikwe2bIFx42xXIyKS8SZNgg0bIHdu93KBIjYpvIpch0KF3BsWDB0KBw7YrUdEJCP9+y/873+m/frrULy43XpEQOFV5Lr17w8332zWPXzkEa39KiK+Y/Bgs6JK7dru7WBFbFN4FblOAQHw8ceQIwcsWgSzZ9uuSETk+i1dCjNnmnPcRx+ZtV1FPIHCq0gGqFTJvfbr44/Df//ZrUdE5HqcPu3ePWvgQKhTx249IskpvIpkkGefhapVTXB98knb1YiIpN8LL8C+fWZN1zfesF2NSEoKryIZJEcO+OQT8xbbjBnw3Xe2KxIRSbv16+H99037o4/MKgMinkThVSQD3XQTPPGEaT/0EJw6ZbceEZG0iI2F++83E0/79oWWLW1XJHIphVeRDPbaa1CmjFk26/nnbVcjIpJ6b7wBf/xhlgF07agl4mkUXkUyWK5c5q02gA8/hHXr7NYjIpIa27bBiBGm/eGHkC+f3XpErkThVSQTNG8O/fqZt94eeMC8FSci4qni481wgfh46NQJunSxXZHIlSm8imSSkSOhcGHzFpxm64qIJxszBjZtgvBw+OADcDhsVyRyZQqvIpkkXz4YO9a0R4yArVutliMicll//QUvvmjaI0dC0aJ26xG5FoVXkUx0113QubN5K65vX4iLs12RiIhbQoIZ4nTunBnudN99tisSuTaFV5FM5HDA+PFQoICZDPH667YrEhFxGzXKrOsaGmrWqdZwAfEGCq8imaxQIRg3zrSHD4fNm+3WIyICZjy+a1vrUaOgZEm79YiklsKrSBbo2hXuvtu8Rde3r1YfEBG74uPNcIHYWGjdWsMFxLsovIpkkQ8/NL2wO3bAK6/YrkZE/Nm778LPP5vVBSZN0nAB8S4KryJZpEABmDDBtN96y/zjEBHJar/9Bi+/bNrvvw/FitmtRyStFF5FslCnTtCzJyQmmuED58/brkhE/MmFC+6VT9q1g969bVckknYKryJZ7P33oUgR+PNP92QJEZGsMGIE/PIL5M0LEydquIB4J4VXkSyWL58ZYwbw3nuwapXVckTET/z8M7z6qml/8IF5ES3ijRReRSy4807o3x+cTujTB06etF2RiPiyM2egVy+z4sk990D37rYrEkk/hVcRS957D264AQ4cgIEDbVcjIr5syBD4+28oXtysO63hAuLNFF5FLMmdG6ZPh8BA+OwzmD3bdkUi4osWLXKvdDJlihnvKuLNFF5FLGrQAIYONe1HHjG9sCIiGeXIEfcGBE8+CbffbrcekYyg8Cpi2QsvQL16Ztxrv35mGS0RkevldJqx9UeOQNWqZntqEV+g8CpiWfbsMGMGhITAypUwZoztikTEF3zyCSxYADlymHNMzpy2KxLJGAqvIh6gQgUzgQvguedg2za79YiId9u1CwYNMu3XX4caNayWI5KhFF5FPMSDD0LbthAba5ayOXvWdkUi4o3i4sw55MwZaNIEBg+2XZFIxlJ4FfEQDgd8+ilERMAff5jJFSIiafX887B5s9kQxbWiiYgvUXgV8SAFC5qxaQ4HfPQRfPGF7YpExJt89x2MHGnan35q1nUV8TUKryIe5vbb4X//M+3+/WHfPrv1iIh3iIqCvn1Ne+BA6NDBbj0imUXhVcQDvfKKWQM2Ohp69ID4eNsViYgnS0yE3r3h6FGoXh3eecd2RSKZR+FVxANlzw4zZ0JYGKxbZ8KsiMiVvPsuLF8OwcFmtz4tiyW+TOFVxEOVKWPGvQK88QZ8/73dekTEM/30k3unvvffh0qV7NYjktkUXkU8WLducP/9Zqecnj3NTjkiIi4nTkD37mZo0d13m/OFiK9TeBXxcGPGQOXKcPiwGf+akGC7IhHxBE4n3Hsv7NkDpUvDxIlmpRIRX6fwKuLhcuUyS2aFhMCKFfDqq7YrEhFP8N578PXXZvvXuXMhTx7bFYlkDYVXES9QubLpVQF47TVYutRuPSJi148/wrPPmvbo0VCnjtVyRLKUwquIl+jVy2wh6xr/evCg7YpExIajR814+IQEsw3sww/brkgka3l0eB02bBgOhyPFERERYbssEWvGjIFateC//8w/rwsXbFckIlkpIcG8kD10CCpWNCuSaJyr+BuPDq8AVapU4fDhw0nH9u3bbZckYk3OnGb8a3i4Wf/1uedsVyQiWemNN8ywoeBgM841NNR2RSJZz+PDa7Zs2YiIiEg6ChYsaLskEavKlYPJk0175EiYN89uPSKSNZYvh2HDTHv8eKha1Wo5ItZ4fHj9+++/KVq0KGXKlOGee+5h9+7dV71/bGwsMTExKQ4RX9OpEzz5pGn37Qt//mm3HhHJXHv3mvGtTqdZy7VvX9sVidjj0eG1fv36TJs2jSVLljBp0iSioqK4+eabOXbs2BUfM2LECMLDw5OOEiVKZGHFIlnnrbfgttvg1Cno2BH0Ok3EN507B507w7FjULcufPCB7YpE7HI4nU6n7SJS68yZM5QrV45nnnmGwYMHX/Y+sbGxxMbGJn0cExNDiRIliI6OJiwsLKtKFckS//5rlsg5dMgE2C+/hACPfkkqImnhdEKfPjBjBhQoAJs3Q8mStqsSyXgxMTGEh4enKq951b+5XLlyUa1aNf7+++8r3icoKIiwsLAUh4ivKlwYvvrKLFI+fz4MH267IhHJSGPHmuAaGAiff67gKgJeFl5jY2P5448/KFKkiO1SRDzGTTfBuHGm/dJL8O23dusRkYyxejW43mR8911o2tRuPSKewqPD65AhQ1i9ejV79uzhp59+4q677iImJoa+GqkuksL995uFyp1O6NEDdu2yXZGIXI8DB6BrV7Oua8+e8MQTtisS8RweHV4PHjxI9+7dqVixIp07dyZHjhxs2LCBUqVK2S5NxOOMGQM33wzR0WY1gtOnbVckIulx/jx06WJ20qpZUxsRiFzMqyZspUdaBgCLeLvISDOBKyoKOnQw42E1gUvEezid0Ls3fPYZ5MsHmzZBmTK2qxLJfD47YUtErq5oUbNpQVAQfP01DB1quyIRSYsRI0xwzZbN7Kan4CpyKYVXER/ToAF88olpv/kmTJ9utx4RSZ2vvnK/4Bw7Fpo1s1uPiKdSeBXxQT17wvPPm/YDD8C6dXbrEZGr27LFDBcAeOwxMwFTRC5P4VXER732mpm4FRdnLvfts12RiFxOVBS0bw9nz0LLlvDee7YrEvFsCq8iPiogAKZNgxo14MgR889RKxCIeJbz583ueAcPQsWKMGeOGe8qIlem8Criw3LnhgULzE5c27aZNWATEmxXJSJgVha47z746SfImxe++Qby5LFdlYjnU3gV8XElS5qtY4OCzD/HQYPMP00RseuFF2DWLNPTOnculC9vuyIR76DwKuIHGjRwrzrwwQcwapTdekT83UcfwfDh7rZWFhBJPYVXET/RtavZHx3gqafMGpIikvW+/RYefdS0X34Z7r3Xbj0i3kbhVcSPDB4MAweadu/e8OOPdusR8Te//AJ3323Gnvfta8KriKSNwquIH3E4YPRos/JAbKy5/Osv21WJ+Id9++DOO+HMGWje3AwXcDhsVyXifRReRfxMYKCZJHLTTXD8OLRubZbSEpHMc+IEtGlj1nStVs1M0MqRw3ZVIt5J4VXED4WEmJUHypaF3bvNP9WYGNtVifims2fNuxy//w7Fipkxr+HhtqsS8V4KryJ+qlAh+O47KFgQNm82C6WfP2+7KhHfcuGCGeO6dq0JrN9+C8WL265KxLspvIr4sQoVTIANDYXvv4fu3SE+3nZVIr4hMdGsJLBoEQQHw8KFUL267apEvJ/Cq4ifq1PH7MIVFGQ2M3jwQW1iIHK9nE6zIchnn7k3IWjUyHZVIr5B4VVEaNIEZs+GgACYPBmefdZ2RSLe7fXXYexY054yxYwrF5GMofAqIoAZ8/rxx6b9zjvw9ttWyxHxWuPGwUsvmfaYMdCzp916RHyNwquIJLn3XvcuXM8+a/4Ji0jqTZvm3gjkpZfg8cft1iPiixReRSSFp56C55837QED3L2xInJ1s2ebF4BOp/nbGTbMdkUivknhVUQu8frr8OSTpv3gg6Y3SUSu7MsvoVcvs8LAAw/A++9r9yyRzKLwKiKXcDhg5EjTe+R0mt6kOXNsVyXimb75Bu65BxISoG9fmDjRTH4UkcyhPy8RuSyHw/QePfCA6U3q2RO++sp2VSKeZfFiuOsusz5y9+7wyScKriKZTX9iInJFAQGmF6lPH9OrdM89ppdJRGDlSujUCeLioEsXM7wmMNB2VSK+T+FVRK4qIAA+/dT0Kl24YP5Jz59vuyoRu5YsgTvvNFsqt2sHM2eazQhEJPMpvIrINQUGml6lu+82AfauuzQGVvzXwoXQvr0Jrm3bwhdfQI4ctqsS8R8KryKSKtmyma0ue/c2Qwh69IDp021XJZK1vvzSPVSgc2fzcVCQ7apE/IvCq4ikWrZsZvtY1ySuvn21Dqz4j1mzoFs39+SsOXPU4ypig8KriKRJYKCZxOVaRqt/f/jwQ9tViWSuKVPMihuu5bCmT9cYVxFbFF5FJM0CAmDsWBg82Hw8cCC89ZYJsyK+5sMP3Ttn9e9vJjBqVQERexReRSRdHA54910YOtR8/L//wZAhZjiBiC9wOuHll82LM4DHHtMGBCKeQH+CIpJuDofZSvbdd83H770H/fqZFQlEvFlCAjz6KLz6qvl42DAYM0Zbvop4AoVXEbluTz0FU6eat1KnT4eOHeHMGdtViaRPbKzZkGPCBBNWx40zPbAKriKeQeFVRDJEnz7w9dcQHAzffgstWsDx47arEkmbmBho0wbmzjUrCcyZA488YrsqEUlO4VVEMsydd8Ly5ZA3L6xfD7feCvv22a5KJHUiI6FpU7Pta+7c5kVY1662qxKRiym8ikiGuvlmWLMGihWD33+H+vXh559tVyVydb/+an5Xf/kFChaEVavg9tttVyUil6PwKiIZrkoV0/NavTr8+y80bmx2IhLxRN9+C40awcGDULGi+d2tU8d2VSJyJQqvIpIpSpSAtWvN+MHz5+Guu+Dtt7UWrHiWDz+Edu3g9GkzZGD9eihXznZVInI1Cq8ikmlCQ80krsceMx8/+6xZ5F1LaYltCQnwxBNmDdfERLjvPli82IzXFhHPpvAqIpkqWzZ4/31zBATAJ5/AHXfA0aO2KxN/dfIktG9vficBRoyAjz82qwuIiOdTeBWRLPHYY7BggZnF/f33ULeumRwjkpV27IB69cw415w54fPPze5wWsNVxHsovIpIlrnzTvjpJyhfHvbvh1tuMZsaiGSFuXPNigK7dkGpUvDjj1oKS8QbKbyKSJaqXNksndW2rZnI1aePGXuocbCSWRIS4LnnTFA9cwaaNYNNm6B2bduViUh6KLyKSJbLk8dM5HrpJfPx++9D8+YQFWW1LPFBx46ZHv833zQfP/UULFkCBQrYrUtE0k/hVUSsCAiAV16B+fPNqgQ//AA1a5odukQywtq15ndqyRKzbfHMmfDuu2YSoYh4L4VXEbGqQwczjKBqVbOhQcuW8MILEB9vuzLxVgkJ8MYb0KSJ2XigfHmzfmv37rYrE5GMoPAqItbdeKMJsA8+aDYxeOMNs2D8gQO2KxNvExUFrVqZF0AJCdCrF2zeDDVq2K5MRDKKwquIeITgYJg4EWbPNsMIXG/5LlhguzLxFsuWmZC6fDmEhMDkyTBtmvl9EhHfofAqIh6lWzfYssXsLX/8uBlW0L8/nDpluzLxVGfPwuOPmyEnR46YISibNkG/flq/VcQXKbyKiMcpVw7WrTMzwx0Os/tR9eqwerXtysTTbNgAtWrB2LHm40ceMUNQKlWyW5eIZB6FVxHxSDlymJnh338PpUvD3r1mHOzgwXDunO3qxLa4OBg61Gx08ddfUKwYLF4M48aZISgi4rsUXkXEozVuDNu2maEDTieMGmUWl//pJ9uViS1bt5otXocPh8REMylr+3a44w7blYlIVlB4FRGPFxoKH30EixZBkSLw55/QsCE89hhER9uuTrLKmTPw9NNQt655QVOgAHz5pdliOG9e29WJSFZReBURr9GmDfz2G/TubXphP/jAbDf75ZfmY/FdixaZn/W775olsO66y/wudO5suzIRyWoKryLiVfLlM8sfrVhhFp+PjDRBpn172LfPdnWS0SIjoWtXaNsW9u+HUqVg4UL44gsoXNh2dSJig8KriHilZs3MW8cvvQTZs5tAU7kyvP66JnT5gthYeOcds4HF3LkQGGiGDOzYAXfeabs6EbHJ4XT69pttMTExhIeHEx0dTVhYWNZ8UqcTTp+GkyfhxAlz6WqfOgXnz5szs+vS1b5wwWz4frkjMNCsup0r16VH7tyQP78ZAFagAAQFZc3XKeIh/vgDHn4YfvjBfFyiBLz1Ftxzj9b59DZOJ8ybZ4Lq7t3muptuMmOe07RLlus8fOwYxMRc/jh92px3L3ckJEC2bOaVUfLLbNnMUhihoe4jLMx9GRYGBQuaj/XLJ5JqaclrCq8ZrXZt0x2UkJD5n+tKcud2B9kCBcwaMiVKQPHi5tLV1rYz4kOcTpgzB555xr2tbIMGZnWCBg3s1iap88svZik013q+RYqYFQX69DGv4ZOcOWPGiOzbZ9ZQO3QI/v3XHEeOuNs2u+Bz5oRChdxH4cLmskQJM/bBdWRVp4qIh1N4TSbLw2utWmYdFzCv1PPmhTx53JehoWYRwqAg95Ezp7nMnt38B05MdF+6jvh4s43MmTOXHqdOmd6F//5LW2gODzerwZcvf+mRP796DcQrnTsHI0fCm2+aPw8wPbCvvAIVKtitTS5vzx549VWYOtWc+nLmhBcfPcag1jsJ2f8n7NwJ//zjDqv//Zf6J8+Z05zrXL2iyY9cuUwvavbsKXtYs2c373bFx6c8Llwwl7Gxptc2Jsacf0+dcrdPnjTn6tTKk8cdZMuXh4oV3UehQjoPi99QeE0my8Pr3r3mZJgnjwmpWXnicTrNukH//ec+jhyBgwfNceCA+/Ja6wvlyWMGEFatCtWquS/z58+SL0XkekVGwgsvwJQp5k8jIMD04L34IpQta7s6ATMBa8wLR/nts1+pkriNyvzOrQX+5IbEnQQev0ZADQszu1eUKmV6MwsXvvyRK1eWfC0pnDkDR4+6e4JdvcFRUeaL3r/fBPHjx6/+POHh5hXXjTeac3D16uYoUkShVnyOwmsyVsa8eoNTp8wJdNcu+PvvlMfBg1d+XJEi5iRaq5ZZbLFuXfMPRCdS8VBbtphJXQsXmo+zZTN73r/wgsk9kkUSE81WWFu2cGrtr+xf+Ct59/9KUQ5f+TElSrh7IcuXd4fV0qXNC2xv5zoP799vup//+sv0Mu/caTpCrvTvuUABE2Jr1DCXdeqYzobAwCwtXyQjKbwmo/CaDufOmVD722/m2L7dXO7Zc/n758vnDrKuo3hxBVrxKD//bELskiXm4+zZoW9fM8ayUiW7tfmkw4fNN/2nn8zlxo3mrfXLOFfsBoLrVzcvjG+80RwVKtjpNfUU58+b8/DOnWZXju3bzXyKnTvNC4GL5cplQmy9emaG2003maCv87B4CYXXZBReM9CpU/D77+YEunkzbNpk2hcuXHrfwoXNpuOuo1YtM5xCxLIff4SXXzbrxLq0bQtDhsBtt+l/fbrExppw+uOPJqj+/PNl38E5SzBbqcmv1OBMuRo0HVSDOv2qmUmmkjrnzrnPw7/+auZY/PKLOT9frEABE2Lr14dGjcylP78gEI+m8JqMwmsmi401PQKbNrmP3367dOJYcLA5ibrC7M03+8bbfuK1fvzR7Nb09dfud2fr1oWnnoIuXUzPrFzBqVOwfj2sWWPWJ/vpJ3MuSMYZEEB08Sr8GHcTX0fdxE/UZwdVaNEqG08/DU2b6oVChklMND2yrhcOP/9sgu3FHQvZspkVcW691YTZRo1MwBXxAAqvySi8WnD2rOkJWLvWJIR16y6dmOBwmPFaTZua1eZvvdVMThDJYn/9ZZbTmjLFvFML5o2D++6D/v2hTBmr5XmG//4zf8+usLply6UvUAsWhFtvJbpyA+YdvIk3FtdhV5TpUc2WDbp3N73b1atbqN8fxcaaAPvzz+YcvGbN5eczVKpkQmyTJuZcHBGR5aWKgMJrCgqvHsDVK/Djj+ZYu9aM5UouIMCM12rWzATaRo309pZkqaNHYdw4mDDBTAoH8xqrRQsTZNu1M/uE+IW4ONOzumSJOX755dL7lC5tXnTeeiux9W9jwZ8VmDLVwZIl7lxbuLB5AfDQQ2YYvFi2b5/7RcjatWa7sotVrgy3327OxU2a6B0yyTIKr8kovHqoqChYtQq+/94cf/+d8vbs2c0wg6ZNTXpo2FDv40qWuHABvvnGhNhly9zXh4aa4QQ9e5pfS5+b2L17tzusrlhh1jFNrnJlE1Zvuw1uvZWEoiVYu9ZsDDF7ttlA0KVRIxgwADp31lB3j3bsmOlQ+OEHcx7esiXlCgcBAWaYQbNmJtDecos6FSTTKLwmo/DqJQ4eNCfPlSvN5b59KW8PDTUn0JYt4Y47zOYKIpnsn3/g00/hs89S/koWKgTt20OnTuZ/ulfuyHz6tPlbcwXWi98NKVjQ/ffWsiUULkx8vOm0++IL+Oors3SpS/HiZh3dvn21GYTXOnbMbG+2YoU5F//5Z8rbs2c3r0zuuANatTJjQDRwWTKIwmsyCq9eas8ec/JcscJ0f128o065cu5/rE2baotFyVSJiWbY4IwZ8PnnKXsZQ0PN//E77jBvEpQsaa/Oq3I6zRhIV1hduzblhJ5s2cxEyjvuMEetWhAQQFQULF4M335r/hRPnnQ/JE8e6NjRh3uj/d2hQ+YFzooV5nDtu+wSEWHOw61amV9+Tf6S66DwmozCqw9ITDRvZy1dav7p/vij2aLRJVs2M6zA1UNUp85FG6GLZJy4ONM5NW8ezJ9vljNNrmJF83+8USPzLqvVsZ5Hj5rEuWSJ+ftxDeZ1KVPGnbz//0Xgv/+a3tXVq827ydu2pXxI/vzQoQN07WreDNGwAD/hdJre+SVLzKuZ779PuQ2uw2GW63C9+GnQwJybRVLJ58LruHHjeOeddzh8+DBVqlRh9OjR3Hrrral6rMKrDzp1yoyXvdLbnfnzu3sDWrbU7FnJNImJZjL34sUmG/7006Xrx5csaUJsnTpQs6ZZZCPTOqguXIANG9wB45dfUo5hzJXLhNT/DxgxhW5gy1YHmza5l26+ePg5mEzSujW0aWPWwFcPqxAbazoSFi82v28Xv8oJDzdjalwvjjz2LQnxFD4VXufMmUPv3r0ZN24ct9xyCxMnTuTjjz/m999/p2Qq/hgUXv3A7t3uXtkVKy5drLtWLXMCbdVKE78kU5086R62/eOP5l36y22GVLy4WaGofHlz3HCD6QQtWtS8FZ+mYYR79rhfyK1ceckuVglVa3C83h3sLn8HW0Ju4fd/gvjjDzOc8Uo7QVevbuZlNW5sLgsVSkM94p8iI93n4aVLL10esVIl93n4ttsgZ047dYrH8qnwWr9+fWrXrs348eOTrqtUqRIdO3ZkxIgR13y8wqufuXDBdH8tXmyOzZtT3h4aCs2buyccaHN7yUSnTplfx/Xr3Zsh/fPP1R+TM6cJsYULm84r1xEWZl535Uw4ww0HV3HD7iWU/XsJBY79leLx0dkLsCG0BcuztWL+mRbsOlPkqp+vZEnTK1ynjulhrVfP7Pgskm4JCebc6+qV3bAh5au44GCzDFfr1uY8fMMNmvglvhNe4+LiCAkJ4YsvvqBTp05J1z/xxBNs3bqV1atXX/KY2NhYYpPt9BITE0OJEiUUXv3VkSOmF8B1Er144teNN6bsDQgOtlOn+I2YGLMp3c6d5i36XbvM5f79KSeCuTmpxnbuYAl3sIRbWUMQcUm3xhPIOm7+/1vv4Bdq4yTlmO/8+aFECRNUK1Y0v/aVKpm2gqpkuhMnzLti331nzsWRkSlvL1vWfR5u2lTbBfspnwmvkZGRFCtWjB9//JGbb7456frhw4czdepUdu7cecljhg0bxiuvvHLJ9QqvQmKiGQPo6pXdsCHlLkE5c5reANdJtEIF9QZIljp3zkwAO/rnMRzLl5Hv58VEbF9K7piUs8L+Cy3NjmJ38GepO9hbthmEhxMUZN5YyJ/fBNJ8+cxqV8WLa2lO8SBOp9lC3HUeXrMm5aoXOXKY9YRd5+EqVXQe9hM+F17XrVtHw4YNk65/4403mD59On9evAYd6nmVNDh50vQGuE6iFw8ALF3afQJt1swkA5HMEB/vnmi1ZImZOZX81BwSYl5YuYa7lC+vf+jiG06fNmO1Fy82PbN796a8vVgx93m4eXPt+OXDfCa8pmfYwMU05lVSxemE3393B9kffjBrIrlky2amjLtOojVqKDxI+jmdZvDrsmVmWMtlJlpRrZp7pnajRl66E4JIGjidZgyN6zz8/fdw/rz79sBAM+nWdR7+/7WIxTf4THgFM2GrTp06jBs3Lum6ypUr06FDB03Yksxz5ox7Oa7Fiy9dPygiwt0L1qKFea9W5GpOnDAh1RVY9+xJeXv+/OZ3ybVecdGiduoU8RTnzpmOBFeYvfjd1oIF3efhli3Nx+K1fCq8upbKmjBhAg0bNuSjjz5i0qRJ7Nixg1KpmCmu8CoZ4p9/3EF25UoTbl0cDrjpJvdJtG5dLccl7jVXXWF148aUM66zZze9+S1amH+8tWppAVWRq9m7130eXr7cDDlwcTigdm2ztmyzZubdCg329io+FV7BbFLw9ttvc/jwYapWrcqoUaO47bbbUvVYhVfJcMkX51682EwdTy53bnPibNrUHLVqaacZfxAfbyYErlpljjVrUv5zBTPFv2VLE1gbN9asapH0iosza9C5VjD49deUt2fPbnb5atbMBNr69bUdnIfzufB6PRReJdMdOuRejmv58ksX5w4LM8twNWliwmyNGuph8wXx8Wbb4uRh9eINMlxDAVyB1epesSI+LDLSvCu2cqWZiLt/f8rbQ0JMp0KzZuZcXLu23iHzMAqvySi8SpZKTDQ9sd9/b47VqyE6OuV98uQxYfaWW9z7hmq3Gc93/rxZeH3dOvNzXbPm0klWefKYHtUmTcxRvbomlIhkNafT7LzoCrMrV5o1v5MLCTG9sbfeakJtgwZaUcYyhddkFF7FqoQEs62SK8xerncuRw4TYG++2Ry33GK2VxK7IiNNUF23zrw9uXlzyvUowWx9dXFYVa+6iGdxrSbj6pVds+bSd8gCAqBmTRNkGzUywbZECa0qk4UUXpNReBWPEh9vQtCaNSYU/fjjpT0CYHacuekmM/mrTh0zbjY8POvr9RfR0eZFxi+/mIlV69bBvn2X3q9QIfMCwzWmWUNARLxPYqJZuWDtWnMuXrv20vVlwXQi1KtnjptuMpdaWSbTKLwmo/AqHs319pYryK5bZ3afudyfZfny7k3o69QxY7YUaNPu+HETUl3H5s1mj9aLBQSYntSGDd294mXKqCdGxBcdPGhC7Nq15ly8fXvKHRhdypQxQbZOHXN+qF7dLJ2o88J1U3hNRuFVvM7Jk/DTT2aXpc2bzXHx5AOX4sWhalWzhaLrsnJlLREDZnjG77+7jx07zHGl72XJku4XBQ0bmn9QGgMn4p/OnTPvxmzcCD//bC7/+uvy982f3x1kq1c35+GKFbUbWBopvCaj8Co+4ehRdy/h5s0m2F4phDkcUKoU3HBDyqNcOTMcISQka2vPTKdPm57r3bvNWryu448/4MCBKz+uXDkTUmvXdg/LKFAg6+oWEe9z8qQ5//78s1maa9s22Lkz5frNyRUsaEJshQrmqFjRnHtKlTKr0EgKCq/JKLyKzzpxwvQo/vabu1fxt98uP4Y2uSJFzESEYsVMz63rsnhxs6tT/vymx8DmLHmn04xDjYoyS5FFRprD1T50yOxQ9e+/V3+eIkVMT3Tlyu5e6apVIW/erPk6RMS3nTtnXixv2+Y+/vjDnKeuJk8e825PyZImzJYsac7BhQq5jwIF7K8RHheXZevjKrwmo/AqfufoUTMZ4Z9/zFjO5MfFy3ZdSUCACXj58pkwmz+/+ThXLtNzm/wIDjaHK+y6xn45HOZwOs3GDufPmxP9uXMp2ydPmnGoJ06Yy+PHzXWXG292OXnzmt4M11G2LNx4o9kQIF++tH73RESu36lTZlvxv/4yvbOuyz17Ll3p4Gry5TNBNn9+M4wp+ZE7t7nMlcuE3GzZzATS5O2AALNKSlycuUzePn/eLPcXHe2+dLVPnoRjx0xHx86dmfZtSk7hNRmFV5H/53Sak+bu3abn8tAhM0kh+WVk5KW7QtkUFmZ6hosWNUfydunSJqiqF1VEvMmpU2ZY0/79ZlWT/fvNceiQ6Xw4cgT+++/KwxGyUv78ppYskJa8pj0rRfyFw+HuRa1X78r3i401vaDHjrkPV4/o2bOmt/Ts2ZTtc+dMOHa9Fk7eBggKMhsxBAdfepknj7uXN18+dztvXnO7iIgvCQ11D2e6koQEc851hdljx0zoPXXKdDC42qdOmXNwQoJZijE+PmU7MdG87Z89uzmSt4OCTAdBeLj7Mnm7QAGPXRpM4VVEUgoKMku/RETYrkRExD8FBpoJXwULXj3k+intWygiIiIiXkPhVURERES8hsKriIiIiHgNhVcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeBURERERr6HwKiIiIiJeQ+FVRERERLyGwquIiIiIeA2FVxERERHxGgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvEY22wVkNqfTCUBMTIzlSkRERETkclw5zZXbrsbnw+upU6cAKFGihOVKRERERORqTp06RXh4+FXv43CmJuJ6scTERCIjIwkNDcXhcNguxyfExMRQokQJDhw4QFhYmO1yJI308/N++hl6P/0MvZt+fhnP6XRy6tQpihYtSkDA1Ue1+nzPa0BAAMWLF7ddhk8KCwvTH60X08/P++ln6P30M/Ru+vllrGv1uLpowpaIiIiIeA2FVxERERHxGgqvkmZBQUG8/PLLBAUF2S5F0kE/P++nn6H308/Qu+nnZ5fPT9gSEREREd+hnlcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeJUMERsbS82aNXE4HGzdutV2OZJKe/fu5f7776dMmTIEBwdTrlw5Xn75ZeLi4myXJlcwbtw4ypQpQ86cOalTpw5r1qyxXZKk0ogRI6hXrx6hoaEUKlSIjh07snPnTttlyXUYMWIEDoeDQYMG2S7Fryi8SoZ45plnKFq0qO0yJI3+/PNPEhMTmThxIjt27GDUqFFMmDCB559/3nZpchlz5sxh0KBBDB06lC1btnDrrbfSunVr9u/fb7s0SYXVq1czYMAANmzYwLJly4iPj6dly5acOXPGdmmSDhs3buSjjz6ievXqtkvxO1oqS67bd999x+DBg/nyyy+pUqUKW7ZsoWbNmrbLknR65513GD9+PLt377Zdilykfv361K5dm/HjxyddV6lSJTp27MiIESMsVibpcfToUQoVKsTq1au57bbbbJcjaXD69Glq167NuHHjeP3116lZsyajR4+2XZbfUM+rXJd///2X/v37M336dEJCQmyXIxkgOjqafPny2S5DLhIXF8fmzZtp2bJliutbtmzJunXrLFUl1yM6OhpAf29eaMCAAdx55500b97cdil+KZvtAsR7OZ1O+vXrx8MPP0zdunXZu3ev7ZLkOv3zzz+MHTuWkSNH2i5FLvLff/+RkJBA4cKFU1xfuHBhoqKiLFUl6eV0Ohk8eDCNGjWiatWqtsuRNJg9eza//PILGzdutF2K31LPq1xi2LBhOByOqx6bNm1i7NixxMTE8Nxzz9kuWS6S2p9hcpGRkbRq1YquXbvywAMPWKpcrsXhcKT42Ol0XnKdeL6BAweybds2Zs2aZbsUSYMDBw7wxBNPMGPGDHLmzGm7HL+lMa9yif/++4///vvvqvcpXbo099xzD998802Kf5wJCQkEBgbSs2dPpk6dmtmlyhWk9mfoOvlGRkbStGlT6tevz5QpUwgI0OtaTxMXF0dISAhffPEFnTp1Srr+iSeeYOvWraxevdpidZIWjz32GPPnz+eHH36gTJkytsuRNJg/fz6dOnUiMDAw6bqEhAQcDgcBAQHExsamuE0yh8KrpNv+/fuJiYlJ+jgyMpI77riDuXPnUr9+fYoXL26xOkmtQ4cO0bRpU+rUqcOMGTN04vVg9evXp06dOowbNy7pusqVK9OhQwdN2PICTqeTxx57jHnz5rFq1SrKly9vuyRJo1OnTrFv374U1917773ceOONPPvssxoCkkU05lXSrWTJkik+zp07NwDlypVTcPUSkZGRNGnShJIlS/Luu+9y9OjRpNsiIiIsViaXM3jwYHr37k3dunVp2LAhH330Efv37+fhhx+2XZqkwoABA5g5cyZff/01oaGhSWOVw8PDCQ4OtlydpEZoaOglATVXrlzkz59fwTULKbyK+LGlS5eya9cudu3adckLDr0p43m6devGsWPHePXVVzl8+DBVq1bl22+/pVSpUrZLk1RwLXHWpEmTFNdPnjyZfv36ZX1BIl5KwwZERERExGtoVoaIiIiIeA2FVxERERHxGgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvIbCq4iID2vSpAmDBg2yXYaISIbRDlsiIj7s+PHjZM+endDQUNuliIhkCIVXEREREfEaGjYgIpIFjh49SkREBMOHD0+67qeffiJHjhwsXbr0so/ZuHEjLVq0oECBAoSHh9O4cWN++eWXpNtXrVpFjhw5WLNmTdJ1I0eOpECBAhw+fBi4dNjAuHHjKF++PDlz5qRw4cLcddddGfyViohkLoVXEZEsULBgQT799FOGDRvGpk2bOH36NL169eLRRx+lZcuWl33MqVOn6Nu3L2vWrGHDhg2UL1+eNm3acOrUKcAdTHv37k10dDS//vorQ4cOZdKkSRQpUuSS59u0aROPP/44r776Kjt37mTx4sXcdtttmfp1i4hkNA0bEBHJQgMGDGD58uXUq1ePX3/9lY0bN5IzZ85UPTYhIYG8efMyc+ZM2rZtC0BcXBwNGjSgfPny7Nixg4YNGzJp0qSkxzRp0oSaNWsyevRovvrqK+69914OHjyoMbAi4rXU8yoikoXeffdd4uPj+fzzz/nss8/ImTMn+/fvJ3fu3EmHa2jBkSNHePjhh6lQoQLh4eGEh4dz+vRp9u/fn/R8OXLkYMaMGXz55ZecO3eO0aNHX/Fzt2jRglKlSlG2bFl69+7NZ599xtmzZzP7SxYRyVDZbBcgIuJPdu/eTWRkJImJiezbt4/q1atTtGhRtm7dmnSffPnyAdCvXz+OHj3K6NGjKVWqFEFBQTRs2JC4uLgUz7lu3TrArCxw/PhxcuXKddnPHRoayi+//MKqVatYunQpL730EsOGDWPjxo3kyZMnU75eEZGMpmEDIiJZJC4ujptuuomaNWty44038t5777F9+3YKFy582fuHhoYybtw4evfuDcCBAwcoWbIko0aNSpqE9c8//1CzZk3ef/99Pv/8c86fP8+KFSsICDBvrCUfNnCxM2fOkCdPHubMmUPnzp0z5WsWEclo6nkVEckiQ4cOJTo6mvfff5/cuXPz3Xffcf/997Nw4cLL3v+GG25g+vTp1K1bl5iYGJ5++mmCg4OTbk9ISKB37960bNmSe++9l9atW1OtWjVGjhzJ008/fcnzLVy4kN27d3PbbbeRN29evv32WxITE6lYsWKmfc0iIhlNY15FRLLAqlWrGD16NNOnTycsLIyAgACmT5/O2rVrGT9+/GUf8+mnn3LixAlq1apF7969efzxxylUqFDS7W+88QZ79+7lo48+AiAiIoKPP/6YF154IcUwBJc8efLw1Vdf0axZMypVqsSECROYNWsWVapUyZSvWUQkM2jYgIiIiIh4DfW8ioiIiIjXUHgVEREREa+h8CoiIiIiXkPhVURERES8hsKriIiIiHgNhVcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeBURERERr6HwKiIiIiJe4/8AREhVHVRActsAAAAASUVORK5CYII=",
"text/plain": [
"
\n",
"\n",
"*Note*: NumPy arrays can have an arbitrary positive integer number of axes. If we have an N-D array with N > 3, we just need to (mentally) project it onto a smaller dimensional space so that we can have a handle of what each axis means.}\n",
"\n",
"Therefore, returning to `np.sum`, we see that"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "GtCGMCpp8QQT"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])\n",
"print(np.sum(a, axis=0)) # Prints [[ 6, 8],\n",
" # [10, 12]]\n",
"print(np.sum(a, axis=1)) # Prints [[ 4, 6],\n",
" # [12, 14]]\n",
"print(np.sum(a, axis=2)) # Prints [[ 3, 7],\n",
" # [11, 15]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "aF5DV48W9AKp"
},
"source": [
"## Task 2.3: Finding Maximum Daily Increase in Cases"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nKwWcvbp9CiU"
},
"source": [
"Our third task is to implement `find_max_increase_in_cases` which takes in one argument `n_cases_increase` and **finds the maximum daily increase in confirmed cases for each country**.\n",
"\n",
"In this case, `n_cases_increase` is the output obtained from calling `compute_increase_in_cases(n_cases_cumulative)`.\n",
"\n",
"The return value should be a 1D `np.ndarray` that represents the maximum daily increase in cases for each country. In particular, the $i$-th entry of this array should correspond to the increase in confirmed cases in the $i$-th country as represented in `n_cases_increase`.\n",
"\n",
"Returning to our previous example in task 2.2, suppose the daily increase in cases is given by `np.array([[1, 1, 1, 1], [1, 2, 3, 4]])`. Clearly, the maximum daily increase in cases is 1 and 4 for country 0 and 1, respectively. Therefore, we should expect the output of this function to be `np.array([1, 4])`.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"In this task, the goal is to learn how to use `np.max`, or the equivalent `np.amax`, to find the max value in a column of a matrix. The following is a sample execution of how these functions work:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.arange(4).reshape((2,2)) # array([[0, 1], [2, 3]])\n",
"np.amax(a) # 3 -> Maximum of the flattened array\n",
"np.amax(a, axis=0) # array([2, 3]) -> Maxima along the first axis (first column) \n",
"np.amax(a, axis=1) # array([1, 3]) -> Maxima along the second axis (second column)\n",
"np.amax(a, where=[False, True], initial=-1, axis=0) # array([-1, 3])\n",
"b = np.arange(5, dtype=float) # array([0., 1., 2., 3., 4.])\n",
"b[2] = np.NaN # array([ 0., 1., nan, 3., 4.])\n",
"np.amax(b) # nan"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TnYgBS0m9B63"
},
"outputs": [],
"source": [
"def find_max_increase_in_cases(n_cases_increase):\n",
" '''\n",
" Finds the maximum daily increase in confirmed cases for each country.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the daily increase in the number of confirmed cases on the\n",
" (j + 1)th day in the ith country.\n",
" \n",
" Returns\n",
" -------\n",
" Maximum daily increase in cases for each country as a 1D `ndarray` such that the\n",
" ith entry corresponds to the increase in confirmed cases in the ith country as\n",
" represented in `n_cases_increase`.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.3\n",
"n_cases_increase = np.ones((100, 20))\n",
"actual = find_max_increase_in_cases(n_cases_increase)\n",
"expected = np.ones(100)\n",
"assert(np.all(actual == expected))\n",
"\n",
"sample_increase = np.array([[1,2,3,4,8,8,10,10,10,10],[1,1,3,5,8,10,15,20,25,30]])\n",
"expected2 = np.array([10, 30]) # max of [1,2,3,4,8,8,10,10,10,10] => 10, max of [1,1,3,5,8,10,15,20,25,30] => 30\n",
"assert(np.all(find_max_increase_in_cases(sample_increase) == expected2))\n",
"\n",
"sample_increase2 = np.array([\\\n",
" [51764, 84, 159, 140, 183, 0],\\\n",
" [55755, 499, 318, 574, 581, 589],\\\n",
" [97857, 392, 382, 357, 323, 299]])\n",
"expected3 = np.array([51764, 55755, 97857])\n",
"assert(np.all(find_max_increase_in_cases(sample_increase2) == expected3))\n",
"\n",
"n_cases_increase2 = compute_increase_in_cases(cases_top_cumulative.shape[1], cases_top_cumulative)\n",
"expected4 = np.array([ 68699., 97894., 258110.])\n",
"assert(np.all(find_max_increase_in_cases(n_cases_increase2) == expected4))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "e10BJ74p9eS-"
},
"source": [
"## Broadcasting"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PPuJv8kC9hJb"
},
"source": [
"*Broadcasting* makes it possible for us to apply arithmetic operations to arrays with different shapes. This is especially helpful when we have a smaller array and larger array such that we want to copy the smaller array multiple times such that its shape (i.e. the number of elements in each axis) is the same as the larger array's, before performing arithmetic operations on both arrays. Specifically, with broadcasting, we do not need to explicitly make copies of the smaller array for the arithmetic operation to work. \n",
"\n",
"For example,\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5danymoS9cqj"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"b = np.array([[0, 1, 2]])\n",
"c = np.array([[0, 1, 2], [0, 1, 2]])\n",
"d = np.full((2, 3), 5)\n",
"\n",
"print(a + b) # Prints [[1 3 5]\n",
" # [4 6 8]]\n",
" # Equivalent to a + c\n",
"print(a + 5) # Prints [[ 6, 7, 8],\n",
" # [ 9, 10, 11]]\n",
" # Equivalent to a + d"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3wZr_D4z9s3C"
},
"source": [
"The details of broadcasting can be found [here](https://numpy.org/doc/stable/user/basics.broadcasting.html).\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "EeYafm-090kt"
},
"source": [
"At times, we might need to add dimensions to one of the arrays so that broadcasting gives us our desired result. To do so, we can use `None`. \n",
"\n",
"For example, suppose we want to create a $3 \\times 2$ matrix, represented by `c`, from `a = np.array([4, 5, 6])` and `b = np.array([1, 2])` such that `c[i, j] = a[i] + b[j]`. Then, we can do the following"
]
},
{
"cell_type": "code",
"execution_count": 55,
"metadata": {
"id": "nbe68bm--FuQ"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[4 5 6]\n",
"[1 2]\n",
"[[4]\n",
" [5]\n",
" [6]]\n",
"[[1 2]]\n",
"[[5 6]\n",
" [6 7]\n",
" [7 8]]\n"
]
}
],
"source": [
"a = np.array([4, 5, 6])\n",
"print(a) # Prints [4, 5, 6]\n",
"b = np.array([1, 2])\n",
"print(b) # Prints [1, 2]\n",
"c = a[:, None] \n",
"print(c) # Prints [[4]\n",
" # [5]\n",
" # [6]]\n",
"d = b[None, :]\n",
"print(d) # Prints [[1 2]]\n",
"e = c + d\n",
"print(e) # Prints [[5 6]\n",
" # [6 7]\n",
" # [7 8]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qhIjMRK1-JM-"
},
"source": [
"Alternatively, we can use `reshape` to get the same results.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fulFjQf8-Icw"
},
"outputs": [],
"source": [
"c = a.reshape((3, 1)) + b\n",
"print(c) # Prints [[5 6]\n",
" # [6 7]\n",
" # [7 8]]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ts_b7Hrk-QZ3"
},
"source": [
"## Task 2.4: Computing Number of Purchaseable Masks"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6DhPv99S-Tin"
},
"source": [
"Our fourth task is to implement `compute_n_masks_purchaseable`. This function takes two arguments, namely `healthcare_spending` and `mask_prices`, and it should **compute the total number of masks that each country can purchase if she spends all her emergency healthcare spending on masks**.\n",
"\n",
"Assume that all countries bought the masks at the global average costs, and to reduce administrative hassle, they only buy masks on day $(j + 1)$ with their emergency funds on day $(j + 1)$, i.e. the masks that are bought on a particular day are not purchased with funding from the previous days.\n",
"\n",
"The return value should be the total number of masks, which each country can purchase, represented as a 1D `np.ndarray` such that the $i$-th entry corresponds to the total number of masks purchaseable by the $i$-th country as represented in `healthcare_spending`.\n",
"\n",
"For example, if we have `healthcare_spending = np.array([[0, 100, 0], [100, 0, 200]])` and `mask_prices = np.array([4, 3, 20])`. Then, we expect the return value to be `np.array([3300. 3500.])`. This is because country 0 can only buy $33 \\times 100 = 3300$ masks on day 2 with \\$100 since the masks are priced at \\$3 and are sold in batches of 100. Similarly, we find that country 1 can only buy $(25 + 10) \\times 100 = 3500$ masks. \n",
"\n",
"In this task, you may use the `np.sum` and the `np.floor` functions.\n",
"\n",
"**Note**:\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "lscWd3LX-SR7"
},
"outputs": [],
"source": [
"def compute_n_masks_purchaseable(healthcare_spending, mask_prices):\n",
" '''\n",
" Computes the total number of masks that each country can purchase if she\n",
" spends all her emergency healthcare spending on masks.\n",
" Parameters\n",
" ----------\n",
" healthcare_spending: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the emergency healthcare\n",
" spending made by that country, i.e. the ith row of `healthcare_spending`\n",
" contains the data of the ith country, and the (i, j) entry of\n",
" `healthcare_spending` is the amount which the ith country spent on healthcare\n",
" on (j + 1)th day.\n",
" mask_prices: np.ndarray\n",
" 1D `ndarray` such that the jth entry represents the cost of 100 masks on the\n",
" (j + 1)th day.\n",
" \n",
" Returns\n",
" -------\n",
" Total number of masks which each country can purchase as a 1D `ndarray` such\n",
" that the ith entry corresponds to the total number of masks purchaseable by the\n",
" ith country as represented in `healthcare_spending`.\n",
" Note\n",
" ----\n",
" The masks can only be bought in batches of 100s.\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.4\n",
"prices_constant = np.ones(5)\n",
"healthcare_spending_constant = np.ones((7, 5))\n",
"actual = compute_n_masks_purchaseable(healthcare_spending_constant, prices_constant)\n",
"expected = np.ones(7) * 500\n",
"assert(np.all(actual == expected))\n",
"\n",
"healthcare_spending1 = healthcare_spending[:3, :] #Using data from CSV\n",
"expected2 = [3068779300, 378333500, 6208321700]\n",
"assert(np.all(compute_n_masks_purchaseable(healthcare_spending1, mask_prices)==expected2))\n",
"\n",
"healthcare_spending2 = np.array([[0, 100, 0], [100, 0, 200]])\n",
"mask_prices2 = np.array([4, 3, 20])\n",
"expected3 = np.array([3300, 3500])\n",
"assert(np.all(compute_n_masks_purchaseable(healthcare_spending2, mask_prices2)==expected3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "h-S8a06N_GP6"
},
"source": [
"## Matrix Multiplication"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_lN2l9BV_INc"
},
"source": [
"To perform matrix multiplication on two NumPy arrays, we use the syntax `@`. In particular, if we want to multiply array `A` and `B`, we will do `A @ B`. For example,\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.array([[1,1],[1,2]]) # array([[1, 1], [1, 2]])\n",
"b = np.array([[1],[1]]) # array([[1], [1]])\n",
"c = a @ b\n",
"print(c) # Prints [[2]\n",
" # [3]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The specifics of this operations is as follow:\n",
"\n",
"- if A and B are both 2D, they are multiplied like conventional matrices.\n",
"- if one of them is N-D, with N > 2, that matrix is treated as a stack of matrices. Broadcasting will be done where necessary.\n",
"\n",
"More details can be found [here](https://numpy.org/doc/stable/user/basics.broadcasting.html)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZMRfyy8s_gCg"
},
"source": [
"## Task 2.5: Computing Stringency Index"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DdY664xo_hhn"
},
"source": [
"Our fifth last task for this homework is to implement `compute_stringency_index`. This function takes `stringency_values` as argument, and **computes the daily stringency index for each country**.\n",
"\n",
"This function returns the daily stringency index for each country as a 2D `np.ndarray` such that the $(i, j)$ entry corresponds to the stringency index in the $i$-th country on the $(j + 1)$-th day. In this case, the higher the stringency index, the more restrictive the measures are.\n",
"\n",
"Recall that on each day, each country has four stringency values for ’school closing’, ’workplace closing’, ’stay at home requirements’ and ’international travel controls’. In this case, we shall assume that 'stay at home requirements' is the most restrictive regulation among the other regulations; 'international travel controls' is more restrictive than 'school closing' and 'workplace closing'; and 'school closing' and 'workplace closing' are equally restrictive. Thus, to compute the stringency index, we shall weigh each stringency value by 1, 1, 3 and 2 for 'school closing', 'workplace closing', 'stay at home requirements' and 'international travel controls', respectively. Then, **the stringency index for the $i$th country on the $(j + 1)$th day is given by**:\n",
"\n",
"`stringency_values[i, j, 0] + stringency_values[i, j, 1] + 3 * stringency_values[i, j, 2] + 2 * stringency_values[i, j, 3]`\n",
"\n",
"**Note**: Use the matrix multiplication operator (`@` operator) to compute the stringency index. Please do not use iterative approaches like for-loops."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TnEqpaNo-z2v"
},
"outputs": [],
"source": [
"def compute_stringency_index(stringency_values):\n",
" '''\n",
" Computes the daily stringency index for each country.\n",
" Parameters\n",
" ----------\n",
" stringency_values: np.ndarray\n",
" 3D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the stringency values as a\n",
" vector. To be specific, on each day, there are four different stringency\n",
" values for 'school closing', 'workplace closing', 'stay at home requirements'\n",
" and 'international travel controls', respectively. For instance, the (i, j, 0)\n",
" entry represents the `school closing` stringency value for the ith country\n",
" on the (j + 1)th day.\n",
" \n",
" Returns\n",
" -------\n",
" Daily stringency index for each country as a 2D `ndarray` such that the (i, j)\n",
" entry corresponds to the stringency index in the ith country on the (j + 1)th\n",
" day.\n",
" In this case, we shall assume that 'stay at home requirements' is the most\n",
" restrictive regulation among the other regulations, 'international travel\n",
" controls' is more restrictive than 'school closing' and 'workplace closing',\n",
" and 'school closing' and 'workplace closing' are equally restrictive. Thus,\n",
" to compute the stringency index, we shall weigh each stringency value by 1,\n",
" 1, 3 and 2 for 'school closing', 'workplace closing', 'stay at home\n",
" requirements' and 'international travel controls', respectively. Then, the \n",
" index for the ith country on the (j + 1)th day is given by\n",
" `stringency_values[i, j, 0] + stringency_values[i, j, 1] +\n",
" 3 * stringency_values[i, j, 2] + 2 * stringency_values[i, j, 3]`.\n",
" Note\n",
" ----\n",
" Use matrix operations and broadcasting to complete this question. Please do\n",
" not use iterative approaches like for-loops.\n",
" '''\n",
" \n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.5\n",
"stringency_values = np.ones((10, 20, 4))\n",
"stringency_values[:, 10:, :] *= 2\n",
"actual = compute_stringency_index(stringency_values)\n",
"expected = np.ones((10, 20)) * (1 + 1 + 3 + 2)\n",
"expected[:, 10:] *= 2\n",
"assert(np.all(actual == expected))\n",
"\n",
"stringency_values2 = np.array([[[0, 0, 0, 0], [1, 0, 0, 0]], [[0, 0, 0, 0], [0, 1, 2, 0]]])\n",
"actual2 = compute_stringency_index(stringency_values2)\n",
"expected2 = np.array([[0, 1], [0, 7]])\n",
"assert(np.all(actual2 == expected2))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nqtOvepLARkQ"
},
"source": [
"## More Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F5OtHQYwAU_q"
},
"source": [
"In fact, indexing in NumPy can be more sophisticated than what we have seen previously! \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZMxvRCGCAZe9"
},
"source": [
"### Integer Array Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "17ngFFwGAddt"
},
"source": [
"We can use a Python list or a NumPy array to index a NumPy array. For example,"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "te4V8yif_6JG"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[1, 2, 3], [4, 5, 6]])\n",
"print(a[:, [0, 2]]) # Prints [[1 3]\n",
" # [4 6]]\n",
"print(a[[1, 0], [1, 2]]) # Prints [5 3]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7J5iATyJAffY"
},
"source": [
"Note that `a[[1, 0], [1, 2]]` essentially returns `a[1, 1]` and `a[0, 2]`."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PO3JUERDAp-V"
},
"source": [
"### Boolean Array Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "wofAGm5VAq84"
},
"source": [
"An array of Boolean can be used to determine which elements of a given array should be left out. For instance,"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "RPG5cp5EAlpr"
},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([4, 3, 1, 5, 10])\n",
"desired_indices = a > 3\n",
"print(a[desired_indices]) # Selects values in `a` that are\n",
" # greater than 3; prints [ 4 5 10]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Introduction to Matplotlib\n",
"\n",
"Matplotlib is a powerful and widely-used Python library for creating visualisations. We can use it to generate a wide variety of plots, charts, and graphs. We will make use of this library often in future problem sets.\n",
"\n",
"Below is an example of how to use Matplotlib to plot two different functions in the same graph"
]
},
{
"cell_type": "code",
"execution_count": 57,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAq8AAAIhCAYAAABg21M1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8qNh9FAAAACXBIWXMAAA9hAAAPYQGoP6dpAAB0RUlEQVR4nO3dd1jV5f/H8ecBFUEBt7hXau6dWpYjNTW3mblt2NLKzOpbNmxpy9QsR1bOHGVppuVO09RS0zQry9wiaQ5wgsD5/XH/DgecgMB9xutxXZ/r3JzFm/Xhde5zD4fT6XQiIiIiIuIFAmwXICIiIiKSWgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvIbCq4iIiIh4DYVXEREREfEaCq8ikiGmTJmCw+FIOrJly0bx4sW59957OXToUNL9Vq1ahcPhYNWqVWn+HOvWrWPYsGGcPHnyktvGjRvHlClTLrl+7969OByOy96WmZo0aZLi+3GlY9iwYVlaV79+/a5Yy8KFC7O0losNHz6c+fPnX3L99fzOiIjvyWa7ABHxLZMnT+bGG2/k3Llz/PDDD4wYMYLVq1ezfft2cuXKdV3PvW7dOl555RX69etHnjx5Utw2btw4ChQoQL9+/VJcX6RIEdavX0+5cuWu63On1bhx44iJiUn6eNGiRbz++utJ3x+X4sWLZ2ldAMHBwaxcufKS65PXZcPw4cO566676NixY4rra9euzfr166lcubKdwkTEoyi8ikiGqlq1KnXr1gWgadOmJCQk8NprrzF//nx69uyZ5fUEBQXRoEGDLP+8FwetP//8E0j5/bElICDAyvckvcLCwryqXhHJXBo2ICKZyhU69u3bd9X7LViwgIYNGxISEkJoaCgtWrRg/fr1SbcPGzaMp59+GoAyZcokvdW9atUqSpcuzY4dO1i9enXS9aVLlwYuP2xg2LBhOBwOduzYQffu3QkPD6dw4cLcd999REdHp6jr5MmT3H///eTLl4/cuXNz5513snv37ut+y//DDz8kICCAI0eOJF03cuRIHA4HAwYMSLouMTGRvHnz8tRTTyVdd/z4cR599FGKFStGjhw5KFu2LEOHDiU2Njbd9bhc6S36y30f+/XrR+7cudm1axdt2rQhd+7clChRgqeeeuqSWmJjY3n11VepVKkSOXPmJH/+/DRt2pR169YB4HA4OHPmDFOnTk36GTZp0uSqNV3rdwbS9rP+4osvqF+/PuHh4YSEhFC2bFnuu+++9H8zRSRTKLyKSKbatWsXAAULFrzifWbOnEmHDh0ICwtj1qxZfPLJJ5w4cYImTZqwdu1aAB544AEee+wxAL766ivWr1/P+vXrqV27NvPmzaNs2bLUqlUr6fp58+Zds7YuXbpQoUIFvvzyS/73v/8xc+ZMnnzyyaTbExMTadeuHTNnzuTZZ59l3rx51K9fn1atWl3PtwSA5s2b43Q6WbFiRdJ1y5cvJzg4mGXLliVdt2nTJk6ePEnz5s0BOH/+PE2bNmXatGkMHjyYRYsW0atXL95++206d+6c6s8fHx+f4khISEjX13HhwgXat2/P7bffztdff819993HqFGjeOutt1J8rtatW/Paa6/Rtm1b5s2bx5QpU7j55pvZv38/AOvXryc4OJg2bdok/QzHjRt3xc+bmt+Z5K71s16/fj3dunWjbNmyzJ49m0WLFvHSSy8RHx+fru+LiGQip4hIBpg8ebITcG7YsMF54cIF56lTp5wLFy50FixY0BkaGuqMiopyOp1O5/fff+8EnN9//73T6XQ6ExISnEWLFnVWq1bNmZCQkPR8p06dchYqVMh58803J133zjvvOAHnnj17Lvn8VapUcTZu3PiS6/fs2eMEnJMnT0667uWXX3YCzrfffjvFfR999FFnzpw5nYmJiU6n0+lctGiRE3COHz8+xf1GjBjhBJwvv/xymr8/GzduTLquePHizvvuu8/pdDqdsbGxzly5cjmfffZZJ+Dct2+f0+l0Ot944w1n9uzZnadPn3Y6nU7nhAkTnIDz888/T/H8b731lhNwLl269Kp19O3b1wlcctxyyy1Op/PSn4/L5b6Prue6uJY2bdo4K1asmPTxtGnTnIBz0qRJV60tV65czr59+15y/fX8zqT2Z/3uu+86AefJkyevWqOI2KeeVxHJUA0aNCB79uyEhobStm1bIiIi+O677yhcuPBl779z504iIyPp3bs3AQHuU1Lu3Lnp0qULGzZs4OzZs5lSa/v27VN8XL16dc6fP5/0Vv7q1asBuPvuu1Pcr3v37hny+W+//XaWL18OmMloZ8+eZfDgwRQoUCCp93X58uU0bNgwabLbypUryZUrF3fddVeK53JNVEvek3slwcHBbNy4McXxySefpOtrcDgctGvXLsV11atXTzFM5LvvviNnzpwZ9hZ8en5nrvWzrlevHmB+1p9//nmKFTJExLMovIpIhpo2bRobN25ky5YtREZGsm3bNm655ZYr3v/YsWOAWRXgYkWLFiUxMZETJ05kSq358+dP8XFQUBAA586dS6otW7Zs5MuXL8X9rhTE06p58+bs37+fv//+m+XLl1OrVi0KFSpEs2bNWL58OefOnWPdunVJQwZcNUVEROBwOFI8V6FChciWLVvS9/NqAgICqFu3boqjYsWK6foaQkJCyJkzZ4rrgoKCOH/+fNLHR48epWjRoimC5vVIz+/MtX7Wt912G/Pnzyc+Pp4+ffpQvHhxqlatyqxZszKkZhHJOAqvIpKhKlWqRN26dalZs+Zlw8XFXKHi8OHDl9wWGRlJQEAAefPmzfA6UyN//vzEx8dz/PjxFNdHRUVlyPPffvvtgOldXbZsGS1atEi6fsWKFfzwww/ExsamCK/58+fn33//xel0pniuI0eOEB8fT4ECBa6rJlcQvXjC1X///Zfu5yxYsCCRkZEkJiZeV20umfU706FDB1asWEF0dDSrVq2iePHi9OjR45JJYCJil8KriFhVsWJFihUrxsyZM1MEsjNnzvDll18mzSaHS3vLkgsKCrrs9dejcePGAMyZMyfF9bNnz86Q5y9SpAiVK1fmyy+/ZPPmzUnhtUWLFhw9epT33nuPsLCwpLe0wQTb06dPX7KY/7Rp05Juvx6uVRq2bduW4voFCxak+zlbt27N+fPnr7lRRGp/hmn5nUmPoKAgGjdunDTpbMuWLel+LhHJeFrnVUSsCggI4O2336Znz560bduWhx56iNjYWN555x1OnjzJm2++mXTfatWqATBmzBj69u1L9uzZqVixIqGhoVSrVo3Zs2czZ84cypYtS86cOZPun16tWrXilltu4amnniImJoY6deqwfv36pKCYEW+D33777YwdO5bg4OCk4RVlypShTJkyLF26lPbt25Mtm/tU3adPHz788EP69u3L3r17qVatGmvXrmX48OG0adMmRS9tekRERNC8eXNGjBhB3rx5KVWqFCtWrOCrr75K93N2796dyZMn8/DDD7Nz506aNm1KYmIiP/30E5UqVeKee+4BzM931apVfPPNNxQpUoTQ0NDLDmdIy+9Mar300kscPHiQ22+/neLFi3Py5EnGjBlD9uzZk17EiIhnUM+riFjXo0cP5s+fz7Fjx+jWrRv33nsvYWFhfP/99zRq1Cjpfk2aNOG5557jm2++oVGjRtSrV4/NmzcD8Morr9C4cWP69+/PTTfddMkkovQICAjgm2++4Z577uHNN9+kQ4cOrFmzhhkzZgBcsstXerjCZqNGjVKMHXVdf3EYzZkzJ99//z09e/bknXfeoXXr1kyZMoUhQ4ZcV8BMbvr06dx+++08++yzdO3alUOHDl3X2M9s2bLx7bff8txzzzFv3jw6dOhAnz59WLt2LaVKlUq635gxYyhfvjz33HMP9erV46GHHrric6b2dya16tevT1RUFM8++ywtW7bkwQcfTNqJrEqVKun6ukUkczicFw+cEhGRq5o5cyY9e/bkxx9/5Oabb7ZdjoiIX1F4FRG5ilmzZnHo0CGqVatGQEAAGzZs4J133qFWrVpJS2mJiEjW0ZhXEZGrCA0NZfbs2bz++uucOXOGIkWK0K9fP15//XXbpYmI+CX1vIqIiIiI19CELRERERHxGgqvIiIiIuI1FF5FRERExGv4/IStxMREIiMjCQ0NvWQvcBERERGxz+l0curUKYoWLXrNDWB8PrxGRkZSokQJ22WIiIiIyDUcOHCA4sWLX/U+Ph9eQ0NDAfPNCAsLs1yNiIiIiFwsJiaGEiVKJOW2q/H58OoaKhAWFqbwKiIiIuLBUjPEUxO2RERERMRrKLyKiIiIiNdQeBURERERr+HzY15FxL84nU7i4+NJSEiwXYpcp8DAQLJly6ZlDkUkBYVXEfEZcXFxHD58mLNnz9ouRTJISEgIRYoUIUeOHLZLEREPofAqIj4hMTGRPXv2EBgYSNGiRcmRI4d67LyY0+kkLi6Oo0ePsmfPHsqXL3/NhctFxD8ovIqIT4iLiyMxMZESJUoQEhJiuxzJAMHBwWTPnp19+/YRFxdHzpw5bZckIh5AL2NFxKeod8636OcpIhfTWUFEREREvIbCq4iIiIh4DYVXERG5qnnz5pEtWzYqVKjAkSNHbJcjIn5O4VVERK7o+++/p0ePHrz88ssUKlSIVq1aERMTk+I+e/fu5f7776dMmTIEBwdTrlw5Xn75ZeLi4ixVLSK+TOFVREQua/PmzXTq1In33nuPF198kSVLlpAvXz7at2/P+fPnk+73559/kpiYyMSJE9mxYwejRo1iwoQJPP/88xarFxFfpfAqIj7L6YQzZ+wcTmfqapw2bRr58+cnNjY2xfVdunShT58+mfBdgVWrVpEjRw7WrFmTdN3IkSMpUKAAhw8fBmDnzp20bduW999/n0ceeQSAXLlysWjRIsLCwujWrRvx8fEAtGrVismTJ9OyZUvKli1L+/btGTJkCF999VWm1C8i/s1qeB0xYgT16tUjNDSUQoUK0bFjR3bu3JniPv369cPhcKQ4GjRoYKliEfEmZ89C7tx2jtRu8tW1a1cSEhJYsGBB0nX//fcfCxcu5N57773i46pUqULu3LmveFSpUuWKj23SpAmDBg2id+/eREdH8+uvvzJ06FAmTZpEkSJFAKhYsSKHDx++JEAHBQWxYMECvv76a7Jlu/JS4dHR0eTLly913wQRkTSwuknB6tWrGTBgAPXq1SM+Pp6hQ4fSsmVLfv/9d3LlypV0P9erehdtEygiviI4OJgePXowefJkunbtCsBnn31G8eLFadKkyRUf9+2333LhwoUr3p49e/arft7XX3+d5cuX8+CDD7Jjxw569+5Np06d0vU1XOyff/5h7NixjBw5MkOeT0QkOavhdfHixSk+njx5MoUKFWLz5s3cdtttSdcHBQURERGR1eWlyz//wLx5MHgwaG1tEbtCQuD0aXufO7X69+9PvXr1OHToEMWKFWPy5MlJ7zpdSalSpa6rvhw5cjBjxgyqV69OqVKlGD169HU9n0tkZCStWrWia9euPPDAAxnynCKStZxOGDMGWrWCG2+0Xc2lPGp72OjoaIBL3mpatWoVhQoVIk+ePDRu3Jg33niDQoUKXfY5YmNjU4wdu3hWbGaKjYXatSEmBho0gEaNsuxTi8hlOByQ7E0cj1WrVi1q1KjBtGnTuOOOO9i+fTvffPPNVR9TpUoV9u3bd8XbS5UqxY4dO676HOvWrQPg+PHjHD9+PMU7XukRGRlJ06ZNadiwIR999NF1PZeI2LNtGzz5JPzvf3D0KISG2q4oJY8Jr06nk8GDB9OoUSOqVq2adH3r1q3p2rUrpUqVYs+ePbz44os0a9aMzZs3ExQUdMnzjBgxgldeeSUrS08SFASdOsHUqfDZZwqvIpJ6DzzwAKNGjeLQoUM0b96cEiVKXPX+1zts4J9//uHJJ59k0qRJfP755/Tp04cVK1akezvWQ4cO0bRpU+rUqcPkyZO1rauIF5s501y2bet5wRXA4XSmdk5s5howYACLFi1i7dq1FC9e/Ir3O3z4MKVKlWL27Nl07tz5ktsv1/NaokQJoqOjCQsLy5Tak1u2DFq2hHz54PBh0PBckaxx/vx59uzZQ5kyZciZM6ftctIsJiaGIkWKEB8fz7Rp0+jWrVumfa6EhARuvfVWihQpwpdffklUVBTVqlXjmWee4emnn07z80VGRtK4cWNKlizJtGnTCAwMTLrteod8efvPVcTbJCZCmTKwfz/MnQtdumTN542JiSE8PDxVec0jel4fe+wxFixYwA8//HDV4ApQpEgRSpUqxd9//33Z24OCgi7bI5tVmjWDwoXh339h6VLzqkVE5FrCwsLo0qULixYtomPHjpn6ud544w327t2bNDQhIiKCjz/+mLvvvpsWLVpQs2bNND3f0qVL2bVrF7t27brkHO4h/SMikkrr1pngGhYGbdrYrubyrL6v43Q6GThwIF999RUrV66kTJky13zMsWPHOHDgQNJyLp4mMBDuuce0P/vMbi0i4l0OHz5Mz549M/0F+EsvvURkZCT58+dPuq5Dhw7ExsamObiCWdLQ6XRe9hAR7+IaMtC5MwQH263lSqyG1wEDBjBjxgxmzpxJaGgoUVFRREVFce7cOQBOnz7NkCFDWL9+PXv37mXVqlW0a9eOAgUKZNiSLpmhZ09z+fXXcOqU3VpExPMdP36c2bNns3LlSgYMGGC7HBHxUxcuwOefm3b37nZruRqrwwbGjx8PcMlahq5lYgIDA9m+fTvTpk3j5MmTFClShKZNmzJnzhxCPXEE8f+rWxfKl4e//zYBtlcv2xWJiCerXbs2J06c4K233qJixYq2yxERP7V8ORw7BoUKmWGQnspqeL3WW0rBwcEsWbIki6rJOA4H9OgBr7xihg4ovIrI1ezdu9d2CSIiSUMGunWDq2ygZ53WMskkrqEDy5bBkSN2axERERG5mrNnzSZL4NlDBkDhNdOULw/16kFCgnv8iIiIiIgn+vprOHPGLJPVoIHtaq5O4TUTuXpfteqAiIiIeDJXVunZ0wx/9GQKr5moWzcICIANG+Cff2xXIyIiInKpo0dh8WLTdnW8eTKF10wUEQG3327as2bZrUVERETkcubMMcMc69aFG2+0Xc21KbxmsuRDB7Ret4iIiHia5EMGvIHCaybr1Aly5oQ//4QtW2xXIyJybaVLl2b06NFpftyLL77Igw8+mOr7f/DBB7Rv3z7Nn0dEMs6uXWZ4Y0CAe4dQT6fwmsnCwqBdO9N2rZ8mIuLJNm7cmKYQCvDvv/8yZswYnn/++VQ/pn///mzcuJG1a9emtUQRySCubNKihRnu6A0UXrOAqxt+1iwzpkRExJMVLFiQkJCQND3mk08+oWHDhpQuXTrVjwkKCqJHjx6MHTs2jRWKSEZwOmHGDNP2liEDoPCaJVq3hrx5ITISVq+2XY2IH3E6zcKFNo5UDnKfNm0a+fPnJzY2NsX1Xbp0oU+fPpnxXQFg2LBhlCxZkqCgIIoWLcrjjz+edNvFwwYcDgcff/wxnTp1IiQkhPLly7NgwYIUzzd79uwUQwCOHj1KREQEw4cPT7rup59+IkeOHCxdujTpuvbt2zN//nzOnTuXCV+liFzNxo1mK/uQEDPM0VsovGaBHDngrrtMW0MHRLLQ2bOQO7ed4+zZVJXYtWtXEhISUoTB//77j4ULF3Lvvfde8XFVqlQhd+7cVzyqVKlyxcfOnTuXUaNGMXHiRP7++2/mz59PtWrVrlrnK6+8wt133822bdto06YNPXv25Pjx4wCcOHGC3377jbp16ybdv2DBgnz66acMGzaMTZs2cfr0aXr16sWjjz5Ky5Ytk+5Xt25dLly4wM8//3zN75WIZCzXRK0OHcxpy1t48M61vqVnT5g0CebOhQ8+MJO4RESCg4Pp0aMHkydPpmvXrgB89tlnFC9enCZNmlzxcd9++y0XLly44u3Zs2e/4m379+8nIiKC5s2bkz17dkqWLMlNN9101Tr79etH9//fM3L48OGMHTuWn3/+mVatWrFv3z6cTidFixZN8Zg2bdrQv39/evbsSb169ciZMydvvvlmivvkypWLPHnysHfvXho3bnzVGkQk48THw+zZpt2rl91a0krhNYvceiuUKAEHDsC330LnzrYrEvEDISFw+rS9z51K/fv3p169ehw6dIhixYoxefJk+vXrh+Mq29yUKlUq3aV17dqV0aNHU7ZsWVq1akWbNm1o164d2bJd+V9C9erVk9q5cuUiNDSUI0eOACS95Z/zMq/K3333XapWrcrnn3/Opk2bLnuf4OBgzqayp1pEMsby5XDkCBQsaCZreRMNG8giAQHw/50WGjogklUcDsiVy86Rhv0Va9WqRY0aNZg2bRq//PIL27dvp1+/fld9zPUMGyhRogQ7d+7kww8/JDg4mEcffZTbbrstTT25DoeDxMREAAoUKACY4QMX2717N5GRkSQmJrJv377LPvfx48cpWLDgVb9eEclYrola3brBVd6o8Ujqec1CPXrA22/DwoUQHQ3h4bYrEhFP8cADDzBq1CgOHTpE8+bNKVGixFXvfz3DBsD0drZv35727dszYMAAbrzxRrZv307t2rXTXHu5cuUICwvj999/p0KFCknXx8XF0bNnT7p168aNN97I/fffz/bt2ylcuHDSff755x/Onz9PrVq10vx5RSR9Tp+GefNM29uGDIDCa5aqXh2qVIEdO+DLL+G++2xXJCKeomfPngwZMoRJkyYxbdq0a97/eoYNTJkyhYSEBOrXr09ISAjTp08nODg43c8ZEBBA8+bNWbt2LR07dky6fujQoURHR/P++++TO3duvvvuO+6//34WLlyYdJ81a9ZQtmxZypUrl+6vR0TS5uuvzZzSG26Aawx390gaNpCFHI6U28WKiLiEhYXRpUsXcufOnSIAZoY8efIwadIkbrnlFqpXr86KFSv45ptvyJ8/f7qf88EHH2T27NlJQwlWrVrF6NGjmT59OmFhYQQEBDB9+nTWrl3L+PHjkx43a9Ys+vfvf91fk4ikXvK1XdMwwsljOJzOVC5G6KViYmIIDw8nOjqasLAw2+Wwbx+ULm1+WfbtM5O4ROT6nT9/nj179lCmTJnLTgryBi1atKBSpUq8//77tktJM6fTSYMGDRg0aFDSqgTX8ttvv3H77bfz119/EX6FcVS+8HMV8ST//gtFi0JiIvz1F5Qvb7siIy15TT2vWaxUKWjSxKxfrt5XEQEzYWn27NmsXLmSAQMG2C4nXRwOBx999BHx8fGpfkxkZCTTpk27YnAVkYw3Z44JrvXre05wTSuNebWgd29YtQqmT4dnn/XOLnsRyTi1a9fmxIkTvPXWW1SsWNF2OelWo0YNatSoker7J9+sQESyhjduB3sxhVcL7roLBgyA33+HX36BOnVsVyQiNu3du9d2CSLiB/76y2wJGxholsjyVho2YEFYGLjmY6RiUrGIiIjIdXMNV2zZEgoVslvL9VB4taRPH3M5axZcZalGEUkjH5+D6nf08xTJGE6ne8iAN67tmpzCqyUtWkDhwnD0KCxZYrsaEe/nWpRf24z6FtfP81qbLojI1f30E+zebTYA7NDBdjXXR2NeLcmWzey4NWqUmbjVtq3tikS8W2BgIHny5OHIkSMAhISE4NBsSK/ldDo5e/YsR44cIU+ePAQGBtouScSrTZ9uLjt1MgHWm2mdV4u2bIHatSEoCKKiIE8e2xWJeDen00lUVBQnT560XYpkkDx58hAREaEXIiLXITYWihSBEydg6VLz7q+nSUteU8+rRTVrQtWq8NtvMHcuPPCA7YpEvJvD4aBIkSIUKlSICxpM7vWyZ8+uHleRDLBokQmuxYpBs2a2q7l+Cq8WORxmzddnnzWrDii8imSMwMBAhR4Rkf83daq57NXLLJPl7TRhyzLXvsJr1sCePbarEREREV9y9Ch8+61pu1Y68nYKr5YVKwa3327ariUsRERERDLCrFkQHw9160LlyraryRgKrx7A9Upo2jSzDpuIiIhIRnBthtS3r906MpLCqwfo1AlCQmDXLrMOm4iIiMj12rEDNm+G7NnhnntsV5NxFF49QO7c0KWLaWu7WBEREckIrkxx551QoIDdWjKSwquH6N3bXM6ZY9ZjExEREUmvhAT3XBpfmajlovDqIZo1g6JF4fhx96xAERERkfRYvhwiIyFfPtPz6ksUXj1EYKBZNgvcW7iJiIiIpIdryED37pAjh91aMprCqwdxdesvXAjHjtmtRURERLxTTAzMm2favrTKgIvCqwepWtVsGXvhAnz+ue1qRERExBvNnQvnzsGNN5r1XX2NwquHSb7mq4iIiEhaubaD7dvX7OLpaxRePUz37hAQABs2wF9/2a5GREREvMmePfDDDya09uplu5rMofDqYSIioFUr03a9chIRERFJDdek79tvh+LF7daSWRRePVC/fuZy6lSzTpuIiIjItTid7mGHvra2a3IKrx6ofXvImxcOHYIVK2xXIyIiIt5g3Tr45x+zc2fnzraryTwKrx4oKAh69DDtyZPt1iIiIiLewdXretddkCuX3Voyk8Krh7r3XnM5bx6cOGG3FhEREfFs586ZLebBt4cMgMKrx6pd26z7Ghvr/mUUERERuZwFCyA6GkqWhMaNbVeTuRRePZTD4e591dABERERuRrXkIHevc2Sm77Mx78879arF2TLBj//DL//brsaERER8USHD8OSJabt60MGQOHVoxUqBG3amPaUKVZLEREREQ81bZpZWvPmm6FCBdvVZD6FVw/nGjowfTrEx9utRURERDyL0+keXnjffXZrySoKrx6uTRsoUACiotxvCYiIiIgArF8PO3dCSAjcfbftarKGwquHy5HDvTexJm6JiIhIcp9+ai67doXQULu1ZBWFVy/gGjqwYAEcO2a3FhEREfEMZ864l9P0lyEDoPDqFapXh1q14MIFmDnTdjUiIiLiCebOhdOn4YYb4NZbbVeTdRRevYSr91WrDoiIiAi4hwz062fWh/cXCq9eont3yJ4dfvkFtm2zXY2IiIjYtGsX/PCDCa19+9quJmspvHqJAgWgfXvT1sQtERER/+Z6J7ZlSyhe3GopWU7h1Yu4hg7MmAFxcXZrERERETsSEmDqVNP2p4laLgqvXuSOOyAiAv77D7791nY1IiIiYsPy5XDwIOTLBx062K4m6ym8epFs2aB3b9PWxC0RERH/5Jqo1aMHBAXZrcUGhVcv06+fuVy0CI4csVqKiIiIZLHjx2H+fNP2xyEDoPDqdSpXhptugvh4M/ZVRERE/MfMmWbeS40aZg14f6Tw6oVcE7c+/RScTru1iIiISNZxDRnw115XUHj1SvfcA8HBsGMH/PST7WpEREQkK2zdClu2QI4c0LOn7WrsUXj1QnnyQNeupv3JJ1ZLERERkSziWue9fXvIn99uLTYpvHqpBx4wl7NmwalTdmsRERGRzBUb657r4s9DBkDh1Ws1agQVKsCZM/D557arERERkcz0zTdmpYFixcyuWv5M4dVLORxw//2m/fHHdmsRERGRzOWaqNWnDwQG2q3FNoVXL9anj9m4YMMG+O0329WIiIhIZjh0CJYsMW3XikP+TOHVi0VEQLt2pq2JWyIiIr5p6lRITDRDBsuXt12NfVbD64gRI6hXrx6hoaEUKlSIjh07snPnzhT3cTqdDBs2jKJFixIcHEyTJk3YsWOHpYo9j2vi1rRpZjC3iIiI+I7ERPfwQNdwQX9nNbyuXr2aAQMGsGHDBpYtW0Z8fDwtW7bkzJkzSfd5++23ee+99/jggw/YuHEjERERtGjRglOaYg/AHXeYwdvHj8PXX9uuRkRERDLSypWwZw+EhbmXyfR3VsPr4sWL6devH1WqVKFGjRpMnjyZ/fv3s3nzZsD0uo4ePZqhQ4fSuXNnqlatytSpUzl79iwzZ8687HPGxsYSExOT4vBlgYHuJTM0cUtERMS3uP639+wJuXLZrcVTeNSY1+joaADy5csHwJ49e4iKiqJlsjUhgoKCaNy4MevWrbvsc4wYMYLw8PCko0SJEplfuGWuwdvLlplXZyIiIuL9/vsP5s0z7f797dbiSTwmvDqdTgYPHkyjRo2oWrUqAFFRUQAULlw4xX0LFy6cdNvFnnvuOaKjo5OOAwcOZG7hHqBMGWje3LRdu2+IiIiId5s+HeLioHZtqFXLdjWew2PC68CBA9m2bRuzZs265DaHw5HiY6fTecl1LkFBQYSFhaU4/IFr4tann0JCgt1aRERE5Po4nTBpkmmr1zUljwivjz32GAsWLOD777+nePHiSddHREQAXNLLeuTIkUt6Y/1dx46QL1/KteBERETEO61bB3/8ASEh0KOH7Wo8i9Xw6nQ6GThwIF999RUrV66kTJkyKW4vU6YMERERLFu2LOm6uLg4Vq9ezc0335zV5Xq0oCCzaQFozVcRERFv55qodffdZqUBcbMaXgcMGMCMGTOYOXMmoaGhREVFERUVxblz5wAzXGDQoEEMHz6cefPm8dtvv9GvXz9CQkLooZchl3Ct/7ZgAfz7r91aREREJH2io2HOHNPWkIFLWQ2v48ePJzo6miZNmlCkSJGkY47rJwY888wzDBo0iEcffZS6dety6NAhli5dSmhoqMXKPVPVqtCgAcTHm00LRERExPvMnAnnzkHlytCwoe1qPI/D6XQ6bReRmWJiYggPDyc6OtovJm99/LF5lVahAvz5J1xhXpuIiIh4qDp14JdfYNQoGDTIdjVZIy15zSMmbEnG6dbNLGL811+wdq3takRERCQtfvnFHDlyQK9etqvxTAqvPiY0FO65x7S145aIiIh3cS2P1bkzFChgtxZPpfDqg1xrvn7xBZw8abUUERERSaUzZ8x4V9BEratRePVB9etDlSpmsPeMGbarERERkdT44guIiYFy5aBJE9vVeC6FVx/kcMBDD5n2xIlmlw4RERHxbK4hA/ffDwFKaFekb42P6t0bgoPht99g/Xrb1YiIiMjV/P672VUrMBD69bNdjWdTePVRefKYlQfA9L6KiIiI53L1urZtC0WK2K3F0ym8+jDX0IHPP4cTJ+zWIiIiIpd37hxMnWrarv/dcmUKrz6sfn2oXh3On9eOWyIiIp7qiy9MJ1Pp0tCype1qPJ/Cqw/TxC0RERHP5xre17+/GfMqV6fw6uN69oSQEPjjD+24JSIi4mm2bTMTtbJlg/vus12Nd1B49XHh4e4dtzRxS0RExLO4/jd37AgREVZL8RoKr37ANXRg7lw4dsxuLSIiImKcPg3Tp5v2ww/brcWbKLz6gXr1oGZNiI11z2YUERERu2bPhlOnoHx5aNrUdjXeQ+HVDySfuPXRR5q4JSIi4glcQwYefFA7aqWFvlV+okcPyJULdu6E1attVyMiIuLfNm0yR44c2lErrRRe/URYmAmwoIlbIiIitrn+F991FxQoYLcWb6Pw6kdcQwe+/BKOHrVbi4iIiL+KjoZZs0xbE7XSTuHVj9SpY44LF2DKFNvViIiI+KfPPoMzZ6BSJWjUyHY13kfh1c8kn7iVmGi3FhEREX/jdMKECab98MNmUrWkjcKrn+neHUJDYdcuWLnSdjUiIiL+ZcMG2L4dgoOhd2/b1XgnhVc/kzu3+49l/Hi7tYiIiPgbV69rt26QN6/dWryVwqsfeuQRc/n113DwoN1aRERE/MXx4/D556atiVrpp/Dqh6pWhdtug4QEmDTJdjUiIiL+Ydo0OH8eatSAm26yXY33Unj1UwMGmMuPPjKrD4iIiEjmSUyEceNMWxO1ro/Cq5/q2BEiIiAqCubPt12NiIiIb1uxAv7+20ya7tXLdjXeTeHVT+XIAf37m7brlaCIiIhkjg8/NJd9+5rJ05J+Cq9+7MEHITAQVq2C33+3XY2IiIhv2r8fvvnGtB991G4tvkDh1Y8VLw7t25u2ls0SERHJHBMnmjGvzZqZXbXk+ii8+jnXK8CpU+H0abu1iIiI+JrYWPfKPq7J0nJ9FF79XLNmUKECnDoFM2bYrkZERMS3zJ0LR49CsWLudzvl+ii8+rmAAPemBePGmT2XRUREJGO4JkU/9BBky2a3Fl+h8Cr07Wv2WN6+HX780XY1IiIivmHrVli3zoRW1wo/cv0UXoW8eaFHD9PWslkiIiIZw7U8VpcuZm11yRgKrwK4J27NnQv//mu3FhEREW938iR89plpa6JWxlJ4FQBq14b69c1WsZ98YrsaERER7zZlCpw7B9WqQaNGtqvxLQqvksTV+zphAiQk2K1FRETEWyUmuofhPfooOBx26/E1Cq+S5O67IX9+OHAAFi60XY2IiIh3Wr4c/v4bwsKgVy/b1fgehVdJkjMnPPCAaY8da7cWERERb+Xqde3bF3LntluLL1J4lRQeecSs/bpiBezYYbsaERER77J/P3zzjWm7huNJxlJ4lRRKlYIOHUz7gw/s1iIiIuJtJkwwY16bNYMbb7RdjW9SeJVLPP64uZw2zSz1ISIiItd27hx89JFpa3mszKPwKpdo3BiqVoWzZ+HTT21XIyIi4h1mz4Zjx8y7mO3b267Gdym8yiUcDnfv64cfatksERGRa3E64f33TXvAALMlrGQOhVe5rJ49zbaxu3fDd9/ZrkZERMSzrV0LW7dCcDDcf7/tanybwqtcVkiI+4/P9UpSRERELs/1v7J3b8iXz24tvk7hVa5owACzbNayZfDnn7arERER8Uz798O8eab92GN2a/EHCq9yRaVLQ7t2pq1ls0RERC5v/HgzP6RZMzPhWTKXwqtclesV5JQpEB1ttRQRERGPk3x5LPW6Zg2FV7mqZs2gcmU4c8YEWBEREXGbOROOHzfLY7nerZTMpfAqV+VwuF9JfvCB2TVEREREUi6PNXAgBAbarcdfKLzKNfXqBeHhsGsXLF5suxoRERHP8MMPsG1byhV6JPMpvMo15c7t/qMcO9ZuLSIiIp4i+fJYefParcWfKLxKqgwYYIYQLF4Mf/1luxoRERG79u2D+fNNWxO1spbCq6RK2bLQtq1pa9MCERHxd+PGmXkgt98OVarYrsa/KLxKqg0aZC4nT4YTJ6yWIiIiYs3ZszBpkmk//rjdWvyRwqukWtOmUL16yj9aERERf/PZZ6YTp0wZuPNO29X4H4VXSTWHw937OnYsXLhgtRwREZEs53TCmDGmPWCAlseyQeFV0qR7dyhUCA4ehK++sl2NiIhI1lq2DHbsMCvxPPCA7Wr8k8KrpEnOnPDoo6Y9apTdWkRERLLae++Zy/vvN2ugS9ZTeJU0e+QRyJEDfvoJ1q+3XY2IiEjW2LEDliwxw+g0UcsehVdJs0KFoGdP01bvq4iI+IvRo81lp05mCUmxQ+FV0uXJJ83ll1+ahZpFRER82dGjMH26aQ8ebLcWf6fwKulSrZpZmDkxET74wHY1IiIimWv8eIiNhXr14OabbVfj3xReJd1cva+TJsHp03ZrERERySznz8OHH5r24MFmzKvYo/Aq6da6NVSoANHRZtctERERXzRrFhw5AsWLQ5cutqsRhVdJt4AAeOIJ0x4zBhIS7NYjIiKS0ZxO9+Tkxx+H7Nnt1iMKr3Kd+vaFvHnhn39g4ULb1YiIiGSsFStg+3bIlQv697ddjYDCq1ynXLngwQdN27WEiIiIiK9w9bredx/kyWO1FPl/VsPrDz/8QLt27ShatCgOh4P58+enuL1fv344HI4UR4MGDewUK1c0cKDZ23nVKtiyxXY1IiIiGeOPP+Dbb80ELdcwObHPang9c+YMNWrU4IOrrLXUqlUrDh8+nHR8++23WVihpEbx4tC1q2mPHGm3FhERkYwyZoy57NABypWzW4u4ZbP5yVu3bk3r1q2vep+goCAiIiKyqCJJryFDYPZsc4wYASVK2K5IREQk/f77D6ZONW3X0pDiGTx+zOuqVasoVKgQFSpUoH///hw5cuSq94+NjSUmJibFIZmvTh1o2tSsOOB6pSoiIuKtJkww67vWqQO33mq7GknOo8Nr69at+eyzz1i5ciUjR45k48aNNGvWjNjY2Cs+ZsSIEYSHhycdJdQFmGWGDDGXH31k1n4VERHxRufPu3ePfPJJbUrgaRxOp9NpuwgAh8PBvHnz6Nix4xXvc/jwYUqVKsXs2bPp3LnzZe8TGxubItzGxMRQokQJoqOjCQsLy+iyJRmnE6pWhd9/h7ffhqeftl2RiIhI2k2aZFbSKVHCLAWptV0zX0xMDOHh4anKax7d83qxIkWKUKpUKf7+++8r3icoKIiwsLAUh2QNh8Pd+zpmDMTF2a1HREQkrRIT3ZOPn3xSwdUTeVV4PXbsGAcOHKBIkSK2S5Er6NEDihSBQ4fM5C0RERFv8s03sHMnhIfDAw/YrkYux2p4PX36NFu3bmXr1q0A7Nmzh61bt7J//35Onz7NkCFDWL9+PXv37mXVqlW0a9eOAgUK0KlTJ5tly1UEBZnt8wDefdcMJRAREfEW77xjLh95BEJD7dYil2d1zOuqVato2rTpJdf37duX8ePH07FjR7Zs2cLJkycpUqQITZs25bXXXkvTJKy0jKGQjHHypBkndPo0LF4Md9xhuyIREZFrW7cObrkFcuSAvXvNO4mSNdKS16yu89qkSROulp2XLFmShdVIRsmTx7zVMnq0eQWr8CoiIt7A1evaq5eCqyfzqjGv4j0GDTJbxq5YoS1jRUTE8/31F3z9tWm7Jh+LZ1J4lUxRqhTcfbdpv/uu3VpERESuZeRIM0+jXTuoVMl2NXI1Cq+SaVyvXOfMgf377dYiIiJyJf/+694KVmuUez6FV8k0tWtDs2Zmy9jRo21XIyIicnljx0JsLNSvD40a2a5GrkXhVTKV6xXspElmFQIRERFPcvo0jBtn2s88o61gvYHCq2SqO+4wW8aePg0TJtiuRkREJKVPP4UTJ+CGG6BDB9vVSGoovEqmcjjcva+jR8O5c1bLERERSRIfD++9Z9pPPWVWyRHPp/Aqma57dyhZMuWAeBEREdu++AL27YOCBaFvX9vVSGopvEqmy57dvfLAO++YV7oiIiI2OZ3uTQkGDoTgYLv1SOopvEqWuP9+KFAAdu82r3RFRERsWrLEbKKTKxcMGGC7GkkLhVfJEiEh8MQTpv3mm+YVr4iIiC0jRpjLBx+E/Pnt1iJpo/AqWWbAAMidG7Ztg8WLbVcjIiL+6scf4YcfzLC2wYNtVyNppfAqWSZvXnjoIdN2veIVERHJaq7/QX36QPHidmuRtFN4lSw1eDDkyAFr1phXviIiIllp2zZYtAgCAuDZZ21XI+mh8CpZqmhR80oXzNhXERGRrOT633PXXVC+vN1aJH0UXiXLPf202bxg4ULYvt12NSIi4i/++QfmzDHt//3Pbi2SfgqvkuUqVDCveAHefttuLSIi4j/eeQcSE6FVK6hVy3Y1kl4Kr2KF6xXvrFmwZ4/dWkRExPdFRsLkyab9/PN2a5Hro/AqVtSuDS1bQkICjBxpuxoREfF1o0ZBXBzccgvceqvtauR6KLyKNa7e108+gSNH7NYiIiK+68QJmDDBtJ97zm4tcv0UXsWaJk3gppvg/HkYPdp2NSIi4qs++ABOn4bq1aFNG9vVyPVSeBVrHA73uKMPPjCvjEVERDLSmTMwZoxpP/ec+d8j3k3hVaxq1w6qVYNTp+D9921XIyIivubjj+HYMShXzr3SjXg3hVexKiAAXnjBtEePhpgYq+WIiIgPiY2Fd9817WeegWzZ7NYjGSNDwuvJkycz4mnET3XpAjfeCCdPwrhxtqsRERFfMWUKHDwIxYpB3762q5GMkubw+tZbbzHHtT0FcPfdd5M/f36KFSvGr7/+mqHFiX8IDHSPfR050oxPEhERuR4XLsCIEab9zDMQFGS3Hsk4aQ6vEydOpESJEgAsW7aMZcuW8d1339G6dWuefvrpDC9Q/EP37lC2LPz3H0ycaLsaERHxdtOnw759ULgw9O9vuxrJSGkOr4cPH04KrwsXLuTuu++mZcuWPPPMM2zcuDHDCxT/kC2be+29d94xy2eJiIikR3w8vPGGaT/9NAQH261HMlaaw2vevHk5cOAAAIsXL6Z58+YAOJ1OEhISMrY68St9+kDJkhAVZTYuEBERSY9Zs2D3bihQAB5+2HY1ktHSHF47d+5Mjx49aNGiBceOHaN169YAbN26lRtuuCHDCxT/kSMHPPusab/1ltnGT0REJC0SEuD11037qacgVy679UjGS3N4HTVqFAMHDqRy5cosW7aM3LlzA2Y4waOPPprhBYp/ue8+KFIEDhyAadNsVyMiIt7miy/gr78gXz4YMMB2NZIZHE6n02m7iMwUExNDeHg40dHRhIWF2S5HUmHUKBg82Ezg2rlT6/KJiEjqJCaaLWB37IBXX4UXX7RdkaRWWvJaqsLrggULaN26NdmzZ2fBggVXvW/79u3TVm0mU3j1PmfOQJkycPQoTJ1qxsKKiIhcy5dfml20wsNh717Ik8d2RZJaGR5eAwICiIqKolChQgQEXHmkgcPh8LhJWwqv3unNN83qAxUrmlfQgYG2KxIREU/mdEKtWvDrr6bH9dVXbVckaZGWvJaqMa+JiYkUKlQoqX2lw9OCq3ivRx+FvHnNsIG5c21XIyIinu6bb0xwzZ0bBg2yXY1kpgzZHtbl7NmzGfl04sfCwuCJJ0z71VfN7FEREZHLcTrdPa0DB5rJWuK70hxemzRpwsGDBy+5/qeffqJmzZoZUZMIYMJreDj8/ruZPSoiInI5ixfD5s0QEmIm/IpvS3N4DQsLo3r16syePRswwwiGDRvGbbfd5nGTtcS75clj1ugDeOUV9b6KiMilkve6PvIIFCxotx7JfOlaKmvChAkMGTKE9u3bs3fvXvbv38+UKVOSdtvyJJqw5d1iYqB0aThxAj77DHr0sF2RiIh4ksWLoXVryJkT9uyBiAjbFUl6ZPiErYs9/PDDPPbYY8yePZtNmzbx+eefe2RwFe8XFubufdXYVxERSc7phJdeMu0BAxRc/UWaw+uJEyfo0qUL48ePZ+LEidx99920bNmScePGZUZ9Ijz2mBl8v3On2a9aREQEYNEi2LjRjHV95hnb1UhWSXN4rVq1Kv/++y9btmyhf//+zJgxg08++YQXX3yRO++8MzNqFD8XFgZDhpj2q69CfLzdekRExL7kva6PPQb/v6Kn+IE0h9eHH36YH374gTJlyiRd161bN3799Vfi4uIytDgRl4EDIX9++PtvmDnTdjUiImLb11/Dli1mXVdXB4f4h3RN2PImmrDlO956C/73PyhXDv78E7Jls12RiIjYkJhodtPatg2GDoXXX7ddkVyvDN8e9nLOnj3L/v37L+ltrV69enqeLtMovPqO06ehbFk4ehQ+/RTuvdd2RSIiYsPcudC1qxlWtmePNiXwBWnJa2nuuzp69Cj33nsv33333WVv1xaxklly5zYD8p9+Gl57DXr1guzZbVclIiJZKSEBXn7ZtJ98UsHVH6V5zOugQYM4ceIEGzZsIDg4mMWLFzN16lTKly/PggULMqNGkSSPPGIG5e/ZA9Om2a5GRESy2hdfmJ0X8+SBQYNsVyM2pDm8rly5klGjRlGvXj0CAgIoVaoUvXr14u2332bEiBGZUaNIkly54NlnTfv110FzBEVE/EdCAgwbZtpDhpgAK/4nzeH1zJkzFPr/9Sjy5cvH0aNHAahWrRq//PJLxlYnchkPPwyFC8PevTB1qu1qREQkq8yaZdb8zpcPHn/cdjViS5rDa8WKFdm5cycANWvWZOLEiRw6dIgJEyZQpEiRDC9Q5GIhIfDcc6b92mtw/rzdekREJPPFx8Mrr5j2M89AaKjdesSedI15PXz4MAAvv/wyixcvpmTJkrz//vsMHz48wwsUuZyHHoLixeHAAZg40XY1IiKS2WbMgF27oGBBsxWs+K/rXuf17Nmz/Pnnn5QsWZICBQpkVF0ZRktl+a5Jk+DBB82JbPdusxqBiIj4nrg4uPFGM1n33XfhqadsVyQZLS15Lc09r8n9+OOPBAYGUrt2bY8MruLb+vWDG24w676OGWO7GhERySwff2yCa0SEWXVG/Nt1hdfWrVtz6NChjKpFJE2yZ4dXXzXtd96B48ft1iMiIhnvzBkzvwHgxRfNvAfxb9cVXn18Z1nxAt26QbVqEB1tAqyIiPiWsWMhKgrKlIEHHrBdjXiC6wqvIrYFBMAbb5j2mDHmBCciIr7hxAl46y3TfvVVyJHDbj3iGdIcXvv168cPP/wAwMSJEylcuHCGFyWSFm3bQoMGcO6cO8iKiIj3e+cdOHkSqlSB7t1tVyOeIs3h9dSpU7Rs2ZLy5cuzZ88eTp48mQlliaSewwGuVdomTjSbF4iIiHeLinJPxn3jDQgMtFuPeI40h9cvv/ySQ4cOMXDgQObOnUvp0qVp3bo1c+fO5cKFC5lRo8g1NW0KzZvDhQvuRaxFRMR7vf46nD1r3llr3952NeJJrnud1y1btvDpp5/y8ccfkzt3bnr16sWjjz5K+fLlM6rG66J1Xv3Hzz9D/fpmHOxvv0GlSrYrEhGR9NizBypWNB0SK1eaDgrxbVm2zuvhw4dZunQpS5cuJTAwkDZt2rBjxw4qV67MqFGjruepRdLsppugY0dITISXXrJdjYiIpNfLL5vg2qKFgqtcKs09rxcuXGDBggVMnjyZpUuXUr16dR544AF69uxJ6P9vNDx79mweeeQRTpw4kSlFp4V6Xv3Lb79B9ergdMKmTVCnju2KREQkLZKfxzduhLp1bVckWSEteS1bWp+8SJEiJCYm0r17d37++Wdq1qx5yX3uuOMO8uTJk9anFrluVatCz55mD+znn4clS2xXJCIiafHCCya4dumi4CqXl+ae1+nTp9O1a1dy5syZWTVlKPW8+p/du80e2BcuwLJlZiKXiIh4vvXr4eabNXfBH2XqmNfevXt7TXAV/1S2rHvv62eeMWNgRUTEszmd5h0zgL59FVzlyrTDlvikF16A0FDYsgVmz7ZdjYiIXMuSJbBqldlF6+WXbVcjnkzhVXxSwYLwv/+Z9tChEBtrtx4REbmyhAR4+mnTfuwxKFXKbj3i2RRexWcNGgRFi5odt8aNs12NiIhcybRpZoxrnjzuoQMiV6LwKj4rJMS929brr5v9sUVExLOcPQsvvmjaQ4dCvnx26xHPp/AqPq1fPzPo//hxeOst29WIiMjFRo+GQ4fMUIGBA21XI97Aanj94YcfaNeuHUWLFsXhcDB//vwUtzudToYNG0bRokUJDg6mSZMm7Nixw06x4pWyZYM33zTt0aPh4EGr5YiISDJHj7rP0W+8AVrMSFLDang9c+YMNWrU4IMPPrjs7W+//TbvvfceH3zwARs3biQiIoIWLVpw6tSpLK5UvFm7dnDrrXD+vLaNFRHxJK+9BqdOQe3a0L277WrEW6R5k4LM4nA4mDdvHh07dgRMr2vRokUZNGgQzz77LACxsbEULlyYt956i4ceeihVz6tNCgRgwwZo2NAsfP3rr2YnLhERsefvv6FyZYiPhxUroFkz2xWJTZm6SUFW2bNnD1FRUbRs2TLpuqCgIBo3bsy6deuu+LjY2FhiYmJSHCINGpitBhMT3UtoiYiIPc8/b4Jr69YKrpI2Hhteo6KiAChcuHCK6wsXLpx02+WMGDGC8PDwpKNEiRKZWqd4j+HDITAQFi0yC2GLiIgdGzbA3Lnm3TBNppW08tjw6uJwOFJ87HQ6L7kuueeee47o6Oik48CBA5ldoniJChXANdrk6ae1bayIiA1OJwwZYtr9+kG1albLES/kseE1IiIC4JJe1iNHjlzSG5tcUFAQYWFhKQ4Rl5deMtvGbtoEn31muxoREf/z9dfw448QHOxei1skLTw2vJYpU4aIiAiWLVuWdF1cXByrV6/m5ptvtliZeLPChd27tzz3HJw5Y7ceERF/cuGCe97Bk09C8eJ26xHvZDW8nj59mq1bt7J161bATNLaunUr+/fvx+FwMGjQIIYPH868efP47bff6NevHyEhIfTo0cNm2eLlBg2C0qXNotjvvmu7GhER/zFxIuzcCQUKwP8vJCSSZlaXylq1ahVNmza95Pq+ffsyZcoUnE4nr7zyChMnTuTEiRPUr1+fDz/8kKppWOdIS2XJ5Xz+OXTrZraQ/esvKFbMdkUiIr7t+HEoX95cjh8PDz9suyLxJGnJax6zzmtmUXiVy3E6zcYFP/4IffvClCm2KxIR8W2DBsGYMWad7S1bzA6IIi4+sc6rSGZyOGDUKNOeOhU2b7Zbj4iIL/vzT/jwQ9N+7z0FV7k+Cq/it+rVg169TPvJJ01vrIiIZLwhQ8yGBO3aQYsWtqsRb6fwKn5txAizXMuaNfDVV7arERHxPUuWmM1hsmfXJFnJGAqv4teKFzcbFgA88wzExtqtR0TEl8THw+DBpv3YY2azGJHrpfAqfu/pp6FIEdi9G95/33Y1IiK+46OP4PffIX9+ePFF29WIr1B4Fb+XOzcMH27ar78OR47YrUdExBecOGF2NQR47TXIk8dqOeJDFF5FgD59oHZtiImBl1+2XY2IiPd77TU4dgyqVIH+/W1XI75E4VUECAhwL5310Ufw66926xER8WZ//QVjx5r2qFFaGksylsKryP+77Taz61ZioplYoKWzRETSx7U0Vtu2WhpLMp7Cq0gy775rtoxdswZmzbJdjYiI91myBL75xvS2amksyQwKryLJFC8OQ4ea9tNPw+nTdusREfEmsbHmnSswlxUr2q1HfJPCq8hFBg+GsmUhMtKsPiAiIqkzejT8/TcULgzDhtmuRnyVwqvIRXLmNCdgMHtw//WX1XJERLzCwYNmhQGAd96BsDC79YjvUngVuYy2baF1a7hwAQYN0uQtEZFrGTIEzpyBRo2gVy/b1YgvU3gVuQyHw/S+Zs8O330HCxfarkhExHN9/z3MmWOWHRw71pxDRTKLwqvIFVSo4N6Te9AgOH/eajkiIh7pwgUYONC0H3kEata0Wo74AYVXkat44QUoWhR279aSLyIil/PBB/D771CggHvMq0hmUngVuYrcuc3EA4Dhw2H/frv1iIh4kqgo95bab74JefParUf8g8KryDV07w633grnzpkJCSIiYjzzDJw6BfXqwb332q5G/IXCq8g1OBxmAkJAAHzxBSxdarsiERH71q6F6dPNOfLDD805UiQr6FdNJBVq1HDvGvPoo6YXVkTEXyUkuCdp3X+/6XkVySoKryKp9OqrZvLWP/+YsV0iIv7qww/h11/NGNcRI2xXI/5G4VUklcLCYMwY037zTe28JSL+6eBBGDrUtIcPN6sMiGQlhVeRNOjSBVq1grg4M3xAO2+JiL954gk4fRoaNoQHH7RdjfgjhVeRNHA4zJqGOXPCihUwa5btikREss7ChfDVVxAYCBMmaJKW2KFfO5E0KlfObF4A8OSTcPKk1XJERLLEmTMwYIBpDx4M1avbrUf8l8KrSDoMGQIVK8KRI+6xXyIivuyVV8xGLaVKuTcmELFB4VUkHYKCYPx40x4/Hn7+2W49IiKZads2eO890/7gA8iVy2494t8UXkXSqWlT6N3bTNp6+GGIj7ddkYhIxktMhIceMmu7du4Mbdvarkj8ncKryHV4913Ikwe2bIFx42xXIyKS8SZNgg0bIHdu93KBIjYpvIpch0KF3BsWDB0KBw7YrUdEJCP9+y/873+m/frrULy43XpEQOFV5Lr17w8332zWPXzkEa39KiK+Y/Bgs6JK7dru7WBFbFN4FblOAQHw8ceQIwcsWgSzZ9uuSETk+i1dCjNnmnPcRx+ZtV1FPIHCq0gGqFTJvfbr44/Df//ZrUdE5HqcPu3ePWvgQKhTx249IskpvIpkkGefhapVTXB98knb1YiIpN8LL8C+fWZN1zfesF2NSEoKryIZJEcO+OQT8xbbjBnw3Xe2KxIRSbv16+H99037o4/MKgMinkThVSQD3XQTPPGEaT/0EJw6ZbceEZG0iI2F++83E0/79oWWLW1XJHIphVeRDPbaa1CmjFk26/nnbVcjIpJ6b7wBf/xhlgF07agl4mkUXkUyWK5c5q02gA8/hHXr7NYjIpIa27bBiBGm/eGHkC+f3XpErkThVSQTNG8O/fqZt94eeMC8FSci4qni481wgfh46NQJunSxXZHIlSm8imSSkSOhcGHzFpxm64qIJxszBjZtgvBw+OADcDhsVyRyZQqvIpkkXz4YO9a0R4yArVutliMicll//QUvvmjaI0dC0aJ26xG5FoVXkUx0113QubN5K65vX4iLs12RiIhbQoIZ4nTunBnudN99tisSuTaFV5FM5HDA+PFQoICZDPH667YrEhFxGzXKrOsaGmrWqdZwAfEGCq8imaxQIRg3zrSHD4fNm+3WIyICZjy+a1vrUaOgZEm79YiklsKrSBbo2hXuvtu8Rde3r1YfEBG74uPNcIHYWGjdWsMFxLsovIpkkQ8/NL2wO3bAK6/YrkZE/Nm778LPP5vVBSZN0nAB8S4KryJZpEABmDDBtN96y/zjEBHJar/9Bi+/bNrvvw/FitmtRyStFF5FslCnTtCzJyQmmuED58/brkhE/MmFC+6VT9q1g969bVckknYKryJZ7P33oUgR+PNP92QJEZGsMGIE/PIL5M0LEydquIB4J4VXkSyWL58ZYwbw3nuwapXVckTET/z8M7z6qml/8IF5ES3ijRReRSy4807o3x+cTujTB06etF2RiPiyM2egVy+z4sk990D37rYrEkk/hVcRS957D264AQ4cgIEDbVcjIr5syBD4+28oXtysO63hAuLNFF5FLMmdG6ZPh8BA+OwzmD3bdkUi4osWLXKvdDJlihnvKuLNFF5FLGrQAIYONe1HHjG9sCIiGeXIEfcGBE8+CbffbrcekYyg8Cpi2QsvQL16Ztxrv35mGS0RkevldJqx9UeOQNWqZntqEV+g8CpiWfbsMGMGhITAypUwZoztikTEF3zyCSxYADlymHNMzpy2KxLJGAqvIh6gQgUzgQvguedg2za79YiId9u1CwYNMu3XX4caNayWI5KhFF5FPMSDD0LbthAba5ayOXvWdkUi4o3i4sw55MwZaNIEBg+2XZFIxlJ4FfEQDgd8+ilERMAff5jJFSIiafX887B5s9kQxbWiiYgvUXgV8SAFC5qxaQ4HfPQRfPGF7YpExJt89x2MHGnan35q1nUV8TUKryIe5vbb4X//M+3+/WHfPrv1iIh3iIqCvn1Ne+BA6NDBbj0imUXhVcQDvfKKWQM2Ohp69ID4eNsViYgnS0yE3r3h6FGoXh3eecd2RSKZR+FVxANlzw4zZ0JYGKxbZ8KsiMiVvPsuLF8OwcFmtz4tiyW+TOFVxEOVKWPGvQK88QZ8/73dekTEM/30k3unvvffh0qV7NYjktkUXkU8WLducP/9Zqecnj3NTjkiIi4nTkD37mZo0d13m/OFiK9TeBXxcGPGQOXKcPiwGf+akGC7IhHxBE4n3Hsv7NkDpUvDxIlmpRIRX6fwKuLhcuUyS2aFhMCKFfDqq7YrEhFP8N578PXXZvvXuXMhTx7bFYlkDYVXES9QubLpVQF47TVYutRuPSJi148/wrPPmvbo0VCnjtVyRLKUwquIl+jVy2wh6xr/evCg7YpExIajR814+IQEsw3sww/brkgka3l0eB02bBgOhyPFERERYbssEWvGjIFateC//8w/rwsXbFckIlkpIcG8kD10CCpWNCuSaJyr+BuPDq8AVapU4fDhw0nH9u3bbZckYk3OnGb8a3i4Wf/1uedsVyQiWemNN8ywoeBgM841NNR2RSJZz+PDa7Zs2YiIiEg6ChYsaLskEavKlYPJk0175EiYN89uPSKSNZYvh2HDTHv8eKha1Wo5ItZ4fHj9+++/KVq0KGXKlOGee+5h9+7dV71/bGwsMTExKQ4RX9OpEzz5pGn37Qt//mm3HhHJXHv3mvGtTqdZy7VvX9sVidjj0eG1fv36TJs2jSVLljBp0iSioqK4+eabOXbs2BUfM2LECMLDw5OOEiVKZGHFIlnnrbfgttvg1Cno2BH0Ok3EN507B507w7FjULcufPCB7YpE7HI4nU6n7SJS68yZM5QrV45nnnmGwYMHX/Y+sbGxxMbGJn0cExNDiRIliI6OJiwsLKtKFckS//5rlsg5dMgE2C+/hACPfkkqImnhdEKfPjBjBhQoAJs3Q8mStqsSyXgxMTGEh4enKq951b+5XLlyUa1aNf7+++8r3icoKIiwsLAUh4ivKlwYvvrKLFI+fz4MH267IhHJSGPHmuAaGAiff67gKgJeFl5jY2P5448/KFKkiO1SRDzGTTfBuHGm/dJL8O23dusRkYyxejW43mR8911o2tRuPSKewqPD65AhQ1i9ejV79uzhp59+4q677iImJoa+GqkuksL995uFyp1O6NEDdu2yXZGIXI8DB6BrV7Oua8+e8MQTtisS8RweHV4PHjxI9+7dqVixIp07dyZHjhxs2LCBUqVK2S5NxOOMGQM33wzR0WY1gtOnbVckIulx/jx06WJ20qpZUxsRiFzMqyZspUdaBgCLeLvISDOBKyoKOnQw42E1gUvEezid0Ls3fPYZ5MsHmzZBmTK2qxLJfD47YUtErq5oUbNpQVAQfP01DB1quyIRSYsRI0xwzZbN7Kan4CpyKYVXER/ToAF88olpv/kmTJ9utx4RSZ2vvnK/4Bw7Fpo1s1uPiKdSeBXxQT17wvPPm/YDD8C6dXbrEZGr27LFDBcAeOwxMwFTRC5P4VXER732mpm4FRdnLvfts12RiFxOVBS0bw9nz0LLlvDee7YrEvFsCq8iPiogAKZNgxo14MgR889RKxCIeJbz583ueAcPQsWKMGeOGe8qIlem8Criw3LnhgULzE5c27aZNWATEmxXJSJgVha47z746SfImxe++Qby5LFdlYjnU3gV8XElS5qtY4OCzD/HQYPMP00RseuFF2DWLNPTOnculC9vuyIR76DwKuIHGjRwrzrwwQcwapTdekT83UcfwfDh7rZWFhBJPYVXET/RtavZHx3gqafMGpIikvW+/RYefdS0X34Z7r3Xbj0i3kbhVcSPDB4MAweadu/e8OOPdusR8Te//AJ3323Gnvfta8KriKSNwquIH3E4YPRos/JAbKy5/Osv21WJ+Id9++DOO+HMGWje3AwXcDhsVyXifRReRfxMYKCZJHLTTXD8OLRubZbSEpHMc+IEtGlj1nStVs1M0MqRw3ZVIt5J4VXED4WEmJUHypaF3bvNP9WYGNtVifims2fNuxy//w7Fipkxr+HhtqsS8V4KryJ+qlAh+O47KFgQNm82C6WfP2+7KhHfcuGCGeO6dq0JrN9+C8WL265KxLspvIr4sQoVTIANDYXvv4fu3SE+3nZVIr4hMdGsJLBoEQQHw8KFUL267apEvJ/Cq4ifq1PH7MIVFGQ2M3jwQW1iIHK9nE6zIchnn7k3IWjUyHZVIr5B4VVEaNIEZs+GgACYPBmefdZ2RSLe7fXXYexY054yxYwrF5GMofAqIoAZ8/rxx6b9zjvw9ttWyxHxWuPGwUsvmfaYMdCzp916RHyNwquIJLn3XvcuXM8+a/4Ji0jqTZvm3gjkpZfg8cft1iPiixReRSSFp56C55837QED3L2xInJ1s2ebF4BOp/nbGTbMdkUivknhVUQu8frr8OSTpv3gg6Y3SUSu7MsvoVcvs8LAAw/A++9r9yyRzKLwKiKXcDhg5EjTe+R0mt6kOXNsVyXimb75Bu65BxISoG9fmDjRTH4UkcyhPy8RuSyHw/QePfCA6U3q2RO++sp2VSKeZfFiuOsusz5y9+7wyScKriKZTX9iInJFAQGmF6lPH9OrdM89ppdJRGDlSujUCeLioEsXM7wmMNB2VSK+T+FVRK4qIAA+/dT0Kl24YP5Jz59vuyoRu5YsgTvvNFsqt2sHM2eazQhEJPMpvIrINQUGml6lu+82AfauuzQGVvzXwoXQvr0Jrm3bwhdfQI4ctqsS8R8KryKSKtmyma0ue/c2Qwh69IDp021XJZK1vvzSPVSgc2fzcVCQ7apE/IvCq4ikWrZsZvtY1ySuvn21Dqz4j1mzoFs39+SsOXPU4ypig8KriKRJYKCZxOVaRqt/f/jwQ9tViWSuKVPMihuu5bCmT9cYVxFbFF5FJM0CAmDsWBg82Hw8cCC89ZYJsyK+5sMP3Ttn9e9vJjBqVQERexReRSRdHA54910YOtR8/L//wZAhZjiBiC9wOuHll82LM4DHHtMGBCKeQH+CIpJuDofZSvbdd83H770H/fqZFQlEvFlCAjz6KLz6qvl42DAYM0Zbvop4AoVXEbluTz0FU6eat1KnT4eOHeHMGdtViaRPbKzZkGPCBBNWx40zPbAKriKeQeFVRDJEnz7w9dcQHAzffgstWsDx47arEkmbmBho0wbmzjUrCcyZA488YrsqEUlO4VVEMsydd8Ly5ZA3L6xfD7feCvv22a5KJHUiI6FpU7Pta+7c5kVY1662qxKRiym8ikiGuvlmWLMGihWD33+H+vXh559tVyVydb/+an5Xf/kFChaEVavg9tttVyUil6PwKiIZrkoV0/NavTr8+y80bmx2IhLxRN9+C40awcGDULGi+d2tU8d2VSJyJQqvIpIpSpSAtWvN+MHz5+Guu+Dtt7UWrHiWDz+Edu3g9GkzZGD9eihXznZVInI1Cq8ikmlCQ80krsceMx8/+6xZ5F1LaYltCQnwxBNmDdfERLjvPli82IzXFhHPpvAqIpkqWzZ4/31zBATAJ5/AHXfA0aO2KxN/dfIktG9vficBRoyAjz82qwuIiOdTeBWRLPHYY7BggZnF/f33ULeumRwjkpV27IB69cw415w54fPPze5wWsNVxHsovIpIlrnzTvjpJyhfHvbvh1tuMZsaiGSFuXPNigK7dkGpUvDjj1oKS8QbKbyKSJaqXNksndW2rZnI1aePGXuocbCSWRIS4LnnTFA9cwaaNYNNm6B2bduViUh6KLyKSJbLk8dM5HrpJfPx++9D8+YQFWW1LPFBx46ZHv833zQfP/UULFkCBQrYrUtE0k/hVUSsCAiAV16B+fPNqgQ//AA1a5odukQywtq15ndqyRKzbfHMmfDuu2YSoYh4L4VXEbGqQwczjKBqVbOhQcuW8MILEB9vuzLxVgkJ8MYb0KSJ2XigfHmzfmv37rYrE5GMoPAqItbdeKMJsA8+aDYxeOMNs2D8gQO2KxNvExUFrVqZF0AJCdCrF2zeDDVq2K5MRDKKwquIeITgYJg4EWbPNsMIXG/5LlhguzLxFsuWmZC6fDmEhMDkyTBtmvl9EhHfofAqIh6lWzfYssXsLX/8uBlW0L8/nDpluzLxVGfPwuOPmyEnR46YISibNkG/flq/VcQXKbyKiMcpVw7WrTMzwx0Os/tR9eqwerXtysTTbNgAtWrB2LHm40ceMUNQKlWyW5eIZB6FVxHxSDlymJnh338PpUvD3r1mHOzgwXDunO3qxLa4OBg61Gx08ddfUKwYLF4M48aZISgi4rsUXkXEozVuDNu2maEDTieMGmUWl//pJ9uViS1bt5otXocPh8REMylr+3a44w7blYlIVlB4FRGPFxoKH30EixZBkSLw55/QsCE89hhER9uuTrLKmTPw9NNQt655QVOgAHz5pdliOG9e29WJSFZReBURr9GmDfz2G/TubXphP/jAbDf75ZfmY/FdixaZn/W775olsO66y/wudO5suzIRyWoKryLiVfLlM8sfrVhhFp+PjDRBpn172LfPdnWS0SIjoWtXaNsW9u+HUqVg4UL44gsoXNh2dSJig8KriHilZs3MW8cvvQTZs5tAU7kyvP66JnT5gthYeOcds4HF3LkQGGiGDOzYAXfeabs6EbHJ4XT69pttMTExhIeHEx0dTVhYWNZ8UqcTTp+GkyfhxAlz6WqfOgXnz5szs+vS1b5wwWz4frkjMNCsup0r16VH7tyQP78ZAFagAAQFZc3XKeIh/vgDHn4YfvjBfFyiBLz1Ftxzj9b59DZOJ8ybZ4Lq7t3muptuMmOe07RLlus8fOwYxMRc/jh92px3L3ckJEC2bOaVUfLLbNnMUhihoe4jLMx9GRYGBQuaj/XLJ5JqaclrCq8ZrXZt0x2UkJD5n+tKcud2B9kCBcwaMiVKQPHi5tLV1rYz4kOcTpgzB555xr2tbIMGZnWCBg3s1iap88svZik013q+RYqYFQX69DGv4ZOcOWPGiOzbZ9ZQO3QI/v3XHEeOuNs2u+Bz5oRChdxH4cLmskQJM/bBdWRVp4qIh1N4TSbLw2utWmYdFzCv1PPmhTx53JehoWYRwqAg95Ezp7nMnt38B05MdF+6jvh4s43MmTOXHqdOmd6F//5LW2gODzerwZcvf+mRP796DcQrnTsHI0fCm2+aPw8wPbCvvAIVKtitTS5vzx549VWYOtWc+nLmhBcfPcag1jsJ2f8n7NwJ//zjDqv//Zf6J8+Z05zrXL2iyY9cuUwvavbsKXtYs2c373bFx6c8Llwwl7Gxptc2Jsacf0+dcrdPnjTn6tTKk8cdZMuXh4oV3UehQjoPi99QeE0my8Pr3r3mZJgnjwmpWXnicTrNukH//ec+jhyBgwfNceCA+/Ja6wvlyWMGEFatCtWquS/z58+SL0XkekVGwgsvwJQp5k8jIMD04L34IpQta7s6ATMBa8wLR/nts1+pkriNyvzOrQX+5IbEnQQev0ZADQszu1eUKmV6MwsXvvyRK1eWfC0pnDkDR4+6e4JdvcFRUeaL3r/fBPHjx6/+POHh5hXXjTeac3D16uYoUkShVnyOwmsyVsa8eoNTp8wJdNcu+PvvlMfBg1d+XJEi5iRaq5ZZbLFuXfMPRCdS8VBbtphJXQsXmo+zZTN73r/wgsk9kkUSE81WWFu2cGrtr+xf+Ct59/9KUQ5f+TElSrh7IcuXd4fV0qXNC2xv5zoP799vup//+sv0Mu/caTpCrvTvuUABE2Jr1DCXdeqYzobAwCwtXyQjKbwmo/CaDufOmVD722/m2L7dXO7Zc/n758vnDrKuo3hxBVrxKD//bELskiXm4+zZoW9fM8ayUiW7tfmkw4fNN/2nn8zlxo3mrfXLOFfsBoLrVzcvjG+80RwVKtjpNfUU58+b8/DOnWZXju3bzXyKnTvNC4GL5cplQmy9emaG2003maCv87B4CYXXZBReM9CpU/D77+YEunkzbNpk2hcuXHrfwoXNpuOuo1YtM5xCxLIff4SXXzbrxLq0bQtDhsBtt+l/fbrExppw+uOPJqj+/PNl38E5SzBbqcmv1OBMuRo0HVSDOv2qmUmmkjrnzrnPw7/+auZY/PKLOT9frEABE2Lr14dGjcylP78gEI+m8JqMwmsmi401PQKbNrmP3367dOJYcLA5ibrC7M03+8bbfuK1fvzR7Nb09dfud2fr1oWnnoIuXUzPrFzBqVOwfj2sWWPWJ/vpJ3MuSMYZEEB08Sr8GHcTX0fdxE/UZwdVaNEqG08/DU2b6oVChklMND2yrhcOP/9sgu3FHQvZspkVcW691YTZRo1MwBXxAAqvySi8WnD2rOkJWLvWJIR16y6dmOBwmPFaTZua1eZvvdVMThDJYn/9ZZbTmjLFvFML5o2D++6D/v2hTBmr5XmG//4zf8+usLply6UvUAsWhFtvJbpyA+YdvIk3FtdhV5TpUc2WDbp3N73b1atbqN8fxcaaAPvzz+YcvGbN5eczVKpkQmyTJuZcHBGR5aWKgMJrCgqvHsDVK/Djj+ZYu9aM5UouIMCM12rWzATaRo309pZkqaNHYdw4mDDBTAoH8xqrRQsTZNu1M/uE+IW4ONOzumSJOX755dL7lC5tXnTeeiux9W9jwZ8VmDLVwZIl7lxbuLB5AfDQQ2YYvFi2b5/7RcjatWa7sotVrgy3327OxU2a6B0yyTIKr8kovHqoqChYtQq+/94cf/+d8vbs2c0wg6ZNTXpo2FDv40qWuHABvvnGhNhly9zXh4aa4QQ9e5pfS5+b2L17tzusrlhh1jFNrnJlE1Zvuw1uvZWEoiVYu9ZsDDF7ttlA0KVRIxgwADp31lB3j3bsmOlQ+OEHcx7esiXlCgcBAWaYQbNmJtDecos6FSTTKLwmo/DqJQ4eNCfPlSvN5b59KW8PDTUn0JYt4Y47zOYKIpnsn3/g00/hs89S/koWKgTt20OnTuZ/ulfuyHz6tPlbcwXWi98NKVjQ/ffWsiUULkx8vOm0++IL+Oors3SpS/HiZh3dvn21GYTXOnbMbG+2YoU5F//5Z8rbs2c3r0zuuANatTJjQDRwWTKIwmsyCq9eas8ec/JcscJ0f128o065cu5/rE2baotFyVSJiWbY4IwZ8PnnKXsZQ0PN//E77jBvEpQsaa/Oq3I6zRhIV1hduzblhJ5s2cxEyjvuMEetWhAQQFQULF4M335r/hRPnnQ/JE8e6NjRh3uj/d2hQ+YFzooV5nDtu+wSEWHOw61amV9+Tf6S66DwmozCqw9ITDRvZy1dav7p/vij2aLRJVs2M6zA1UNUp85FG6GLZJy4ONM5NW8ezJ9vljNNrmJF83+8USPzLqvVsZ5Hj5rEuWSJ+ftxDeZ1KVPGnbz//0Xgv/+a3tXVq827ydu2pXxI/vzQoQN07WreDNGwAD/hdJre+SVLzKuZ779PuQ2uw2GW63C9+GnQwJybRVLJ58LruHHjeOeddzh8+DBVqlRh9OjR3Hrrral6rMKrDzp1yoyXvdLbnfnzu3sDWrbU7FnJNImJZjL34sUmG/7006Xrx5csaUJsnTpQs6ZZZCPTOqguXIANG9wB45dfUo5hzJXLhNT/DxgxhW5gy1YHmza5l26+ePg5mEzSujW0aWPWwFcPqxAbazoSFi82v28Xv8oJDzdjalwvjjz2LQnxFD4VXufMmUPv3r0ZN24ct9xyCxMnTuTjjz/m999/p2Qq/hgUXv3A7t3uXtkVKy5drLtWLXMCbdVKE78kU5086R62/eOP5l36y22GVLy4WaGofHlz3HCD6QQtWtS8FZ+mYYR79rhfyK1ceckuVglVa3C83h3sLn8HW0Ju4fd/gvjjDzOc8Uo7QVevbuZlNW5sLgsVSkM94p8iI93n4aVLL10esVIl93n4ttsgZ047dYrH8qnwWr9+fWrXrs348eOTrqtUqRIdO3ZkxIgR13y8wqufuXDBdH8tXmyOzZtT3h4aCs2buyccaHN7yUSnTplfx/Xr3Zsh/fPP1R+TM6cJsYULm84r1xEWZl535Uw4ww0HV3HD7iWU/XsJBY79leLx0dkLsCG0BcuztWL+mRbsOlPkqp+vZEnTK1ynjulhrVfP7Pgskm4JCebc6+qV3bAh5au44GCzDFfr1uY8fMMNmvglvhNe4+LiCAkJ4YsvvqBTp05J1z/xxBNs3bqV1atXX/KY2NhYYpPt9BITE0OJEiUUXv3VkSOmF8B1Er144teNN6bsDQgOtlOn+I2YGLMp3c6d5i36XbvM5f79KSeCuTmpxnbuYAl3sIRbWUMQcUm3xhPIOm7+/1vv4Bdq4yTlmO/8+aFECRNUK1Y0v/aVKpm2gqpkuhMnzLti331nzsWRkSlvL1vWfR5u2lTbBfspnwmvkZGRFCtWjB9//JGbb7456frhw4czdepUdu7cecljhg0bxiuvvHLJ9QqvQmKiGQPo6pXdsCHlLkE5c5reANdJtEIF9QZIljp3zkwAO/rnMRzLl5Hv58VEbF9K7piUs8L+Cy3NjmJ38GepO9hbthmEhxMUZN5YyJ/fBNJ8+cxqV8WLa2lO8SBOp9lC3HUeXrMm5aoXOXKY9YRd5+EqVXQe9hM+F17XrVtHw4YNk65/4403mD59On9evAYd6nmVNDh50vQGuE6iFw8ALF3afQJt1swkA5HMEB/vnmi1ZImZOZX81BwSYl5YuYa7lC+vf+jiG06fNmO1Fy82PbN796a8vVgx93m4eXPt+OXDfCa8pmfYwMU05lVSxemE3393B9kffjBrIrlky2amjLtOojVqKDxI+jmdZvDrsmVmWMtlJlpRrZp7pnajRl66E4JIGjidZgyN6zz8/fdw/rz79sBAM+nWdR7+/7WIxTf4THgFM2GrTp06jBs3Lum6ypUr06FDB03Yksxz5ox7Oa7Fiy9dPygiwt0L1qKFea9W5GpOnDAh1RVY9+xJeXv+/OZ3ybVecdGiduoU8RTnzpmOBFeYvfjd1oIF3efhli3Nx+K1fCq8upbKmjBhAg0bNuSjjz5i0qRJ7Nixg1KpmCmu8CoZ4p9/3EF25UoTbl0cDrjpJvdJtG5dLccl7jVXXWF148aUM66zZze9+S1amH+8tWppAVWRq9m7130eXr7cDDlwcTigdm2ztmyzZubdCg329io+FV7BbFLw9ttvc/jwYapWrcqoUaO47bbbUvVYhVfJcMkX51682EwdTy53bnPibNrUHLVqaacZfxAfbyYErlpljjVrUv5zBTPFv2VLE1gbN9asapH0iosza9C5VjD49deUt2fPbnb5atbMBNr69bUdnIfzufB6PRReJdMdOuRejmv58ksX5w4LM8twNWliwmyNGuph8wXx8Wbb4uRh9eINMlxDAVyB1epesSI+LDLSvCu2cqWZiLt/f8rbQ0JMp0KzZuZcXLu23iHzMAqvySi8SpZKTDQ9sd9/b47VqyE6OuV98uQxYfaWW9z7hmq3Gc93/rxZeH3dOvNzXbPm0klWefKYHtUmTcxRvbomlIhkNafT7LzoCrMrV5o1v5MLCTG9sbfeakJtgwZaUcYyhddkFF7FqoQEs62SK8xerncuRw4TYG++2Ry33GK2VxK7IiNNUF23zrw9uXlzyvUowWx9dXFYVa+6iGdxrSbj6pVds+bSd8gCAqBmTRNkGzUywbZECa0qk4UUXpNReBWPEh9vQtCaNSYU/fjjpT0CYHacuekmM/mrTh0zbjY8POvr9RfR0eZFxi+/mIlV69bBvn2X3q9QIfMCwzWmWUNARLxPYqJZuWDtWnMuXrv20vVlwXQi1KtnjptuMpdaWSbTKLwmo/AqHs319pYryK5bZ3afudyfZfny7k3o69QxY7YUaNPu+HETUl3H5s1mj9aLBQSYntSGDd294mXKqCdGxBcdPGhC7Nq15ly8fXvKHRhdypQxQbZOHXN+qF7dLJ2o88J1U3hNRuFVvM7Jk/DTT2aXpc2bzXHx5AOX4sWhalWzhaLrsnJlLREDZnjG77+7jx07zHGl72XJku4XBQ0bmn9QGgMn4p/OnTPvxmzcCD//bC7/+uvy982f3x1kq1c35+GKFbUbWBopvCaj8Co+4ehRdy/h5s0m2F4phDkcUKoU3HBDyqNcOTMcISQka2vPTKdPm57r3bvNWryu448/4MCBKz+uXDkTUmvXdg/LKFAg6+oWEe9z8qQ5//78s1maa9s22Lkz5frNyRUsaEJshQrmqFjRnHtKlTKr0EgKCq/JKLyKzzpxwvQo/vabu1fxt98uP4Y2uSJFzESEYsVMz63rsnhxs6tT/vymx8DmLHmn04xDjYoyS5FFRprD1T50yOxQ9e+/V3+eIkVMT3Tlyu5e6apVIW/erPk6RMS3nTtnXixv2+Y+/vjDnKeuJk8e825PyZImzJYsac7BhQq5jwIF7K8RHheXZevjKrwmo/AqfufoUTMZ4Z9/zFjO5MfFy3ZdSUCACXj58pkwmz+/+ThXLtNzm/wIDjaHK+y6xn45HOZwOs3GDufPmxP9uXMp2ydPmnGoJ06Yy+PHzXWXG292OXnzmt4M11G2LNx4o9kQIF++tH73RESu36lTZlvxv/4yvbOuyz17Ll3p4Gry5TNBNn9+M4wp+ZE7t7nMlcuE3GzZzATS5O2AALNKSlycuUzePn/eLPcXHe2+dLVPnoRjx0xHx86dmfZtSk7hNRmFV5H/53Sak+bu3abn8tAhM0kh+WVk5KW7QtkUFmZ6hosWNUfydunSJqiqF1VEvMmpU2ZY0/79ZlWT/fvNceiQ6Xw4cgT+++/KwxGyUv78ppYskJa8pj0rRfyFw+HuRa1X78r3i401vaDHjrkPV4/o2bOmt/Ts2ZTtc+dMOHa9Fk7eBggKMhsxBAdfepknj7uXN18+dztvXnO7iIgvCQ11D2e6koQEc851hdljx0zoPXXKdDC42qdOmXNwQoJZijE+PmU7MdG87Z89uzmSt4OCTAdBeLj7Mnm7QAGPXRpM4VVEUgoKMku/RETYrkRExD8FBpoJXwULXj3k+intWygiIiIiXkPhVURERES8hsKriIiIiHgNhVcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeBURERERr6HwKiIiIiJeQ+FVRERERLyGwquIiIiIeA2FVxERERHxGgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvEY22wVkNqfTCUBMTIzlSkRERETkclw5zZXbrsbnw+upU6cAKFGihOVKRERERORqTp06RXh4+FXv43CmJuJ6scTERCIjIwkNDcXhcNguxyfExMRQokQJDhw4QFhYmO1yJI308/N++hl6P/0MvZt+fhnP6XRy6tQpihYtSkDA1Ue1+nzPa0BAAMWLF7ddhk8KCwvTH60X08/P++ln6P30M/Ru+vllrGv1uLpowpaIiIiIeA2FVxERERHxGgqvkmZBQUG8/PLLBAUF2S5F0kE/P++nn6H308/Qu+nnZ5fPT9gSEREREd+hnlcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeJUMERsbS82aNXE4HGzdutV2OZJKe/fu5f7776dMmTIEBwdTrlw5Xn75ZeLi4myXJlcwbtw4ypQpQ86cOalTpw5r1qyxXZKk0ogRI6hXrx6hoaEUKlSIjh07snPnTttlyXUYMWIEDoeDQYMG2S7Fryi8SoZ45plnKFq0qO0yJI3+/PNPEhMTmThxIjt27GDUqFFMmDCB559/3nZpchlz5sxh0KBBDB06lC1btnDrrbfSunVr9u/fb7s0SYXVq1czYMAANmzYwLJly4iPj6dly5acOXPGdmmSDhs3buSjjz6ievXqtkvxO1oqS67bd999x+DBg/nyyy+pUqUKW7ZsoWbNmrbLknR65513GD9+PLt377Zdilykfv361K5dm/HjxyddV6lSJTp27MiIESMsVibpcfToUQoVKsTq1au57bbbbJcjaXD69Glq167NuHHjeP3116lZsyajR4+2XZbfUM+rXJd///2X/v37M336dEJCQmyXIxkgOjqafPny2S5DLhIXF8fmzZtp2bJliutbtmzJunXrLFUl1yM6OhpAf29eaMCAAdx55500b97cdil+KZvtAsR7OZ1O+vXrx8MPP0zdunXZu3ev7ZLkOv3zzz+MHTuWkSNH2i5FLvLff/+RkJBA4cKFU1xfuHBhoqKiLFUl6eV0Ohk8eDCNGjWiatWqtsuRNJg9eza//PILGzdutF2K31LPq1xi2LBhOByOqx6bNm1i7NixxMTE8Nxzz9kuWS6S2p9hcpGRkbRq1YquXbvywAMPWKpcrsXhcKT42Ol0XnKdeL6BAweybds2Zs2aZbsUSYMDBw7wxBNPMGPGDHLmzGm7HL+lMa9yif/++4///vvvqvcpXbo099xzD998802Kf5wJCQkEBgbSs2dPpk6dmtmlyhWk9mfoOvlGRkbStGlT6tevz5QpUwgI0OtaTxMXF0dISAhffPEFnTp1Srr+iSeeYOvWraxevdpidZIWjz32GPPnz+eHH36gTJkytsuRNJg/fz6dOnUiMDAw6bqEhAQcDgcBAQHExsamuE0yh8KrpNv+/fuJiYlJ+jgyMpI77riDuXPnUr9+fYoXL26xOkmtQ4cO0bRpU+rUqcOMGTN04vVg9evXp06dOowbNy7pusqVK9OhQwdN2PICTqeTxx57jHnz5rFq1SrKly9vuyRJo1OnTrFv374U1917773ceOONPPvssxoCkkU05lXSrWTJkik+zp07NwDlypVTcPUSkZGRNGnShJIlS/Luu+9y9OjRpNsiIiIsViaXM3jwYHr37k3dunVp2LAhH330Efv37+fhhx+2XZqkwoABA5g5cyZff/01oaGhSWOVw8PDCQ4OtlydpEZoaOglATVXrlzkz59fwTULKbyK+LGlS5eya9cudu3adckLDr0p43m6devGsWPHePXVVzl8+DBVq1bl22+/pVSpUrZLk1RwLXHWpEmTFNdPnjyZfv36ZX1BIl5KwwZERERExGtoVoaIiIiIeA2FVxERERHxGgqvIiIiIuI1FF5FRERExGsovIqIiIiI11B4FRERERGvofAqIiIiIl5D4VVEREREvIbCq4iID2vSpAmDBg2yXYaISIbRDlsiIj7s+PHjZM+endDQUNuliIhkCIVXEREREfEaGjYgIpIFjh49SkREBMOHD0+67qeffiJHjhwsXbr0so/ZuHEjLVq0oECBAoSHh9O4cWN++eWXpNtXrVpFjhw5WLNmTdJ1I0eOpECBAhw+fBi4dNjAuHHjKF++PDlz5qRw4cLcddddGfyViohkLoVXEZEsULBgQT799FOGDRvGpk2bOH36NL169eLRRx+lZcuWl33MqVOn6Nu3L2vWrGHDhg2UL1+eNm3acOrUKcAdTHv37k10dDS//vorQ4cOZdKkSRQpUuSS59u0aROPP/44r776Kjt37mTx4sXcdtttmfp1i4hkNA0bEBHJQgMGDGD58uXUq1ePX3/9lY0bN5IzZ85UPTYhIYG8efMyc+ZM2rZtC0BcXBwNGjSgfPny7Nixg4YNGzJp0qSkxzRp0oSaNWsyevRovvrqK+69914OHjyoMbAi4rXU8yoikoXeffdd4uPj+fzzz/nss8/ImTMn+/fvJ3fu3EmHa2jBkSNHePjhh6lQoQLh4eGEh4dz+vRp9u/fn/R8OXLkYMaMGXz55ZecO3eO0aNHX/Fzt2jRglKlSlG2bFl69+7NZ599xtmzZzP7SxYRyVDZbBcgIuJPdu/eTWRkJImJiezbt4/q1atTtGhRtm7dmnSffPnyAdCvXz+OHj3K6NGjKVWqFEFBQTRs2JC4uLgUz7lu3TrArCxw/PhxcuXKddnPHRoayi+//MKqVatYunQpL730EsOGDWPjxo3kyZMnU75eEZGMpmEDIiJZJC4ujptuuomaNWty44038t5777F9+3YKFy582fuHhoYybtw4evfuDcCBAwcoWbIko0aNSpqE9c8//1CzZk3ef/99Pv/8c86fP8+KFSsICDBvrCUfNnCxM2fOkCdPHubMmUPnzp0z5WsWEclo6nkVEckiQ4cOJTo6mvfff5/cuXPz3Xffcf/997Nw4cLL3v+GG25g+vTp1K1bl5iYGJ5++mmCg4OTbk9ISKB37960bNmSe++9l9atW1OtWjVGjhzJ008/fcnzLVy4kN27d3PbbbeRN29evv32WxITE6lYsWKmfc0iIhlNY15FRLLAqlWrGD16NNOnTycsLIyAgACmT5/O2rVrGT9+/GUf8+mnn3LixAlq1apF7969efzxxylUqFDS7W+88QZ79+7lo48+AiAiIoKPP/6YF154IcUwBJc8efLw1Vdf0axZMypVqsSECROYNWsWVapUyZSvWUQkM2jYgIiIiIh4DfW8ioiIiIjXUHgVEREREa+h8CoiIiIiXkPhVURERES8hsKriIiIiHgNhVcRERER8RoKryIiIiLiNRReRURERMRrKLyKiIiIiNdQeBURERERr6HwKiIiIiJe4/8AREhVHVRActsAAAAASUVORK5CYII=",
"text/plain": [
" \n",
"\n",
"
\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "pU2uVb4RIObo"
},
"source": [
"## Task 2.7: Finding Peaks in Daily Increase"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Wo2FuuQoISZu"
},
"source": [
"Our last task is to implement `is_peak`. This function takes `n_cases_increase_avg` and `n_adj_entries_peak` as arguments, and **determines whether the $(j + 1)$-th day was a day when the increase in cases peaked in the $i$th country**.\n",
"\n",
"In this case, `n_cases_increase_avg` is given by `average_increase_in_cases(n_cases_increase, n_adj_entries_avg)`.\n",
"\n",
"Suppose `a` is the average daily increase in cases, with the $(i, j)$ entry indicating the **average increase** in cases on the $(j + 1)$-th day in the $i$-th country. Moreover, let `n_adj_entries_peak` be denoted by `m`.\n",
"\n",
"In addition, an increase on the $(j + 1)$-th day is deemed *significant* in the $i$-th country if `a[i, j]` is greater than 10 percent of the mean of all **average daily increases** in the country. `np.nan` is, as the name suggests, not a number and cannot contribute to the mean. Therefore, if we have the set $\\{2, 3, `np.nan`\\}$, the mean should be $(2 + 3) / 2 = 2.5$.\n",
"\n",
"Now, to determine whether there is a *peak* on the $(j + 1)$-th day in the $i$-th country, check whether `a[i, j]` is *maximum* in`(a[i, j - m], a[i, j - m + 1], ..., a[i, j + m - 1], a[i, j + m])`. \n",
"\n",
"In the event that there are non-unique values such that there exists some value `a[i, k] = a[i, j]`, where $k \\neq j$ and $j - m \\leq k \\leq j + m$, we consider `a[i, j]` a maximum if and only if $k > j$. For example, in $(5, 10, 10)$, 10 is considered a maximum (since the second 10 appears to the right of the value 10 in the middle); but in $(10, 10, 5)$, 10 is not considered a maximum (since there exists another 10 to the left of the value in the middle).\n",
"\n",
"Then, **if `a[i, j]` is maximum and significant, then there is a peak on the $(j + 1)$-th day in the ith country; otherwise, there is no peak.**\n",
"\n",
"In this case, the return value of this function should be a 2D `np.ndarray` with the $(i, j)$ entry indicating whether there is a peak in the daily increase in cases on the $(j + 1)$-th day in the $i$th country.\n",
"\n",
"While imperfect, this approach gives a pretty decent result especially with the default value of 7 for `n_adj_entries_avg` and `n_adj_entries_peak`, as shown in figure below.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "pU2uVb4RIObo"
},
"source": [
"## Task 2.7: Finding Peaks in Daily Increase"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Wo2FuuQoISZu"
},
"source": [
"Our last task is to implement `is_peak`. This function takes `n_cases_increase_avg` and `n_adj_entries_peak` as arguments, and **determines whether the $(j + 1)$-th day was a day when the increase in cases peaked in the $i$th country**.\n",
"\n",
"In this case, `n_cases_increase_avg` is given by `average_increase_in_cases(n_cases_increase, n_adj_entries_avg)`.\n",
"\n",
"Suppose `a` is the average daily increase in cases, with the $(i, j)$ entry indicating the **average increase** in cases on the $(j + 1)$-th day in the $i$-th country. Moreover, let `n_adj_entries_peak` be denoted by `m`.\n",
"\n",
"In addition, an increase on the $(j + 1)$-th day is deemed *significant* in the $i$-th country if `a[i, j]` is greater than 10 percent of the mean of all **average daily increases** in the country. `np.nan` is, as the name suggests, not a number and cannot contribute to the mean. Therefore, if we have the set $\\{2, 3, `np.nan`\\}$, the mean should be $(2 + 3) / 2 = 2.5$.\n",
"\n",
"Now, to determine whether there is a *peak* on the $(j + 1)$-th day in the $i$-th country, check whether `a[i, j]` is *maximum* in`(a[i, j - m], a[i, j - m + 1], ..., a[i, j + m - 1], a[i, j + m])`. \n",
"\n",
"In the event that there are non-unique values such that there exists some value `a[i, k] = a[i, j]`, where $k \\neq j$ and $j - m \\leq k \\leq j + m$, we consider `a[i, j]` a maximum if and only if $k > j$. For example, in $(5, 10, 10)$, 10 is considered a maximum (since the second 10 appears to the right of the value 10 in the middle); but in $(10, 10, 5)$, 10 is not considered a maximum (since there exists another 10 to the left of the value in the middle).\n",
"\n",
"Then, **if `a[i, j]` is maximum and significant, then there is a peak on the $(j + 1)$-th day in the ith country; otherwise, there is no peak.**\n",
"\n",
"In this case, the return value of this function should be a 2D `np.ndarray` with the $(i, j)$ entry indicating whether there is a peak in the daily increase in cases on the $(j + 1)$-th day in the $i$th country.\n",
"\n",
"While imperfect, this approach gives a pretty decent result especially with the default value of 7 for `n_adj_entries_avg` and `n_adj_entries_peak`, as shown in figure below.\n",
"\n",
"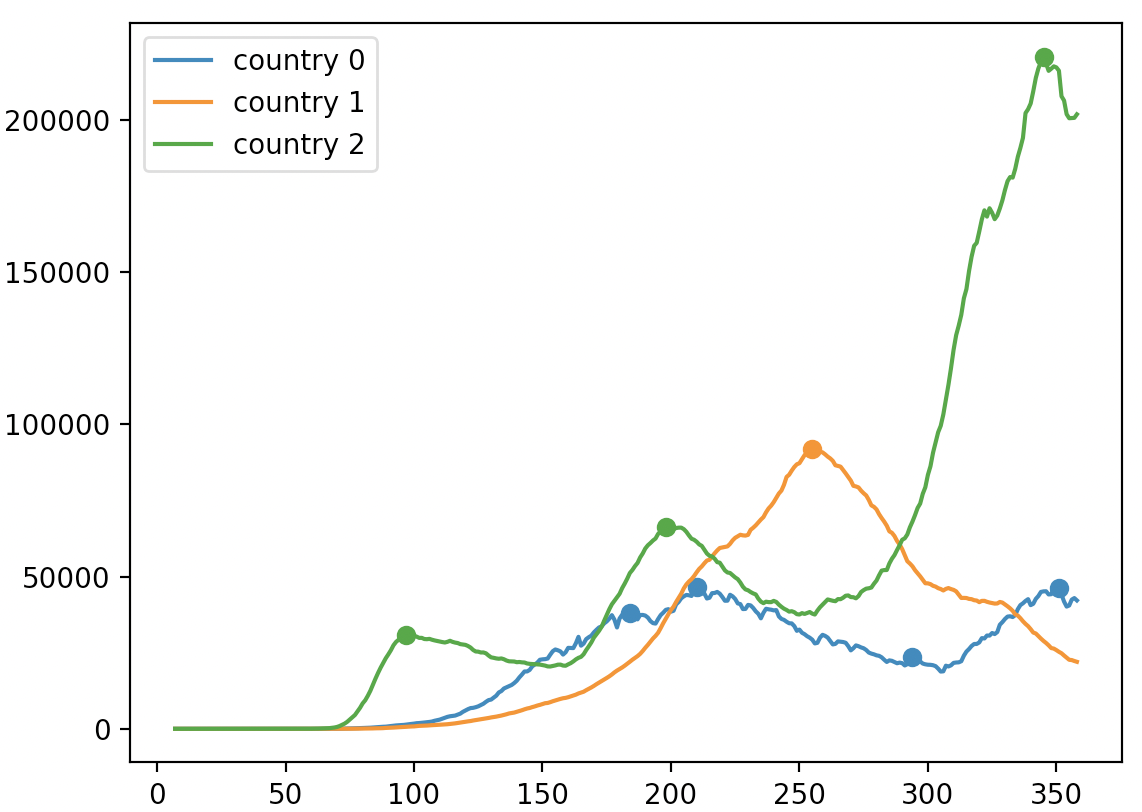 \n",
"\n",
"**Note:** In this task, you may use some of the Numpy functions that you have learned earlier, including `np.lib.stride_tricks.sliding_window_view`. In addition, you may benefit from using the following additional functions:\n",
"- [`numpy.count_nonzero`](https://numpy.org/doc/stable/reference/generated/numpy.count_nonzero.html): This function (recursively) counts how many elements in an array (and in sub-arrays thereof) that have non-zero values.\n",
"- [`numpy.isnan`](https://numpy.org/doc/stable/reference/generated/numpy.isnan.html): Test element-wise for NaN and return result as a boolean array.\n",
"- [`numpy.nanmean`](https://numpy.org/doc/stable/reference/generated/numpy.nanmean.html): Compute the arithmetic mean along the specified axis, ignoring NaNs. Returns the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. \n",
"\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"The basic usage of these functions is given below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[0, 1, 7, 0], [3, 0, 2, 19]])\n",
"print(np.count_nonzero(a)) # 5\n",
"\n",
"a = np.array([1, 2, np.nan])\n",
"print(np.isnan(a)) # [False, False, True]\n",
"\n",
"a = np.array([[1, np.nan], [3, 5]])\n",
"print(np.nanmean(a)) # 3.0"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2noFaxZLIB1I"
},
"outputs": [],
"source": [
"def is_peak(n_cases_increase_avg, n_adj_entries_peak=7):\n",
" '''\n",
" Determines whether the (j + 1)th day was a day when the increase in cases\n",
" peaked in the ith country.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase_avg: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the average daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the average daily increase in the number of confirmed\n",
" cases on the (j + 1)th day in the ith country. In this case, the 'average'\n",
" is computed using the output from `average_increase_in_cases`.\n",
" n_adj_entries_peak: int\n",
" Number of days that determines the size of the window in which peaks are\n",
" to be detected. \n",
" \n",
" Returns\n",
" -------\n",
" 2D `ndarray` with the (i, j) entry indicating whether there is a peak in the\n",
" daily increase in cases on the (j + 1)th day in the ith country.\n",
" Suppose `a` is the average daily increase in cases, with the (i, j) entry\n",
" indicating the average increase in cases on the (j + 1)th day in the ith\n",
" country. Moreover, let `n_adj_entries_peak` be denoted by `m`.\n",
" In addition, an increase on the (j + 1)th day is deemed significant in the\n",
" ith country if `a[i, j]` is greater than 10 percent of the mean of all\n",
" average daily increases in the country.\n",
" Now, to determine whether there is a peak on the (j + 1)th day in the ith\n",
" country, check whether `a[i, j]` is maximum in {`a[i, j - m]`, `a[i, j - m + 1]`,\n",
" ..., `a[i, j + m - 1]`, `a[i, j + m]`}. If it is and `a[i, j]` is significant,\n",
" then there is a peak on the (j + 1)th day in the ith country; otherwise,\n",
" there is no peak.\n",
" Note\n",
" ----\n",
" Let d = `n_adj_entries_avg` + `n_adj_entries_peak`, where `n_adj_entries_avg`\n",
" is that used to compute `n_cases_increase_avg`. Observe that it is not\n",
" possible to detect a peak in the first and last d days, i.e. these days should\n",
" not be peaks.\n",
" \n",
" As described in `average_increase_in_cases`, to compute the average daily\n",
" increase, we need data from the previous and the next `n_adj_entries_avg`\n",
" number of days. Hence, we won't have an average for these days, precluding\n",
" the computation of peaks during the first and last `n_adj_entries_avg` days.\n",
" Moreover, similar to `average_increase_in_cases`, we need the data over the\n",
" interval [-`n_adj_entries_peak` + j, `n_adj_entries_peak` + j] to determine\n",
" whether the (j + 1)th day is a peak.\n",
" Hint: to determine `n_adj_entries_avg` from `n_cases_increase_avg`,\n",
" `np.count_nonzero` and `np.isnan` may be helpful.\n",
"\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
"\n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.7\n",
"\n",
"n_cases_increase_avg = np.array([[np.nan, np.nan, 10, 10, 5, 20, 7, np.nan, np.nan], [np.nan, np.nan, 15, 5, 16, 17, 17, np.nan, np.nan]])\n",
"n_adj_entries_peak = 1\n",
"\n",
"actual = is_peak(n_cases_increase_avg, n_adj_entries_peak=n_adj_entries_peak)\n",
"expected = np.array([[False, False, False, False, False, True, False, False, False],\n",
" [False, False, False, False, False, True, False, False, False]])\n",
"assert np.all(actual == expected)\n",
"\n",
"n_cases_increase_avg2 = np.array([[np.nan, np.nan, 10, 20, 20, 20, 20, np.nan, np.nan], [np.nan, np.nan, 20, 20, 20, 20, 10, np.nan, np.nan]])\n",
"n_adj_entries_peak2 = 1\n",
"\n",
"actual2 = is_peak(n_cases_increase_avg2, n_adj_entries_peak=n_adj_entries_peak2)\n",
"expected2 = np.array([[False, False, False, True, False, False, False, False, False],\n",
" [False, False, False, False, False, False, False, False, False]])\n",
"assert np.all(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Explanation of the example test case\n",
"\n",
"Below is the process on how the function should compute the above example test case.\n",
"\n",
"Consider:\n",
"- `n_cases_increase_avg = np.array([[np.nan, np.nan, 10, 10, 5, 20, 7, np.nan, np.nan], [np.nan, np.nan, 15, 5, 16, 17, 17, np.nan, np.nan]])`\n",
"- `n_adj_entries_peak = 1`\n",
"\n",
"Let's get the solution for this instance of `is_peak` function parameter values.\n",
"\n",
"1. Work with only the non-nan portion of the n_cases_increase_avg array -> [[10, 10, 5, 20, 7], [15, 5, 16, 17, 17]]\n",
"2. First, we check for max for each window of size 3 (1 left, middle, 1 right) -> 1 is the value of `n_adj_entries_peak`\n",
" * We have to look at the following windows for country 1:\n",
" 1. [10, 10, 5] for 10: False as there is an equal max element to its left in the window\n",
" 2. [10, 5, 20] for 5: False as it is not max\n",
" 3. [5, 20, 7] for 20: True as it is max\n",
" \n",
" So, for country 1, the max checking boolean result is: [False, False, True]\n",
"\n",
" * We have to look at the following windows for country 2: \n",
" 1. [15, 5, 16] for 5: False as it is not max\n",
" 2. [5, 16, 17] for 16: False as it is not max\n",
" 3. [16, 17, 17] for 17: True as it is max and the equal element is on its right side in the window. \n",
" \n",
" So, for country 2, the max checking boolean result is: [False, False, True]\n",
" \n",
" * So, final result for max checking is: [[False, False, True], [False, False, True]]\n",
"\n",
"\n",
"3. Now, we check for significance -> whether an element of interest is greater than 10% of the mean of avg daily increases in a country\n",
" - For country 1,\n",
" - The threshold value is: ((10 + 10 + 5 + 20 + 7) / 5) * 0.1 = 1.04\n",
" - 10, 5 and 20 -> all are greater than this value. \n",
" - So, the significance checking boolean result for country 1 is: [True, True, True]\n",
" - For country 2,\n",
" - The threshold value is: ((15 + 5 + 16 + 17 + 17) / 5) * 0.1 = 1.40\n",
" - 5, 16, 17 -> all are greater than this value. \n",
" - So, the significance checking boolean result for country 2 is: [True, True, True]\n",
" \n",
" - So, final result for significance checking is: [[True, True, True], [True, True, True]]\n",
"\n",
"4. The condition for being a peak is to satisfy both the max and the significance criteria.\n",
"So, we now have \"and\" the final resultant boolean arrays for max and significance checking that we derived a while ago\n",
"The result we get after the operation is: [[False, False, True], [False, False, True]]\n",
"\n",
"5. So, is it done? \n",
"Not yet. Our final result should have the same shape as the n_cases_increase_avg array, which in this\n",
"case is 2 X 9. But the result we have currently is of shape 2 X 3.\n",
"So, for each of the 2 rows, we have to pad with 6 False values; 3 on the left and 3 on the right which results in:\n",
"[[False, False, False, False, False, True, False, False, False], \n",
" [False, False, False, False, False, True, False, False, False]]\n",
" \n",
"6. At last! We got our final answer"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Visualising the peaks\n",
"\n",
"The peaks in daily increase can be highlighted on the graph using our helper function `visualise_peaks`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def visualise_peaks(n_cases_increase_avg, peaks):\n",
" '''\n",
" Visualises peaks for each of the country that is represented in\n",
" `n_cases_increase_avg` according to variable `peaks`.\n",
" \n",
" NOTE: If there are more than 5 countries, only the plots for the first 5\n",
" countries will be shown.\n",
" '''\n",
" days = np.arange(1, n_cases_increase_avg.shape[1] + 1) # Days will be our x-coordinates\n",
"\n",
" plt.figure() # Start a graph\n",
" \n",
" for i in range(min(5, n_cases_increase_avg.shape[0])): # A curve for each row (country) \n",
" plt.plot(days, n_cases_increase_avg[i, :], label='country {}'.format(i)) # Plot the daily increase curve\n",
" peak = (np.nonzero(peaks[i, :]))[0]\n",
" peak_days = peak + 1 # since data starts from day 1, not 0\n",
" plt.scatter(peak_days, n_cases_increase_avg[i, peak]) # Scatterplot of peak(s) that lay on top of the curve\n",
" \n",
" plt.legend()\n",
" plt.show() # Display graph"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To view the results of your solution, you can use `visualise_peaks` as follows."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Visualise the results on the test case\n",
"visualise_peaks(n_cases_increase_avg, is_peak(n_cases_increase_avg, n_adj_entries_peak=n_adj_entries_peak))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gv3IzLY8ISfY"
},
"source": [
"# Submission"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kIPn-5PNJ8k5"
},
"source": [
"Once you are done, please submit your work to Coursemology, by copying the right snippets of code into the corresponding box that says 'Your answer', and click 'Save'. After you save, you can make changes to your\n",
"submission.\n",
"\n",
"Once you are satisfied with what you have uploaded, click 'Finalize submission.' **Note that once your submission is finalized, it is considered to be submitted for grading and cannot be changed**. If you need to undo\n",
"this action, you will have to email your assigned tutor for help. Please do not finalize your submission until you are sure that you want to submit your solutions for grading. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Appendix"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Below is a non-exhaustive list of NumPy functions allowed and now allowed: "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Allowed functions:\n",
"\n",
"numpy.all\n",
"numpy.any\n",
"numpy.append\n",
"numpy.arange\n",
"numpy.argmax\n",
"numpy.compress\n",
"numpy.concatenate\n",
"numpy.cumsum\n",
"numpy.diff\n",
"numpy.divide\n",
"numpy.einsum\n",
"numpy.equal\n",
"numpy.full\n",
"numpy.greater\n",
"numpy.greater_equal\n",
"numpy.hstack\n",
"numpy.insert\n",
"numpy.lib.stride_tricks\n",
"numpy.logical_and\n",
"numpy.logical_not\n",
"numpy.ndarray.flatten\n",
"numpy.ndarray.reshape \n",
"numpy.newaxis\n",
"numpy.ones\n",
"numpy.pad\n",
"numpy.shape\n",
"numpy.squeeze\n",
"numpy.take\n",
"np.ufunc.reduce\n",
"numpy.where\n",
"numpy.zeros\n",
"numpy.zeros_like\n",
"\n",
"# Plus all functions mentioned in NumPy Basics\n",
"\n",
"# Not allowed:\n",
"\n",
"numpy.apply_along_axis\n",
"numpy.apply_over_axes\n",
"numpy.vectorize"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"name": "ps0.ipynb",
"provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.9"
},
"vscode": {
"interpreter": {
"hash": "b1bf6cc60825bc0168f0daef984b080cea2a9fe0c964c898af2495b9f96ac9e2"
}
}
},
"nbformat": 4,
"nbformat_minor": 1
}
\n",
"\n",
"**Note:** In this task, you may use some of the Numpy functions that you have learned earlier, including `np.lib.stride_tricks.sliding_window_view`. In addition, you may benefit from using the following additional functions:\n",
"- [`numpy.count_nonzero`](https://numpy.org/doc/stable/reference/generated/numpy.count_nonzero.html): This function (recursively) counts how many elements in an array (and in sub-arrays thereof) that have non-zero values.\n",
"- [`numpy.isnan`](https://numpy.org/doc/stable/reference/generated/numpy.isnan.html): Test element-wise for NaN and return result as a boolean array.\n",
"- [`numpy.nanmean`](https://numpy.org/doc/stable/reference/generated/numpy.nanmean.html): Compute the arithmetic mean along the specified axis, ignoring NaNs. Returns the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. \n",
"\n",
"Your implementation should not involve any iteration, including `map` and `filter`, recursion, or any iterative approaches like for-loops.\n",
"\n",
"The basic usage of these functions is given below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"\n",
"a = np.array([[0, 1, 7, 0], [3, 0, 2, 19]])\n",
"print(np.count_nonzero(a)) # 5\n",
"\n",
"a = np.array([1, 2, np.nan])\n",
"print(np.isnan(a)) # [False, False, True]\n",
"\n",
"a = np.array([[1, np.nan], [3, 5]])\n",
"print(np.nanmean(a)) # 3.0"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2noFaxZLIB1I"
},
"outputs": [],
"source": [
"def is_peak(n_cases_increase_avg, n_adj_entries_peak=7):\n",
" '''\n",
" Determines whether the (j + 1)th day was a day when the increase in cases\n",
" peaked in the ith country.\n",
" Parameters\n",
" ----------\n",
" n_cases_increase_avg: np.ndarray\n",
" 2D `ndarray` with each row representing the data of a country, and the columns\n",
" of each row representing the time series data of the average daily increase in the\n",
" number of confirmed cases in that country, i.e. the ith row of \n",
" `n_cases_increase` contains the data of the ith country, and the (i, j) entry of\n",
" `n_cases_increase` is the average daily increase in the number of confirmed\n",
" cases on the (j + 1)th day in the ith country. In this case, the 'average'\n",
" is computed using the output from `average_increase_in_cases`.\n",
" n_adj_entries_peak: int\n",
" Number of days that determines the size of the window in which peaks are\n",
" to be detected. \n",
" \n",
" Returns\n",
" -------\n",
" 2D `ndarray` with the (i, j) entry indicating whether there is a peak in the\n",
" daily increase in cases on the (j + 1)th day in the ith country.\n",
" Suppose `a` is the average daily increase in cases, with the (i, j) entry\n",
" indicating the average increase in cases on the (j + 1)th day in the ith\n",
" country. Moreover, let `n_adj_entries_peak` be denoted by `m`.\n",
" In addition, an increase on the (j + 1)th day is deemed significant in the\n",
" ith country if `a[i, j]` is greater than 10 percent of the mean of all\n",
" average daily increases in the country.\n",
" Now, to determine whether there is a peak on the (j + 1)th day in the ith\n",
" country, check whether `a[i, j]` is maximum in {`a[i, j - m]`, `a[i, j - m + 1]`,\n",
" ..., `a[i, j + m - 1]`, `a[i, j + m]`}. If it is and `a[i, j]` is significant,\n",
" then there is a peak on the (j + 1)th day in the ith country; otherwise,\n",
" there is no peak.\n",
" Note\n",
" ----\n",
" Let d = `n_adj_entries_avg` + `n_adj_entries_peak`, where `n_adj_entries_avg`\n",
" is that used to compute `n_cases_increase_avg`. Observe that it is not\n",
" possible to detect a peak in the first and last d days, i.e. these days should\n",
" not be peaks.\n",
" \n",
" As described in `average_increase_in_cases`, to compute the average daily\n",
" increase, we need data from the previous and the next `n_adj_entries_avg`\n",
" number of days. Hence, we won't have an average for these days, precluding\n",
" the computation of peaks during the first and last `n_adj_entries_avg` days.\n",
" Moreover, similar to `average_increase_in_cases`, we need the data over the\n",
" interval [-`n_adj_entries_peak` + j, `n_adj_entries_peak` + j] to determine\n",
" whether the (j + 1)th day is a peak.\n",
" Hint: to determine `n_adj_entries_avg` from `n_cases_increase_avg`,\n",
" `np.count_nonzero` and `np.isnan` may be helpful.\n",
"\n",
" Your implementation should not involve any iteration, including `map` and `filter`, \n",
" recursion, or any iterative approaches like for-loops.\n",
" '''\n",
"\n",
" # TODO: add your solution here and remove `raise NotImplementedError`\n",
" raise NotImplementedError"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Test case for Task 2.7\n",
"\n",
"n_cases_increase_avg = np.array([[np.nan, np.nan, 10, 10, 5, 20, 7, np.nan, np.nan], [np.nan, np.nan, 15, 5, 16, 17, 17, np.nan, np.nan]])\n",
"n_adj_entries_peak = 1\n",
"\n",
"actual = is_peak(n_cases_increase_avg, n_adj_entries_peak=n_adj_entries_peak)\n",
"expected = np.array([[False, False, False, False, False, True, False, False, False],\n",
" [False, False, False, False, False, True, False, False, False]])\n",
"assert np.all(actual == expected)\n",
"\n",
"n_cases_increase_avg2 = np.array([[np.nan, np.nan, 10, 20, 20, 20, 20, np.nan, np.nan], [np.nan, np.nan, 20, 20, 20, 20, 10, np.nan, np.nan]])\n",
"n_adj_entries_peak2 = 1\n",
"\n",
"actual2 = is_peak(n_cases_increase_avg2, n_adj_entries_peak=n_adj_entries_peak2)\n",
"expected2 = np.array([[False, False, False, True, False, False, False, False, False],\n",
" [False, False, False, False, False, False, False, False, False]])\n",
"assert np.all(actual2 == expected2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Explanation of the example test case\n",
"\n",
"Below is the process on how the function should compute the above example test case.\n",
"\n",
"Consider:\n",
"- `n_cases_increase_avg = np.array([[np.nan, np.nan, 10, 10, 5, 20, 7, np.nan, np.nan], [np.nan, np.nan, 15, 5, 16, 17, 17, np.nan, np.nan]])`\n",
"- `n_adj_entries_peak = 1`\n",
"\n",
"Let's get the solution for this instance of `is_peak` function parameter values.\n",
"\n",
"1. Work with only the non-nan portion of the n_cases_increase_avg array -> [[10, 10, 5, 20, 7], [15, 5, 16, 17, 17]]\n",
"2. First, we check for max for each window of size 3 (1 left, middle, 1 right) -> 1 is the value of `n_adj_entries_peak`\n",
" * We have to look at the following windows for country 1:\n",
" 1. [10, 10, 5] for 10: False as there is an equal max element to its left in the window\n",
" 2. [10, 5, 20] for 5: False as it is not max\n",
" 3. [5, 20, 7] for 20: True as it is max\n",
" \n",
" So, for country 1, the max checking boolean result is: [False, False, True]\n",
"\n",
" * We have to look at the following windows for country 2: \n",
" 1. [15, 5, 16] for 5: False as it is not max\n",
" 2. [5, 16, 17] for 16: False as it is not max\n",
" 3. [16, 17, 17] for 17: True as it is max and the equal element is on its right side in the window. \n",
" \n",
" So, for country 2, the max checking boolean result is: [False, False, True]\n",
" \n",
" * So, final result for max checking is: [[False, False, True], [False, False, True]]\n",
"\n",
"\n",
"3. Now, we check for significance -> whether an element of interest is greater than 10% of the mean of avg daily increases in a country\n",
" - For country 1,\n",
" - The threshold value is: ((10 + 10 + 5 + 20 + 7) / 5) * 0.1 = 1.04\n",
" - 10, 5 and 20 -> all are greater than this value. \n",
" - So, the significance checking boolean result for country 1 is: [True, True, True]\n",
" - For country 2,\n",
" - The threshold value is: ((15 + 5 + 16 + 17 + 17) / 5) * 0.1 = 1.40\n",
" - 5, 16, 17 -> all are greater than this value. \n",
" - So, the significance checking boolean result for country 2 is: [True, True, True]\n",
" \n",
" - So, final result for significance checking is: [[True, True, True], [True, True, True]]\n",
"\n",
"4. The condition for being a peak is to satisfy both the max and the significance criteria.\n",
"So, we now have \"and\" the final resultant boolean arrays for max and significance checking that we derived a while ago\n",
"The result we get after the operation is: [[False, False, True], [False, False, True]]\n",
"\n",
"5. So, is it done? \n",
"Not yet. Our final result should have the same shape as the n_cases_increase_avg array, which in this\n",
"case is 2 X 9. But the result we have currently is of shape 2 X 3.\n",
"So, for each of the 2 rows, we have to pad with 6 False values; 3 on the left and 3 on the right which results in:\n",
"[[False, False, False, False, False, True, False, False, False], \n",
" [False, False, False, False, False, True, False, False, False]]\n",
" \n",
"6. At last! We got our final answer"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Visualising the peaks\n",
"\n",
"The peaks in daily increase can be highlighted on the graph using our helper function `visualise_peaks`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def visualise_peaks(n_cases_increase_avg, peaks):\n",
" '''\n",
" Visualises peaks for each of the country that is represented in\n",
" `n_cases_increase_avg` according to variable `peaks`.\n",
" \n",
" NOTE: If there are more than 5 countries, only the plots for the first 5\n",
" countries will be shown.\n",
" '''\n",
" days = np.arange(1, n_cases_increase_avg.shape[1] + 1) # Days will be our x-coordinates\n",
"\n",
" plt.figure() # Start a graph\n",
" \n",
" for i in range(min(5, n_cases_increase_avg.shape[0])): # A curve for each row (country) \n",
" plt.plot(days, n_cases_increase_avg[i, :], label='country {}'.format(i)) # Plot the daily increase curve\n",
" peak = (np.nonzero(peaks[i, :]))[0]\n",
" peak_days = peak + 1 # since data starts from day 1, not 0\n",
" plt.scatter(peak_days, n_cases_increase_avg[i, peak]) # Scatterplot of peak(s) that lay on top of the curve\n",
" \n",
" plt.legend()\n",
" plt.show() # Display graph"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To view the results of your solution, you can use `visualise_peaks` as follows."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Visualise the results on the test case\n",
"visualise_peaks(n_cases_increase_avg, is_peak(n_cases_increase_avg, n_adj_entries_peak=n_adj_entries_peak))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gv3IzLY8ISfY"
},
"source": [
"# Submission"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kIPn-5PNJ8k5"
},
"source": [
"Once you are done, please submit your work to Coursemology, by copying the right snippets of code into the corresponding box that says 'Your answer', and click 'Save'. After you save, you can make changes to your\n",
"submission.\n",
"\n",
"Once you are satisfied with what you have uploaded, click 'Finalize submission.' **Note that once your submission is finalized, it is considered to be submitted for grading and cannot be changed**. If you need to undo\n",
"this action, you will have to email your assigned tutor for help. Please do not finalize your submission until you are sure that you want to submit your solutions for grading. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Appendix"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Below is a non-exhaustive list of NumPy functions allowed and now allowed: "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Allowed functions:\n",
"\n",
"numpy.all\n",
"numpy.any\n",
"numpy.append\n",
"numpy.arange\n",
"numpy.argmax\n",
"numpy.compress\n",
"numpy.concatenate\n",
"numpy.cumsum\n",
"numpy.diff\n",
"numpy.divide\n",
"numpy.einsum\n",
"numpy.equal\n",
"numpy.full\n",
"numpy.greater\n",
"numpy.greater_equal\n",
"numpy.hstack\n",
"numpy.insert\n",
"numpy.lib.stride_tricks\n",
"numpy.logical_and\n",
"numpy.logical_not\n",
"numpy.ndarray.flatten\n",
"numpy.ndarray.reshape \n",
"numpy.newaxis\n",
"numpy.ones\n",
"numpy.pad\n",
"numpy.shape\n",
"numpy.squeeze\n",
"numpy.take\n",
"np.ufunc.reduce\n",
"numpy.where\n",
"numpy.zeros\n",
"numpy.zeros_like\n",
"\n",
"# Plus all functions mentioned in NumPy Basics\n",
"\n",
"# Not allowed:\n",
"\n",
"numpy.apply_along_axis\n",
"numpy.apply_over_axes\n",
"numpy.vectorize"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"name": "ps0.ipynb",
"provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.9"
},
"vscode": {
"interpreter": {
"hash": "b1bf6cc60825bc0168f0daef984b080cea2a9fe0c964c898af2495b9f96ac9e2"
}
}
},
"nbformat": 4,
"nbformat_minor": 1
}